
Abstract
Integration of renewable sources into energy grids has reduced carbon emission, but their intermittent nature is of major concern to the utilities. In order to provide an uninterrupted energy supply, a prior idea about the total possible electricity consumption of the consumers is a necessity. In this paper, we have introduced a deep learning based load forecasting model designed using dilated causal convolutional layers. The model can efficiently capture trends and multi-seasonality from historic load data. Proposed model gives encouraging results when tested on synthetic and real life time series datasets.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Load forecasting
- Smart grids
- Deep learning
- Dilated causal convolutional network
- Renewable energy resource
1 Introduction
Load forecasting problem, commonly occurring in the context of smart grid systems deals with prediction of future energy demands of consumers based on their previous load consumption. There has been an extensive research in load forecasting problems, however prediction of future loads with high accuracy remains an open problem till date.
With the advancement of deep learning models, the complex patterns in sequential input data like in time series, can now be better identified over conventional machine learning models. Recently, deep neural network (DNN) based models have proved to be useful in load forecasting problems. In [14], authors use a DNN based model for load forecasting that was trained in two different ways - using a pre-trained restricted Boltzmann machine (RBM) and using the rectified linear unit (ReLu) without pre-training. To better capture the temporal dependencies from historical load data, some state-of-the-art deep learning models have been proposed - recurrent neural networks (RNN) [5, 15, 16], long short term memory (LSTM) [9, 10, 13] and convolutional neural networks (CNN) [2, 3]. In [10] LSTM based predictive models have been used for individual house level forecasts and aggregate level forecasts. Authors show that as the level of aggregation decreases, the accuracy drops but do not state a reason for the same. However later in [9], authors say that accuracy at individual house level can be improved if appliance readings of the house are included in training data. Rahman et al. in [13] has shown that in addition to short term dependencies, LSTM models can capture long term dependencies by obtaining long-term hour ahead forecasts in case of energy buildings. However the RNN and LSTM based models have long training time and suffers from overfitting due to vanishing gradient problem. The advantage of CNN over other two popular DNN based models is that CNN can be trained efficiently on a smaller training dataset without compromising the performance and the over fitting issue. Though the sliding filters in CNN helps to identify the patterns from historic load data for future load prediction, to access a broader range of history to capture the trend and seasonality, Borovykh et al. in [3] used dilated convolutional neural network (DCNN) for the first time in load forecasting problem. Inspired by Wavenet architecture [11], the DCNN based model in [3] called Augmented Wavenet, has a deep stack of dilated convolution layers which comprehends from a wide range of historic data when forecasting the future values.
In this paper we study the problem of load forecasting at the building level using deep CNNs where the forecasted values can follow the trend and seasonality present in historic data. Motivated by the Augmented Wavenet model [3], which can learn from the broader historic data, the proposed model - Dilated Convolutional Dense Network (DaNSe), is designed using multiple dilated causal convolutional layers with residuals and parameterized skip connections and multiple fully connected layers in the output. Dilation operation extensively captures the historic data for output predictions. The residuals and parameterized skip connections in each layer of the proposed model, speeds up convergence and train the deeper layers without over fitting. Reportedly, the only work that is similar to the proposed model is the SeriesNet architecture [12] that is an enhancement of the Augmented Wavenet model and use parameterized skip connections from each dilated convolutional layer to output layer. As compared to the SeriesNet architecture [12], the proposed model can better capture the non-linear trend and seasonality in the time series data resulting in improved accuracy. Experiments on synthetic and real life time series datasets show the improvement of proposed model over the existing SeriesNet model. This paper has been arranged as follows. Section 2 explains the state of the art techniques followed by architectural details of proposed model - DaNSe. Section 3 reports the experiment and results followed by conclusions and future work in Sect. 4.
2 Methodology
The proposed deep learning model Dilated Convolutional Dense Network (DaNSe), is designed using stacked dilated causal layers with residual connection and SeLU activation followed by fully-connected layers with ReLu activation. The key components of the DaNSe model is discussed below.

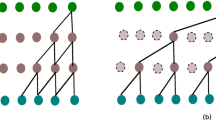
(a) DaNSe architecture (b) A resnet block
-
Dilated Convolutional Neural Networks (DCNN): The dilated convolution operator has been referred in the past as “convolution with dilated filter”. Dilated filter is an up-sampling of convolution filter by injecting predefined gaps between the filter weights. The term causal with dilated networks intends to maintain the ordering in time series data [11]. Dilated convolution of two functions f() and g() in one-dimensional space, is represented as:
$$\begin{aligned} (f*g)(t)=\sum _{t=-\infty }^{\infty } f(t) g(t-lx) \end{aligned}$$(1)where the multiplier l is said to be the l-dilated convolution.
