
Abstract
One-stage object detection methods have attracted much attention for their high speed performance compared with two-stage methods. But one-stage methods under performs with small object detection. Feature Pyramid Network (FPN) was widely used to deal with this problem for its multi-scale feature present ability. However there still remains a few problems that are not considered in FPN, which results in limited improvement in detector performance. We note that FPN does not take the weight and scale distribution between different levels of feature maps into account when merging high-level feature maps and low-level feature maps. We present a network named Weighted Feature Pyramid Network (WFPN) to address these problems. Our experimental results on PASCAL VOC and MS COCO show that WFPN can significantly improve the detector performance, especially on small object detection.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In recent years, deep learning has significantly pushed the development of object detection. There are a large quantity of deep learning based methods for detection task [7, 10,11,12,13, 21, 22]. On the whole, these methods can be classified into two-stage and one-stage methods. The first stage of two-stage methods is proposing some candidate bounding boxes [3]. The following network classification objects that is indicated by those bounding boxes, regression on each bounding box is used to accelerate the intersection over union (IoU) of predicted box and ground truth box. One-stage methods do not need candidate bunding boxes, they use neural network regression to calculate objects location and class.
Two-stage methods such as R-CNN [5], Fast R-CNN [4], Faster R-CNN [16] and other R-CNN series methods obtain high accuracy but low speed on many public detection datasets such as PASCAL VOC 2007 and COCO. One-stage methods such as YOLO series [7, 12,13,14], SSD [11] reach a very high FPS compared with two-stage methods. But there is a big gap between one-stage and two-stage methods for mAP of public detection datasets. One-stage methods remove the proposal process that two-stage methods use to generate candidates for bounding box. Such measures dramatically accelerate the speed of methods but reduce the accuracy at the same time. This is largely because one-stage methods suffer from the small object detection accuracy [15].
Small objects occupy fewer pixels on image, therefore repeated CNN convolution operations on features of small object which could even be one pixel make it difficult for the regression network to recognize such small object on the feature map. There are numerous researches for this issue. Feature Pyramid Network (FPN) [10] that is inspired by feature pyramids built upon image pyramids were heavily used in the era of one-stage methods. FPN use a bottom-up pathway, a top-down pathway, and lateral connections upon several layers output feature map of CNN to build a feature pyramid with high-level semantics. But FPN consider the low-level feature as important as high-level feature for detection task. Detection task can be divided into classification and location tasks. High-level feature maps have strong semantic information which can benefits classification task, whereas low-level feature maps have high resolution that can contribute to location task [6]. But is the importance of those two subtasks equal for the detection task?
In order to figure out this problem, we consider giving high-level feature maps and low-level feature maps different weights when building feature pyramid. We speculate that the weights of these two features may have different effects on the detection task of large objects and small objects. The bounding box of small objects is small, so the network does not need much location information to perform regression on the predicted bounding box. In contrast, the feature of small objects occupies so few pixels on the whole feature map that it may increase the classification loss. Based on the above reasons, we give high weight to high-level feature map that contain more semantic information to benefit classification. The large ground truth bounding box of large objects may lead to high location loss. On the other hand, their features on the whole feature map is usually big enough to provide class information needed for the classification task. So we give a small weight to low-level feature map that contain more location information.
We verified our assumptions on the PASCAL VOC 2007, 2012 and MS COCO dataset. The results demonstrate that our proposed WFPN can significantly improve the detection performance, especially small object detection.
Our contributions are summarized as follows:
-
High-level feature maps and low-level feature maps have different importance when merging different level feature map for multi-scale object detection. Since high-level feature map contains strong semantic information and is more important than low-level feature map.
-
Batch normalization before feature merging improves the effect of feature representation. Since high-level and low-level feature maps have different scale distribution.
-
Experimental results on PASCAL VOC and MS COCO demonstrate the Weighted Feature Pyramid Network (WFPN) can significantly improve the performance of one shot object detection network.
2 Related Work
Small object detection at vastly different scales is a fundamental challenge in object detection task and many researchers have made efforts to this end. In this section, we take an overview of some methods that attempts to enhance small object detection performance on multi-scale detection task.
Featurized Image Pyramid. Hand-craft features were heavily used to extract features of image prior to the proposal of AlexNet in 2012. Feature image pyramid that built upon image pyramids from the basis of a standard solution is a widely used method to deal with multi-scales object detection. This method firstly resize image to different resolutions to get an image pyramid, and then extract the hand-engineered features from the image pyramid to establish the featurized image pyramid. Featurized image pyramid has used extensively not only on object detection but also on human pose estimation and other computer vision tasks.
