
Abstract
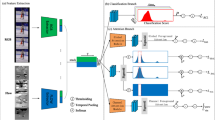
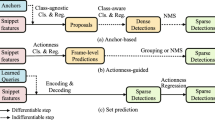
This paper proposes a novel approach of learning weighted video segments via supervised temporal attention for action localization in untrimmed videos. The learned segment weights represent informativeness of video segments to recognize actions and benefit inferring the boundaries to temporally localize actions. We build a Supervised Temporal Attention Network (STAN) to dynamically learn the weights of video segments, and generate descriptive and discriminative video representations. We use a proposal generator and a classifier to estimate the boundaries of actions and classify the classes of actions, respectively. Extensive experiments are conducted on two public benchmarks THUMOS2014 and ActivityNet1.3. The results demonstrate that our approach achieves substantially better performance than the state-of-the-art methods, verifying the effectiveness of learning weighted video segments.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Bodla, N., Singh, B., Chellappa, R., Davis, L.S.: Soft-NMS-improving object detection with one line of code. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 5561–5569 (2017)
Buch, S., Escorcia, V., Ghanem, B., Fei-Fei, L., Niebles, J.C.: End-to-end, single-stream temporal action detection in untrimmed videos. In: Proceedings of the British Machine Vision Conference (BMVC), vol. 1, p. 2 (2017)
Caba Heilbron, F., Carlos Niebles, J., Ghanem, B.: Fast temporal activity proposals for efficient detection of human actions in untrimmed videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1914–1923 (2016)
Chao, Y.W., Vijayanarasimhan, S., Seybold, B., Ross, D.A., Deng, J., Sukthankar, R.: Rethinking the faster R-CNN architecture for temporal action localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1130–1139 (2018)
Dai, X., Singh, B., Zhang, G., Davis, L.S., Chen, Y.Q.: Temporal context network for activity localization in videos. In: 2017 IEEE International Conference on Computer Vision (ICCV), pp. 5727–5736. IEEE (2017)
Das, A., Agrawal, H., Zitnick, L., Parikh, D., Batra, D.: Human attention in visual question answering: do humans and deep networks look at the same regions? Comput. Vis. Image Underst. 163, 90–100 (2017)
Caba Heilbron, F., Escorcia, V., Ghanem, B., Niebles, J.C.: Activitynet: a large-scale video benchmark for human activity understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 961–970 (2015)
Gao, J., Yang, Z., Nevatia, R.: Cascaded boundary regression for temporal action detection. In: British Machine Vision Conference (2017)
Girshick, R.: Fast R-CNN. In: IEEE International Conference on Computer Vision, pp. 1440–1448 (2015)
Jiang, Y.G., et al.: THUMOS challenge: action recognition with a large number of classes (2014). http://crcv.ucf.edu/THUMOS14/
Karaman, S., Seidenari, L., Del Bimbo, A.: Fast saliency based pooling offisher encoded dense trajectories, vol. 1 (2014)
Kong, W., Li, N., Liu, S., Li, T., Li, G.: BLP-boundary likelihood pinpointing networks for accurate temporal action localization. arXiv preprint arXiv:1811.02189 (2018)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: Advances in Neural Information Processing Systems, pp. 1097–1105 (2012)
Lin, T., Zhao, X., Shou, Z.: Single shot temporal action detection. In: Proceedings of the 2017 ACM on Multimedia Conference, pp. 988–996. ACM (2017)
Lin, T., Zhao, X., Su, H., Wang, C., Yang, M.: BSN: boundary sensitive network for temporal action proposal generation. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 3–19 (2018)
Mnih, V., Heess, N., Graves, A., et al.: Recurrent models of visual attention. In: Advances in Neural Information Processing Systems, pp. 2204–2212 (2014)
Oneata, D., Verbeek, J., Schmid, C.: The LEAR submission at Thumos 2014. In: Computer Vision and Pattern Recognition [cs.CV] (2014)
Qin, Y., Song, D., Chen, H., Cheng, W., Jiang, G., Cottrell, G.W.: A dual-stage attention-based recurrent neural network for time series prediction. In: Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, 19–25 August 2017, pp. 2627–2633 (2017)
Qiu, H., Zheng, Y., Ye, H., Lu, Y., Wang, F., He, L.: Precise temporal action localization by evolving temporal proposals. In: Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, pp. 388–396. ACM (2018)
Shou, Z., Chan, J., Zareian, A., Miyazawa, K., Chang, S.F.: CDC: convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1417–1426. IEEE (2017)
Shou, Z., Wang, D., Chang, S.F.: Temporal action localization in untrimmed videos via multi-stage CNNs. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1049–1058 (2016)
Singh, G., Cuzzolin, F.: Untrimmed video classification for activity detection: submission to activitynet challenge. arXiv preprint arXiv:1607.01979 (2016)
Tran, D., Bourdev, L., Fergus, R., Torresani, L., Paluri, M.: Learning spatiotemporal features with 3D convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 4489–4497 (2015)
Wang, L., Qiao, Y., Tang, X.: Action recognition and detection by combining motion and appearance features. THUMOS14 Action Recogn. Challenge 1, 2 (2014)
Wang, L., et al.: Temporal segment networks: towards good practices for deep action recognition. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 20–36. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_2
Xu, H., Das, A., Saenko, K.: R-C3D: region convolutional 3D network for temporal activity detection. In: The IEEE International Conference on Computer Vision (ICCV), vol. 6, p. 8 (2017)
Zhao, Y., Xiong, Y., Wang, L., Wu, Z., Lin, D., Tang, X.: Temporal action detection with structured segment networks. arXiv preprint arXiv:1704.06228 (2017)
Acknowledgements
This work was supported in part by the Natural Science Foundation of China (NSFC) under grants No. 61673062.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Sun, C., Song, H., Wu, X., Jia, Y. (2019). Learning Weighted Video Segments for Temporal Action Localization. In: Lin, Z., et al. Pattern Recognition and Computer Vision. PRCV 2019. Lecture Notes in Computer Science(), vol 11857. Springer, Cham. https://doi.org/10.1007/978-3-030-31654-9_16
Download citation
DOI: https://doi.org/10.1007/978-3-030-31654-9_16
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-31653-2
Online ISBN: 978-3-030-31654-9
eBook Packages: Computer ScienceComputer Science (R0)