
Abstract
Recent advances in machine learning for medical imaging have led to impressive increases in model complexity and overall capabilities. However, the ability to discern the precise information a machine learning method is using to make decisions has lagged behind and it is often unclear how these performances are in fact achieved. Conventional evaluation metrics that reduce method performance to a single number or a curve only provide limited insights. Yet, systems used in clinical practice demand thorough validation that such crude characterizations miss. To this end, we present a framework to evaluate classification methods based on a number of interpretable concepts that are crucial for a clinical task. Our approach is inspired by the Turing Test concept and how to devise a test that adaptively questions a method for its ability to interpret medical images. To do this, we make use of a Twenty Questions paradigm whereby we use a probabilistic model to characterize the method’s capacity to grasp task-specific concepts, and we introduce a strategy to sequentially query the method according to its previous answers. The results show that the probabilistic model is able to expose both the dataset’s and the method’s biases, and can be used to reduce the number of queries needed for confident performance evaluation.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


1 Introduction
The field of medical image computing (MIC) has radically changed with the emergence of large neural networks, or Deep Learning (DL). For MIC tasks that were long considered extremely challenging, such as image-based pathology classification and segmentation, DL methods have now reached human-level performances on a variety of benchmarks.
Yet, as these methods have become increasingly powerful, the overall methodology to validate them has largely remained intact. For instance, challenge competitions compare different methods on a common dataset by using metrics most often borrowed from the computer vision literature. As recently noted in [9], challenge competition rankings and outcomes are very often highly skewed to the dataset or metrics used, and rarely relate to the clinical task. To tackle this, recent developments in visual question answering (VQA) [1, 5, 8, 14] methods, which answer questions related to image content, show the ability to infer concepts beyond traditional classification. Here again, however, the metrics used to evaluate VQA’s remain inadequate.
Instead, we consider an alternative approach to validating MIC methods, one inspired by Alan Turing’s Turing Test concept [13], where a human unknowingly communicates either with another human or an Artificial Intelligence system that produces answers. The aim of the test is to distinguish between the two based on a set of asked questions. Turing tests have been used in medical imaging to evaluate the quality of adversarial attacks, by seeing if an expert can distinguish between a real and an adversarial example [3, 12]. Another approach, focusing on the interpretability of methods that infer semantic information from images (e.g. classification, segmentation etc.) is seen in the work of Geman et al. [4] on automated Visual Turing Tests (VTT). In their work, an algorithm adaptively selects images and questions to pose to a method under evaluation (MuE) such that the answers can not be predicted from the history of answers. While this approach has increased explanatory power, it is limited to manually fabricated story lines to guide questioning. This makes it ill suited for medical applications where such story lines are hard to formalize.

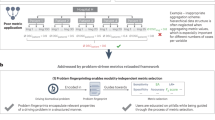
Visual Turing Test (VTT) fundus image screening. Green arrows correspond to selected questions, and orange lines to the answers given by the MuE. (Color figure online)
For this reason, we propose a novel VTT framework to evaluate MIC methods (see Fig. 1). In particular, our approach focuses on evaluating MIC classification methods and we present a framework that tests if the method has correctly understood the relevant medical concepts when inferring test data. We do this by formulating our problem as a Twenty Questions game [2, 7] in which we model the likelihood of a given MuE to provide correct answers for different concepts present in test images. Our framework then sequentially picks test images and concepts such that the uncertainty of this model is reduced as quickly as possible. We demonstrate our framework in the context of three different multi-label classification problems where each concept is encoded by a given binary label.
2 Method
Our proposed VTT framework evaluates how a MuE, a MIC classification method in this case, performs with respect to core concepts relevant to the task for which it was trained. To do this, we make use of a validation image dataset that the MuE has never had access to, \(\mathcal {D} = \{\mathbf {s}_i\}_{i=1}^{N_S}\), where \(\mathbf {s}_i\) is an available test sample, such as an image or an arbitrary region within an image. As such, \(N_S\) can be excessively large, as potentially millions of regions can be extracted from a single test image. For each \(\mathbf {s}_i\), we denote the potential concepts that could be present in the sample as, \(\mathcal {C} = \{c_j\}_{j=1}^{N_C}\). From this, we define a “question”, \(q = (\mathbf {s}_q, c_q) \in \mathcal {D} \times \mathcal {C} = \mathcal {Q}\), of the form “Is concept \(c_q\) present in sample \(\mathbf {s}_q\)?”. We let \(q_{gt} \in \{0,1\}\) be the true answer to question q. In this work, we consider MuEs that perform multi-label classification tasks, \(f: \mathcal {Q} \rightarrow [0,1]\), taking as input the question q and producing the probability of the answer being “Yes” (see Fig. 1).