Feature Pyramid Network. With the development of deep learning, ConvNets show the powerful capabilities in feature extraction. But extracting features from image pyramid to build a feature pyramid by ConvNets need a huge computing and storage resources. Tsung-Yi Lin et al. proposed Feature Pyramid Network (FPN) [10] to exploit the inherent multi-scale, pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost. FPN use a top-down architecture with lateral connections to build high-level semantic feature maps at all scales. The top-down pathway uses nearest neighbor upsample by a factor of 2 to resize the upper layer feature map to the low layer feature map size [17]. And the lateral connections combine the upper layer feature map with bottom-up feature map (which undergoes a 1 \(\times \) 1 convolutional layer to reduce channel dimensions equal to the upper layer feature map) by element-wise addition. FPN was widely used in the area of multi-scale object detection.
YOLOv3 is a state-of-art one stage object detector proposed by Joseph Redmon et al. and uses a specially designed backbone network named darknet-53 [14]. And YOLOv3 draws on the idea of FPN, which uses final three stage of feature maps to build an FPN structure to predict the bounding boxes and categories of objects. However, like FPN, YOLOv3 also does not consider the influence of feature maps from different level on the detection performance.
3 Weighted Feature Pyramid Network
3.1 The Entire Framework
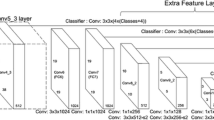
ConvNets have almost replaced hand-engineered image feature extraction in computer vision for their powerful feature extraction capabilities [9, 18, 19]. It is well known that high-level feature maps in ConvNets contain strong semantic information compared to low-level feature map [1]. FPN aims to improve object detector performance by merging high-level and low-level features, which is a widely used method in the area of object detection research. But FPN did not consider the different importance of high-level and low-level features for detection task. In this paper, we are committed to research the effects of different weights for high-level features and low-level features on the detection task. In light of the fact that YOLOv3 is a state-of-art one stage object detector which used the FPN idea, we adopt the YOLOv3 to bulid our detection framework. The whole framework as shown in the Fig. 1 composed of darknet-53 for feature extraction and WFPN for feature fusion.

We use the outputs of Res3, Res4 and Res5 to build WFPN. Feature fusion module consists of a top-down pathway (which composed of a deconvolutional layer, a ReLU layer and a batch normalization layer) and a lateral connection (which composed of a 1 \(\times \) 1 convolutional layer, a ReLU layer and batch normalization layer). Merged feature map serves as the input of detection layer and another fusion module top-down pathway.
3.2 Feature Extraction
Same as the YOLOv3, we use darknet-53 [14] as the backbone to extract feature maps from input images. The structure of darknet-53 is shown in Table 1. We call the combination of two convolutional layers and one residual layer in the box as a residual block. In this paper, we use the feature maps that is output by the final three residual blocks to build the feature pyramid network.
3.3 Feature Fusion
Feature fusion module contains a top-down pathway, a lateral connection and a element-wise addition block. Top-down pathway consists of an upsample layer, a Leaky-ReLU layer and a batch normalization layer [8]. Upsample layers upsamples the upper layer feature map by a factor of 2 to make sure it can be merged with lower layer feature map. Since it has been proven that deconvolutional performs better than linear upsample methods, we use deconvolutional layer for upsampling [20]. We deem that different layer feature maps show different scale distribution, it is essential to normalize features before fusion. So we add a ReLU layer and a batch normalization [8] layer to deal with this problem. Lateral connection do 1x1 convolution on the lower layer feature map to adopt its channels unified to be 256, which is the minimum of final four residual block output channel. As with the top-down pathway, a ReLU layer and a batch normalization layer are used to handle the different scale distribution problem. Then we fuse the output of top-down pathway and the lateral connection by an element-wise addition block. We consider that upper layer feature map contains more strong semantic information which is beneficial to classification. So we give a high weight to the output of the fusion modules top-down pathway when merging the feature map by element-wise addition. The fusion module can be formulize as:
where
in the above, \(F_{c}\) is the feature map that fuse \(F_{h}\) (which is the input of fusion module top-down pathway) and \(F_{l}\) (which is the input of fusion module lateral connection). And \(w_{h}\) is the weight of high level feature map, that is, the upper layer feature map or merged upper layers feature map. \(w_{l}\) is the weight of low layer feature map. \(\gamma \) and \(\beta \) is learnable parameters of network, \(\mu \) is the mean of mini-batch, \(\sigma ^{2}\) is the variance of mini-batch. k is the filter of previous convolutional layer.
