
Abstract
In recent years, image saliency detection has become a research hotspot in the field of computer vision. Although significant progress has been witnessed in visual saliency detection, several existing saliency detection methods still cannot highlight the complete salient object when under complex background. For the purpose of improving the robustness of saliency detection, we propose a novel salient detection method via foreground and background propagation. In order to take both foreground and background information into consideration, we obtain a background-prior map by computing the dissimilarity between superpixels and background labels. A foreground-prior map is obtained by calculating the difference of superpixels between the inner and outer of a convex hull. Then we use label propagation algorithm to propagate saliency information based on foreground and background prior maps. Finally, the two saliency maps are integrated to generate an accurate saliency map. The experimental results on two public available data sets MSRA and ECSSD demonstrate that the proposed method performs well against the state-of-the-art methods.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Image saliency detection has become a research hotspot in the field of computer vision. It filters out redundant visual information of an image by imitating the human visual attention mechanism, and selects objects of interest to human eyes, which are called salient objects. Efficient saliency detection models have been applied to numerous computer vision scenarios, such as image classification [1], object detection [2], image retrieval [3], and so forth.
Corresponding to the visual attention mechanism, existing saliency detection models can be broadly categorized as bottom-up [4,5,6], or top-down approaches [7, 8]. Since saliency detection based on bottom-up models which mainly focus on color, intensity, contrast and other low-level visual features of the image, the detection speed is fast. The top-down approaches add a higher level of prior knowledge, which is more complex. In this paper, our work focus on bottom-up salient detection models. Many salient detection models use low-level features such as color and contrast [9, 10] of the image. They perform well in many situations, but still struggle in complex images. Based on the assumption that saliency objects are mostly located in the center of the image, some researchers regard the image boundary region as the background and propose background-prior saliency detection models [11, 12]. They perform well in many cases, except for salient objects that appearing at the edge of the image. Since the background template of the image contains the foreground noise, the detection result has a poor performance.
In this paper, we propose a novel saliency detection method based on foreground and background propagation. First, we obtain a background template by selecting the image border superpixels, which have been proved to be good indicators for background-prior in saliency detection [13, 14]. Second, we calculate the color and spatial distances between each superpixel and the background labels to obtain the background-prior map. Third, we calculate the convex hull of the image, and obtain the foreground-prior map by computing the difference of superpixels between the inner and outer of the convex hulls. Finally, we use label propagation algorithm to propagate saliency information based on foreground-prior and background-prior maps. The saliency result is obtained by integrating two propagated maps.
2 Related Work
Significant progress has been made in visual saliency detection in recent years. A quantitative analysis of different saliency methods can be found in [15]. Most bottom-up saliency detection methods based on contrast and background. It is has been verified that contrast is an effective cue for satisfying results. Furthermore, contrast-based methods can be roughly divided into local and global contrast-based techniques. The model of Itti et al. [4] is one of the typical local contrast-based methods. They define saliency by calculating center-surround differences in color, density, and orientation from images. Harel et al. [16] improved the Itti’s method and added Markov chains to the calculation of saliency maps. Achanta et al. [17] proposed a multi-scale contrast saliency detection method by calculating contrasts of feature vectors between the inner and outer regions of a sliding window. Hou et al. [18] proposed a frequency-based method, which uses the spectral residual in the frequency domain to extract saliency regions of the image. Global contrast-based approaches use contrast relationships of the whole image to calculate the saliency of single pixels or image regions. Goferman et al. [6] proposed a context-aware saliency detection method that computes the average of salient values at multiple scales to obtain saliency regions. Achanta et al. [19] propose a frequency-tuned method that directly defines saliency as the differences of image color distances. Cheng et al. [5] proposed a saliency detection method based on color contrast and spatial position features, using color contrast weighted by spatial distance to define the salient regions.