Given that evaluating all elements of \(\mathcal {Q}\) may be computationally intractable, our VTT framework instead only evaluates a subset of \(\mathcal {Q}\). We do this iteratively and adaptively, where we use the history of previously asked questions and their answers to build a performance model (Sect. 2.1). We then use a questioning strategy to determine which element of \(\mathcal {Q}\) should be asked to the MuE. In particular, we propose a novel strategy that selects the element that maximally reduces the uncertainty in the performance model (Sect. 2.2). The process terminates after a fixed number of questions have been asked or when the uncertainty in the model has been reduced to an acceptable level. Figure 2 (Left) illustrates our framework and we detail our performance model and questioning strategy next.
2.1 Performance Model
From a set of questions and the corresponding MuE responses, we aim to model the MuE performance with respect to concepts \(\mathcal {C}\). While the relation between concepts could in practice be complex, we model them as independent here.

Left: Overview of the proposed scheme. Right: Examples of GPs for 3 different concepts (points are the observations, dotted line is the mean of a GP and the shaded area corresponds to the \(95\%\) confidence region).
By its definition, the MuE provides answers to binary questions, and for any concept, there are 4 possible outcomes to a question: a True Negative (TN), a False Positive (FP), a False Negative (FN) or a True Positive (TP). Our goal then is to model the relation between the frequency of these outcomes and the inputs to the MuE. To do this, we define a discrete random variable \(Y_c\) for every concept \(c \in \mathcal {C}\) which encodes the countsFootnote 1 of outcomes given by f. We achieve this by means of a Gaussian Process (GP) [11] of the form,
where \(\mu _c(\cdot )\) and \(k_c(\cdot ,\cdot )\) are the mean and kernel functions of the GP, respectively, and
describes the answer of f with respect to the question q. The mean function \(\mu _c\) is initialized to 0, and the covariance function (kernel) \(k_c\) is a squared exponential \(k_c (a_{c,m}, a_{c,n}) = \sigma _f \cdot e^{-\frac{1}{2l^2}(a_{c,m} - a_{c,n})^2} + \sigma _n \delta _{mn}\), with characteristic length-scale \(l=0.1\), initial signal variance \(\sigma _f=1\) and noise variance \(\sigma _n=0.025\).
To then infer the value of \(Y_c\) for any \(a_c\), we store the pairs \(\{(a^{(i)}_{c},y_{c}^{(i)})\}\) where \(y_{c}^{(i)}\) is the number of times f has given \(a=a^{(i)}_{c}\), and use these as observations to infer the complete model \(f_c^{\mathcal {GP}}\) using standard inference [11]. In practice, we discretized the range of a in bins of \(\varDelta a = 0.01\).
A consequence of this model is that we can now visualize the performance of f with respect to the concepts in \(\mathcal {C}\), the selected q’s and the dataset \(\mathcal {D}\). In Fig. 2 (Right), we illustrate \(f^{\mathcal {GP}}_c\) in terms of a for each c. Such a visualization depicts any bias that both f and the dataset \(\mathcal {D}\) may have (e. g., \(\mathcal {D}\) contains few samples regarding a specific concept). Note that by summing up the observations over concepts or integrating over the four different subregions of the support set, one retrieves the total TN, FP, FN and TP, and other subsequent metrics.

2.2 Questioning Strategy
With the performance model above and the fact that the validation dataset \(\mathcal {D}\) may be intractably larger, we now describe how to select samples from \(\mathcal {Q}\) to verify that the MuE has grasped relevant concepts.