4 Experiments
4.1 Datasets
To verify the effectiveness of the proposed WFPN, we conduct experiments on two widely used datasets, namely, PASCAL VOC and MS COCO. PASCAL VOC have over 10000 color images in 20 classes. We split the data into 50% for training/validation and 50% for testing. The distributions of images and objects by class are approximately equal across the training/validation and test sets. MS COCO is a large-scale object detection dataset which have over 330000 images in 80 object categories. Compared with PASCAL VOc, MS COCO have more small objects and more objects per image, and most of the objects are not centered, which is more in line with daily environment, so detection on COCO is more difficult.
4.2 Training Mechanism
We fine tune the Network based on pretrained YOLOv3 weights provided by [14]. We start training with learning rate of \(10^{-3}\) and desent it by a factor of 0.1 if the validation loss does not decent for two consecutive epochs. We stop our training if validation loss does not decent for ten consecutive epochs.
4.3 Ablation Experiments
We perform ablation experiments on PASCAL VOC 2007 and 2012 benchmarks datasets and on MS COCO 2015 benchmark dataset to analy in detail each components of our network. We first replace each component based on same hyper parameters step-by-step to analyse the real effects of each component. On these experiments, we give same weights to high-level and low-level feature map. In practice, we set \(w_{h}\) and \(w_{l}\) equal to 1. We show these in experiments below.
Fusion Methods. We first consider three different element-wise operations to merge the output feature maps of top-down pathway and lateral connection. The results in the Table 2 shows that element-wise addition perform well than element-wise maximum and element-wise product, and element-wise product perform worst. This situation can be understood from the information flow during training. In the forward propagation phase, addition enables network to take full advantage of the information from two branches complementary with-out losing any information. And in the backpropagation phase, it can equally distribute the gradient to each branches. For the element-wise maximum, the network only use one branch information which has high values during the forward propagation phase and only routes the gradient to the higher input branch. The element-wise product assigns a small gradient to the high input branch and a large gradient to the low input branch, which makes the network hard to converge. Therefore, element-wise addition has a better performance on feature map fusion, and element-wise perform worst. For these reasons, we choose element-wise addition to merge feature maps.
Activation and Batch Normalization. We assume that feature map of different level have different scale distributions, so we add a Leaky-ReLU and a batch normalization layer in the end of the top-down pathway and the lateral connection. We verify the necessity of adding these two layers through the ablation experiments. The results in the Table 3 shows that adding a ReLU and batch normalization layer can effectively improve the detection effect. Hence, we use a Leaky-ReLU layer and a batch normalization layer to solve the problem of distribution diverseness.
4.4 Weight Selection
The ablation experiments proved the rationality and necessity of our network design. On this basis, we discuss the distribution of different level feature map weights when feature map merging.
Firstly, we fixed \(w_{l}\) to focus on the efforts of \(w_{h}\) to the network. We trained the network on PASCAL VOC 2012, and evaluates it on the PASCAL VOC 2007 benchmark. As the results shown in the Fig. 2(a), when we set \(w_l\) equal to 0.8, we can get a better mAP in most cases. It is worth noting that almost all curves have an upward trend when the value of \(w_h\) are 1 to 1.8, and begin decline after 1.8 except the curve with \(w_l\) choose as 0.4. We can deduce two conclusions from this situation. An obvious one is that it is a fine choise to let \(w_h\) equal to 1.8 to get a better detector. Another one is that it is not a good idea to assign a very low value of \(w_l\), otherwise a serious imbalance between high-level feature and low-level feature may lead to poor detection AP.
Then we fixed \(w_{h}\) to observe the influence of \(w_{l}\) to the final detection performance. The results shown in the Fig. 2(b) shows again that 1.8 is an appropriate value of \(w_{h}\) and the best choice of \(w_{l}\) maybe 0.8.

Each weights efforts
4.5 YOLOv3 with WFPN
Finally, we set \(w_{l}\) equal to 0.8 and \(w_{h}\) equal to 1.8, and use the feature maps which is output from the final three residual blocks of darknet-53 to build a weighted FPN (for simplicity, we call it WFPN-YOLOv3). We conducted a comparative test with YOLOv3, SSD and DSSD on the PASCAL VOC 2007+2012 benchmark and MS COCO 2015 benchmark. The results is shown in the Tables 4 and 5.
As can be seen from the Table 4, our network performs better on most categories, especially on the “small” categories such as bird, boat, bottle and plant etc. Comparied with YOLOv3, our network achieves a 3.2% improvement on bird class, a 5.7% improvement on boat class, a 6.1% on bottle class and a 5.7% improvement on plant class. WFPN-YOLOv3 performance on other classes also gets a little improvement or nearly the same with YOLOv3.