Background-based methods typically regard image border pixels as background labels, which calculate saliency by background labels query or propagation mechanism. Yang et al. [20] proposed a saliency detection algorithm based on manifold ranking, which ranks the similarity of the image’s superpixels with the background labels on a graph to obtain saliency maps. Li et al. [21] regard boundary superpixels as background templates, and obtain salient results by constructing sparse and dense errors. Wang et al. [22] proposed a method based on foreground and background seed selection, which uses image border superpixels to generate foreground and background saliency maps. Zhu et al. [23] proposed a saliency detection method based on boundary connectivity, which characterizes the spatial layout of image regions. Zhang et al. [24] proposed an approach based on local structure propagation, which updates saliency values under the guidance of local propagation.
3 Proposed Method
In this section, we present an efficient and effective saliency detection method that integrates foreground and background information of the image, as shown in Fig. 1. We first abstract the image into superpixels using simple linear iterative clustering (SLIC for short). Then, we compute background-prior map by selecting boundary labels, and use convex hulls to generate foreground-prior map. Finally, we use label propagation saliency (LPS for short) respectively on foreground-prior and background-prior map, and integrate the two propagated saliency maps to generate a pixel-wise saliency map.

Flowchart of the proposed method. It contains three stages: abstracting the image; computing background-prior map and foreground-prior map; generating a pixel-wise saliency map that integrates two propagated saliency maps.
3.1 Background Labels Selection
The strategy of selecting background labels affects the precision of the salient map. Based on the observation of saliency models that the object is likely to appear at the center of an image, the border near the image center is selected as the background labels. However, this method may contain foreground noise, which affects the results of saliency detection. Therefore, we propose a mechanism based on image boundary information to remove the foreground noises and select background labels from the border superpixels.
We first use SLIC algorithm to abstract the image into N uniform and compact regions. Then we select the superpixels whose centroids locate within a certain number of pixels as image background template. Since the most obvious boundary of the image is likely to be the contour between the object and background, we can roughly remove the image superpixels with strong boundaries, which are regarded as the foreground noises.
We adopt the probability of boundary (PB for short) [25] to detect image boundary. The boundary feature of the i-th superpixel is calculated from the average PB value of the pixel along the edge contour of the superpixel i, as follows:
Where \( B_{i} \) is the edge pixel set of superpixel i and \( \left| {B_{i} } \right| \) is the number of the template. \( I^{pb} \) is the PB value of pixel \( I \). The larger the PB value, the more obvious the boundary feature of the superpixel. Since superpixels with obvious boundary feature is more likely to be the object, we remove the superpixels whose boundary features are larger than the adaptive gray threshold derived by Otsu [26]. Then the remaining superpixels in the background template are selected as background labels. As shown in Fig. 2, the selected background labels have less foreground noise than the background template.

Illustration of the main phases of our method. (a) Input image. (b) Superpixels generated by SLIC. (c) The convex hull. (d) The prior map based on background template. (e) The prior map based on selected background labels. (f) The foreground-prior map.
3.2 Background-Prior Saliency
If a superpixel has larger color differences to the background labels, it is more likely to be a salient superpixel. In addition, the background labels contribute more for the salient value of the closer superpixels while less to a farther one. Therefore, we use spatial weight based color contrast to define a salient superpixel \( p_{i} \), as follow:
Where \( d_{c} \left( {p_{i} ,p_{j} } \right) \) and \( d_{s} \left( {p_{i} ,p_{j} } \right) \) are respectively the Euclidean color and spatial distances between the i-th superpixel and the j-the superpixel which belongs to the background template. Both distances are normalized to [0, 1].
3.3 Foreground-Prior Saliency
We use image corner points to select foreground seeds. Traditional Harris point detection algorithm only considers the gray information of the image, which leads to more invalid corner or contour points being detected in complex cases. Since the color boosted Harris detection algorithm combines brightness information and color information to make most points locate around salient objects, the detection result is more stable. Therefore, in this paper we use Harris point detection algorithm [27] to detect corners or contour points of salient objects in the image.