To do this, we present a strategy that looks to select samples \(\mathbf {s}\) and concepts c that are likely to reduce our model’s uncertainty. We do this by computing the uncertainty of a concept as the integral of the \(95\%\) confidence region of the GP over its support set (i. e., 2 standard deviations). That is, for concept \(c \in C\),
which can be decomposed as \(u_c^- = 4\int _0^{0.5}{ k_c(a,a)da}\) and \(u_c^+ = 4\int _{0.5}^1{k_c(a,a)da}\), corresponding to the uncertainty associated with negative and positive samples in \(\mathcal {D}\), respectively. Visually this corresponds to the area over the intervals \(a = [0,0.5]\) and \(a=[0.5,1]\) (see Fig. 2, Right).
Our strategy then chooses which concept to ask, and whether to ask a sample that has or does not have this concept in it. This is performed by selecting
where \(o_{c_q} = 0\) if \(\max (u_c^- , u_c^+) = u_c^- \) or 1 if \(\max (u_c^-, u_c^+) = u_c^+\).
From this, \(q^*\) is selected either randomly, or based on its unpredictability. As in [4], the latter is computed using the same dataset \(\mathcal {D}\) and the history of already answered questions \(\mathcal {H}\). An overview of the questioning strategy can be seen in Algorithm 1.
3 Experiments and Results
We choose to evaluate our framework on multi-label classification tasks where concepts are directly linked to groundtruth labels. In the following, we outline the different datasets and MuEs we use, and our experimental setup.
3.1 Datasets and MuE
Indian Diabetic Retinopathy image Dataset (IDRiD) [10]: 143 fundus images from both healthy and diabetic retinopathy subjects, with the task of identifying 4 different lesion types (hemorrhage, hard and soft exudates, microaneurysm). The multilabel MuE is a ResNet [6] with pre-trained weights, trained with 100 images. The remaining 43 images were used as samples in \(\mathcal {D}\).
ISIC 2018 Skin Lesion AnalysisFootnote 2: 1,876 dermoscopic images of skin lesions. Here \(N_C=5\), consisting of different skin lesions types: pigment network, negative network, globules, milia like cysts and streaks. The MuE is a pre-trained ResNet [6] trained with 70% of data. A hundred randomly chosen images from the 30% test images were used to populate \(\mathcal {D}\).
OCT: 200 OCT cross-sectional slices from Age-Related Macular Degeneration and Diabetic Macular Edema patients. Eleven different biomarkers potentially can be present in any cross-section (\(N_C=11\)). All 200 images are used for \(\mathcal {D}\) and a seperate trained Dilated Residual Network [15] is used for the MuE.

Performance model for the 4 questioning strategies. The most common concept (Drusen) and a rare concept (Geographic Atrophy - GA) are shown after 100 questions are posed to the multilabel MuE.
Given that we are not focused on optimizing the performance of a specific MuE but rather on evaluating relative behavior with respect to concepts, we also provide a set of synthetically generated MuEs for which we understand their performance fully. That is, given that the distribution of concepts in \(\mathcal {D}\) is not uniform for any of the datasets, we wish to compare each MuE to a “biased” MuE. To do this, we simulate a biased MuE that answers with \(90\%\) accuracy questions regarding the most common concept and \(50\%\) on all others. Similarly, we simulate a MuE with a \(50\%\) accuracy for the most common concept, and \(90\%\) on all others. Last, we also simulate an unbiased algorithm, with a \(70\%\) accuracy regardless of the concept or class imbalance.
3.2 Experiments
To evaluate our framework, we compare four questioning strategies: (a) random, (b) based on the predictability of the question given the previous questions and the dataset [4], (c) based on the uncertainty of the question as defined in Sect. 2.2, and (d) based on the combination of the above two, as described in Sect. 2.2.

Uncertainty of the performance model with respect to the number of questions asked for different MuEs. Each column corresponds to a dataset. Rows, from top to bottom: image example, uncertainty for unbiased MuE, uncertainty for biased to most common concept MuE, uncertainty for negatively biased to most common concept MuE and uncertainty for trained multilabel classifier.