Results on Table 5 shows that our proposed WFPN-YOLOv3 achieves 44% mAP on MS COCO, which outperforms the YOLOv3 by 4%. WFPN-YOLOv3 gets a 7% improvement from YOLOv3 on small object AP, a 3% improvement on middle object AP and gets the same AP on large object AP. On PASCAL VOC dataset, WFPN-YOLOv3 only gets a 2.1% improvement from YOLOv3, but it gets a 4% improvement from YOLOv3 on the MS COCO dataset. The performance can be attributed to MS COCO having more small objects and more objects per image.
Experimental results above demonstrate that our WFPN which gives high level feature map a higher weight, have a good performance on small object (Fig. 3).

Qualitative results on PASCAL VOC. The left column is the test result of YOLOv3, and the right column is the test result of WFPN-YOLOv3.
5 Conclusion
In this paper, we have presented a Weighted Feature Pyramid Network (WFPN) which considers the different importance between high-level feature maps and low-level feature maps when feature pyramid network is used to merge feature maps. WFPN assigns higher weight to upper layer feature maps since the upper layer feature maps with stronger semantic information are more useful for object detection. Moreover, WFPN introduces batch normalization to solve the problem of different scale distributions between high-level feature maps and low-level feature maps when FPN is performing feature fusion. The experimental results on PASCAL VOC and MS COCO demonstrate that WFPN significantly improves the small object detection effect of detector, while the large object detection effect are not reduced.
References
Cai, Z., Fan, Q., Feris, R.S., Vasconcelos, N.: A unified multi-scale deep convolutional neural network for fast object detection. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 354–370. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_22
Fu, C.-Y., Liu, W., Ranga, A., Tyagi, A., Berg, A.C.: DSSD: deconvolutional single shot detector (2017)
Ghodrati, A., Diba, A., Pedersoli, M., Tuytelaars, T., Van Gool, L.: DeepProposals: hunting objects and actions by cascading deep convolutional layers. Int. J. Comput. Vis. 124(2), 115–131 (2017)
Girshick, R.: Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, vol. 2015, pp. 1440–1448 (2015)
Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2014
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
Huang, R., Pedoeem, J., Chen, C.: YOLO-LITE: a real-time object detection algorithm optimized for non-GPU computers. In: Proceedings - 2018 IEEE International Conference on Big Data, Big Data 2018, pp. 2503–2510 (2019)
Ioffe, S., Szegedy, C.: Batch normalization: accelerating deep network training by reducing internal covariate shift (2015)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems, vol. 25, pp. 1097–1105. Curran Associates Inc. (2012)
Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: Proceedings - 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, pp. 936–944 (2017)
Liu, W., et al.: SSD: single shot multibox detector. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9905, pp. 21–37. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_2
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: Unified, real-time object detection, you only look once (2015)
Redmon, J., Farhadi, A.: YOLO9000: better, faster, stronger. In: Proceedings - 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, pp. 6517–6525 (2017)
Redmon, J., Farhadi, A.: Yolov3: an incremental improvement. CoRR, abs/1804.02767 (2018)
Ren, J., et al.: Accurate single stage detector using recurrent rolling convolution. CoRR, abs/1704.05776 (2017)
Ren, S., He, K., Girshick, R.B., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. CoRR, abs/1506.01497 (2015)
Rusk, N.: Deep learning. Nat. Methods 13(1), 35 (2015)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. Computer Science (2014)
Szegedy, C., et al.: Going deeper with convolutions. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1–9, June 2015
Woo, S., Hwang, S., Kweon, I.S.: StairNet: top-down semantic aggregation for accurate one shot detection. In: Proceedings - 2018 IEEE Winter Conference on Applications of Computer Vision, WACV 2018, pp. 1093–1102 (2018)
Zhang, S., Wen, L., Bian, X., Lei, Z., Li, S.Z.: Single-shot refinement neural network for object detection. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 4203–4212 (2018)
Zhu, C., He, Y., Savvides, M.: Feature selective anchor-free module for single-shot object detection (2019)
Acknowledgments
This work was supported by the National Natural Science Foundation of China (No. 61672268) and the Primary Research & Development Plan of Jiangsu Province (No. BE2015137).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Tu, X., Zhan, Y. (2019). Weighted Feature Pyramid Network for One-Stage Object Detection. In: Zhao, Y., Barnes, N., Chen, B., Westermann, R., Kong, X., Lin, C. (eds) Image and Graphics. ICIG 2019. Lecture Notes in Computer Science(), vol 11901. Springer, Cham. https://doi.org/10.1007/978-3-030-34120-6_49
Download citation
DOI: https://doi.org/10.1007/978-3-030-34120-6_49
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-34119-0
Online ISBN: 978-3-030-34120-6
eBook Packages: Computer ScienceComputer Science (R0)