Since salient points are usually not located in image boundary, we eliminate those near the image boundary, and enclose all the remaining salient points to compute a convex hull. Then we select the foreground seeds based on the difference of the superpixels between the inner and outer of the convex hull. We define the superpixels set in the convex hull as \( I \), and the superpixels set outside the convex hull as \( O \). The difference of superpixels between the inner and outer of the convex hull is defined as follow:
Where \( \left| {\left| {c_{i} - c_{j} } \right|} \right| \) and \( {\text{w}}\left( {p_{i} ,p_{j} } \right) \) are respectively the Euclidean color and spatial distances between the j-th superpixel and the i-th superpixel which belongs to the convex hull. Both distances are normalized to [0, 1]. We remove the superpixels in the convex hull that are less than the average difference and regard the remaining superpixels as foreground seeds. The average difference is defined as \( \upalpha = \frac{1}{I}\sum\nolimits_{j = 1} {d_{j} } ,j \in I \), where \( \left| I \right| \) is the number of superpixels in a convex hull. Figure 2 shows the foreground-prior map of our method.
3.4 Graph Construction
We create a graph \( {\text{G}} = \left( {{\text{V}},{\text{E}}} \right) \) with N nodes \( \left\{ {n_{1} ,n_{2} , \cdots ,n_{N} } \right\} \) and edges \( {\text{E}} \). Node \( n_{i} \) corresponds to the i-th image superpixel or patch and edge \( e_{ij} \) link nodes \( n_{i} \) and \( n_{j} \) to each other. The similarity of two nodes is measured by a defined distance of the mean color features in each region. We define \( w_{ij} \) as the weight of the edge between node \( n_{i} \) and node \( n_{j} \). The affinity matrix \( {\text{W}} = \left[ {w_{ij} } \right]_{N \times N} \) indicate the similarity between superpixels:
Where \( N\left( i \right) \) indicates the set of the neighboring nodes of superpixel i, \( ||c_{i} - c_{j} ||_{2} \) represents the average color distance of two superpixels on the CIE LAB color space. \( \sigma^{2} \) is a tuning parameter, which controls strength of the similarity. The degree matrix of graph \( {\text{G}} \). \( {\text{D}} = {\text{diag}}\left\{ {d_{1} ,d_{2} , \cdots ,d_{N} } \right\} \), where \( d_{i} = \sum\nolimits_{j} {w_{ij} } \) is the degree of node i, and a row-normalized affinity matrix:
3.5 Label Propagation Saliency
In [28], a label propagation that get information about unlabeled nodes based on the provided labelled nodes is proposed. Given a data set \( X = \left\{ {x_{1} , \cdots ,x_{i} ,x_{i + 1} , \cdots ,x_{n} } \right\} \in R^{m \times n} \), the former \( {\text{i}} \). ta points are labelled and the rest need to be propagated according to their relevance to the labelled points. We seek out a function \( V = \left[ {V_{{m_{1} }} ,V_{{m_{2} }} , \cdots ,V_{{m_{N} }} } \right]^{T} \) such that \( V:{\text{R}} \to \left[ {0,1} \right] \in R^{N \times 1} \) indicates the possibility of how similar each data point is to the labels. The similarity measure \( V\left( {r_{i} } \right) \) satisfies:
Where, \( w_{ij} \) is the affinity entry defined in Eq. 5 and t is the recursion step. The similarity measure of the labeled tag in the recursive process is fixed to 1, and the initial measure of the unlabeled objects is set to 0. The final similarity of the region to the label is influenced by the features of the surroundings. In other words, the similarity \( V\left( {r_{i} } \right) \) is iteratively learned by the propagation of the similarity measure of its neighbor \( V\left( {r_{j} } \right) \).
Then, we integrate the two saliency maps: the foreground-propagated based one which highlight the whole object and the one based on background propagation which reduce the background noses, as follow:
Where \( S_{f} \) is a foreground-propagated saliency map, \( S_{b} \) is a background-propagated saliency map.
4 Experimental Results
In this section, we evaluate our method on two public available data sets. One is MSRA [19] data set that contains 1000 images, which equipped with pixel-wise ground truth. The other is ECSSD [29] data set which contains 1000 natural images under complex background.