Figure 3 depicts the state of the performance for two concepts (GA and Drusen) after a hundred questions have been asked on the OCT dataset using the trained MuE. In all plots the bias in concept occurrence can be observed and we see that both the random strategy, and the one relying solely on the unpredictability criteria, are prone to not ask many questions about rare concepts (GA concept), thus delaying the assessment of the MuE’s on this concept. Both uncertainty based methods however manage to sample adequately and are more confident in the performance model.
In another experiment, we ask all possible questions following each one of the four described strategies. That is, the state of the performance model is the same after all questions have been asked. We repeat the experiments 10 times, and monitor the average uncertainty as questions are asked. The results are shown in Fig. 4. Here we observe that the proposed questioning strategies reach saturated levels of uncertainty quicker than the other strategies, and would require fewer questions for confident assessments.
4 Discussion
To summarize, we present a more informative and interpretable performance model for evaluating closed-end, “Yes/No” inference methods. To this, we propose a strategy to sample from the - possibly intractable - set of questions, in order to reach high certainty in the performance model characterizing the MuE and the validation data. We assess our method on three different medical imaging datasets and show that the performance model is able to capture the data distribution information and the MuE biases. Moreover, the questioning strategy allows for faster convergence of the performance model to a low uncertainty state. We will look to extend this concept to segmentation problems in future work.
Notes
- 1.
The approach would be unchanged if the outcome frequency was used.
- 2.
References
Antol, S., et al.: VQA: visual question answering. In: The IEEE International Conference on Computer Vision (ICCV), December 2015
Bendig, A.: Twenty questions: an information analysis. J. Exp. Psychol. 5, 345–348 (1953)
Chuquicusma, M.J., Hussein, S., Burt, J., Bagci, U.: How to fool radiologists with generative adversarial networks? a visual turing test for lung cancer diagnosis. In: 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), pp. 240–244. IEEE (2018)
Geman, D., Geman, S., Hallonquist, N., Younes, L.: Visual turing test for computer vision systems. Proc. Natl. Acad. Sci. 112(12), 3618–3623 (2015)
Hasan, S.A., Ling, Y., Farri, O., Liu, J., Lungren, M., Müller, H.: Overview of the ImageCLEF 2018 medical domain visual question answering task. In: CLEF 2018 Working Notes (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Jedynak, B., Frazier, P., Sznitman, R.: Twenty questions with noise: Bayes optimal policies for entropy loss. J. Appl. Probab. 1, 114–136 (2012)
Lau, J.J., Gayen, S., Abacha, A.B., Demner-Fushman, D.: A dataset of clinically generated visual questions and answers about radiology images. Sci. Data 5, 180251 (2018)
Maier-Hein, L., et al.: Author correction: why rankings of biomedical image analysis competitions should be interpreted with care. Nat. Commun. 10(1), 588 (2019)
Prasanna, P., et al.: Indian diabetic retinopathy image dataset (IDRiD) (2018)
Rasmussen, C.E.: Gaussian Processes for Machine Learning. MIT Press, Cambridge (2006)
Schlegl, T., Seeböck, P., Waldstein, S.M., Langs, G., Schmidt-Erfurth, U.: f-AnoGAN: fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 54, 30–44 (2019)
Turing, A.: Computing machinery and intelligence. Mind 49(236), 433–460 (1950)
Wu, Q., Teney, D., Wang, P., Shen, C., Dick, A., van den Hengel, A.: Visual question answering: a survey of methods and datasets. Comput. Vis. Image Underst. 163, 21–40 (2017)
Yu, F., Koltun, V., Funkhouser, T.: Dilated residual networks, May 2017
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Fountoukidou, T., Sznitman, R. (2019). Concept-Centric Visual Turing Tests for Method Validation. In: Shen, D., et al. Medical Image Computing and Computer Assisted Intervention – MICCAI 2019. MICCAI 2019. Lecture Notes in Computer Science(), vol 11768. Springer, Cham. https://doi.org/10.1007/978-3-030-32254-0_29
Download citation
DOI: https://doi.org/10.1007/978-3-030-32254-0_29
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-32253-3
Online ISBN: 978-3-030-32254-0
eBook Packages: Computer ScienceComputer Science (R0)