We compare the performance of the proposed method with other 7 state-of-the-art methods: IT [4], FT [19], BSCA [12], GBMR [20], BFS [22], DSR [21], and LPS [28]. The evaluation standards are precision and recall (PR) curve and F-measure. We segment the saliency map using a threshold between 0 and 255 for each method, then compare the binary map obtained by different thresholds with ground truth to obtain the precision and recall curve. F-measure is used to comprehensively evaluate the performance of recall and precision, we set \( \beta^{2} = 0.3 \) [5] in order to emphasize precision:
Figure 3 shows the precision and recall curve (PR curve for short) and F-measure comparison results of our method with other methods on MSRA-1000 data set and ECSSD data set. For the MSRA-1000 data set, the background of images are relatively simple. The precision and recall curve obtained by our method is obviously superior to other saliency detection algorithms. Although LPS and DSR methods also achieved better results in precision and recall curve and F-measure, the value of F-measure in our proposed method are 1.7% and 2.1% higher than LPS and DSR methods respectively. For the ECSSD data set, the background of images are more complicated. Although our method and LPS have achieved good results, the precision and recall of our method are 77% and 68% respectively, higher than the LPS algorithm with 71% precision and 64% recall.

Quantitative PR-curve and F-measure evaluation of different methods on two data sets: (a) MSRA, (b) ECSSD
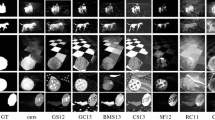
Figure 4 shows several images for visual comparison to previously published methods. From these samples, we can see that our method achieves the best performance on these images. Most saliency methods can detect the complete saliency objects when the background is relatively simple. When the background of the image is more complicated, the results of other saliency methods either contain background noise or are incomplete. Since we consider both foreground and background information, our method can effectively suppress background noises. With the help of the label propagation, our method can assign high salient values to candidate objects based on the differences between the labels. Furthermore, our experimental results are closer to Ground Truth, and conserve a more complete boundary of the salient objects.

5 Conclusion
In this paper, we propose a novel saliency detection algorithm based on foreground and background propagation. First, we select the image border superpixels to obtain background information and calculate a background-prior map. Second, we use salient points detected by the color boosted Harris algorithm to obtain a convex hull and compute a foreground-prior map. Third, we use label propagation algorithm to propagate saliency on the two prior saliency maps respectively. The final saliency map is obtained by integrating the foreground and background propagated saliency map. Results on two benchmark data sets show that our methods achieve superior performance compared with the state-of-the-art methods.
References
Schmid, C., Jurie, F., Sharma, G.: Discriminative spatial saliency for image classification. In: Computer Vision and Pattern Recognition, pp. 3506–3513. IEEE, Providence (2012)
Zhao, R., Ouyang, W., Wang, X.: Unsupervised salience learning for person re-identification. In: Computer Vision and Pattern Recognition, pp. 3586–3593. IEEE, Portland (2013)
Cheng, M.M., Mitra, N.J., Huang, X., et al.: Salient shape: group saliency in image collections. Vis. Comput. 30(4), 443–453 (2014)
Itti, L., Koch, C., Niebur, E.: A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 20(11), 1254–1259 (1998)
Cheng, M.M., Zhang, G.X., Niloy, J., et al.: Global contrast based salient region detection. In: Computer Vision and Pattern Recognition, pp. 409–416. IEEE, Colorado Springs (2011)
Goferman, S., Zelnik-Manor, L., Tal, A.: Context-aware saliency detection. Pattern Anal. Mach. Intell 34(10), 1915–1926 (2012)
Yang, J., Yang, M.H.: Top-down visual saliency via joint CRF and dictionary learning. In: Computer Vision and Pattern Recognition, pp. 2296–2303. IEEE, Providence (2012)
Kanan, C., Tong, M.H., Zhang, L., et al.: SUN: top-down saliency using natural statistics. Vis. Cognit. 17(6–7), 979–1003 (2009)
Huo, L., Jiao, L., Wang, S., Yang, S.: Object-level saliency detection with color attributes. Pattern Recogn. 49, 162–173 (2016)
Zhou, L., Yang, Z., Yuan, Q., et al.: Salient region detection via integrating diffusion-based compactness and local contrast. IEEE Trans. Image Process. 24(11), 3308–3320 (2015)
Wei, Y., Wen, F., Zhu, W., Sun, J.: Geodesic saliency using background priors. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012. LNCS, vol. 7574, pp. 29–42. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33712-3_3
Qin, Y., Lu, H., Xu, Y., Wang, H.: Saliency detection via cellular automata. In: Computer Vision and Pattern Recognition, pp. 110–119. IEEE, Boston (2015)
Li, X., Lu, H., Zhang, L., et al.: Saliency detection via dense and sparse reconstruction. In: IEEE International Conference on Computer Vision, pp. 2976–2883. IEEE, Sydney (2013)
Wang, Q., Zheng, W., Piramuthu, R.: GraB: visual saliency via novel graph model and background priors. In: IEEE Conference on Computer Vision and Pattern Recognition. IEEE, Nevada (2016)
Borji, A., Cheng, M.M., Jiang, H., et al.: Salient object detection: a benchmark. IEEE Trans. Image Process. 24(12), 5706–5722 (2015)
Harel, J., Koch, C., Perona, P.: Graph-based visual saliency. Adv. Neural Inf. Process. Syst. 19, 545–552 (2007)
Achanta, R., Estrada, F., Wils, P., Süsstrunk, S.: Salient region detection and segmentation. In: Gasteratos, A., Vincze, M., Tsotsos, John K. (eds.) ICVS 2008. LNCS, vol. 5008, pp. 66–75. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-79547-6_7
Hou, X., Zhang, L.: Saliency detection: a spectral residual approach. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8. IEEE, Hawaii (2007)
Achanta, R., Hemami, S., Estrada, F., et al.: Frequency-tuned salient region detection. In: IEEE International Conference on Computer Vision and Pattern Recognition, pp. 1597–1604. IEEE, Florida (2009)
Yang, C., Zhang, L., Lu, H., et al.: Saliency detection via graph-based manifold ranking. In: IEEE International Conference on Computer Vision and Pattern Recognition, pp. 1665–1672. IEEE, Portland (2013)
Li, X., Lu, H., Zhang, L., et al.: Saliency detection via dense and sparse reconstruction. In: IEEE International Conference on Computer Vision, pp. 2976–2883. IEEE, Portland (2013)
Wang, J., Lu, H., Li, X., et al.: Saliency detection via background and foreground seed selection. Neurocomputing 152(25), 359–368 (2015)
Zhu, W.J., Liang, S., Wei, Y.C., Sun, J.: Saliency optimization from robust background detection. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, pp. 2814–2821. IEEE, Columbus (2014)
Zhang, M., Pang, Y., Wu, Y., et al.: Saliency detection via local structure propagation. J. Vis. Commun. Image Represent. 52, 131–142 (2018). S1047320318300129
Martin, D.R., Fowlkes, C.C., Malik, J.: Learning to detect natural image boundaries using local brightness, color, and texture cues. Pattern Anal. Mach. Intell. 26(5), 530–549 (2004)
Otsu, N.: A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man. Cybern. 9(1), 62–66 (1979)
Van de, W.J., Gevers, T., Bagdanov, A.D.: Boosting color saliency in image feature detection. IEEE Trans. Pattern Anal. Mach. Intell. 28(1), 150–156 (2006)
Li, H., Lu, H., Lin, Z., et al.: Inner and inter label propagation: salient object detection in the wild. IEEE Trans. Image Process. 24(10), 3176–3186 (2015)
Yan, Q., Xu, L., Shi, J, Jia, J.: Hierarchical saliency detection. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1155–1162. IEEE, Portland (2013)
Acknowledgement
Thanks for the support of National Key R&D Program Key Projects NQI (No.2017YFF0206400), the Natural Science Foundation of Tianjin (No.17JCYBJC16300), and Innovation Fund of National Ocean Technology Center (No.K51700404).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Xing, Q., Zhang, S., Li, M., Dang, C., Qi, Z. (2019). Saliency Detection Based on Foreground and Background Propagation. In: Zhao, Y., Barnes, N., Chen, B., Westermann, R., Kong, X., Lin, C. (eds) Image and Graphics. ICIG 2019. Lecture Notes in Computer Science(), vol 11901. Springer, Cham. https://doi.org/10.1007/978-3-030-34120-6_18
Download citation
DOI: https://doi.org/10.1007/978-3-030-34120-6_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-34119-0
Online ISBN: 978-3-030-34120-6
eBook Packages: Computer ScienceComputer Science (R0)