-
Residual Connections: As the number of layers are increased in deep models, a degradation in accuracy signifies that the shallower counterpart of network is learning well but not the deeper counterpart. In order to construct the deeper counterpart of a shallower network, an idea of skip connections or residual connections between the layers has been proposed in [7]. If F(x) is the underlying mapping of the model for input x, the stacked non-linear layers is used to fit another mapping: \(R(x)=F(x)-x\), which is easier to optimize. Hence the original mapping is: \(F(x)=R(x)+x\). Figure 1b shows a residual block.
-
Activations: The activation functions used in the model are:
-
Rectified linear unit (ReLu): A linear activation that will output the input, when it is positive else the output is zero. If x is the input \(relu(x)=max(0,x)\).
-
Scaled Exponential Linear Unit (SeLU): SeLU pushes the neuron activations towards zero mean and unit variance [8], integrating a self normalizing property. Activation function SeLU is represented as:
$$\begin{aligned} \text {selu(x)\,=\,}\gamma {\left\{ \begin{array}{ll} \alpha (\mathrm{e}^x-1) \text { for x} \le 0\\ x \text { for x} \ge 0 \end{array}\right. } \end{aligned}$$(2)where \(\alpha \) and \(\gamma \) are the fixed parameters derived from inputs with mean 0 and standard deviation 1.
-
-
 Fig. 1a shows the model architecture. Model has stacked dilated causal layers with residual connection from input to output, the sum of which is input to next dilated causal layer. The output of SeLU activation of each layer is parameterized by \(1 \times 1\) convolution, which is then summed up and fed to fully-connected layers followed by \(1\times 1\) convolution for obtaining the final output. Instead to passing the sum directly into ReLu activation as in SeriesNet [12], fully connected layers helps reducing the sparsity of ReLu activation and gives accurate predictions. \(80\%\) dropout has been used in the last two layers of the model to reduce the over fitting problem. Model weights are learned by minimizing mean absolute error (MAE) with L2 regularization that penalize large weights to avoid over fitting. Model uses adaptive momentum (Adam) optimization technique where the weight updates are given as: $$\begin{aligned} \varDelta w_t=-\eta \bigg (v_t / \sqrt{s_t+\epsilon }\bigg ) g_t \end{aligned}$$(3)
Fig. 1a shows the model architecture. Model has stacked dilated causal layers with residual connection from input to output, the sum of which is input to next dilated causal layer. The output of SeLU activation of each layer is parameterized by \(1 \times 1\) convolution, which is then summed up and fed to fully-connected layers followed by \(1\times 1\) convolution for obtaining the final output. Instead to passing the sum directly into ReLu activation as in SeriesNet [12], fully connected layers helps reducing the sparsity of ReLu activation and gives accurate predictions. \(80\%\) dropout has been used in the last two layers of the model to reduce the over fitting problem. Model weights are learned by minimizing mean absolute error (MAE) with L2 regularization that penalize large weights to avoid over fitting. Model uses adaptive momentum (Adam) optimization technique where the weight updates are given as: $$\begin{aligned} \varDelta w_t=-\eta \bigg (v_t / \sqrt{s_t+\epsilon }\bigg ) g_t \end{aligned}$$(3)where \(\varDelta w_t\) is the gradient for weight \(w_t\), \(\eta \) is the learning rate, \(v_t\) is exponential average of gradients along \(w_t\), \(s_t\) is exponential average of squares of gradients along \(w_t\), \(g_t\) is the gradient along \(w_t\) at time t and \(\epsilon \) being a constant.
 Fig.
Fig. 3 Experiment and Results
3.1 Experimental Setup
The data sets used in the experiment and the metrics used for measuring the performances are discussed below. The reported metric values are averaged over 10 runs.
-
Data Description: Model has been tested on three different datasets - CIF 2016 competition dataset [6], CER-IRISH SME dataset [1] and a Turkish electricity data [4]. CIF-2016 benchmark dataset comprises of 72 real and synthetic time series with monthly periods varying length between 23 to 108 months. Commission of Energy Regulation (CER) IRISH comprises of half hourly power readings of 311 SMEs of Ireland during the period of 2009-10. Turkish electricity load data has daily load (in MW) for a period of nine years from 2000 to 2008 [4] with dual seasonality- a weekly and an yearly.
-
Error Metrics: The error metrics used in the comparative study are SMAPE and distribution of APE as discussed below.
-
1.
Symmetric mean absolute percentage error (SMAPE): SMAPE is represented as below. SMAPE values ranges from 0 to 1. Lower valued SMAPE indicates better matching between forecasts and actuals.
$$\begin{aligned} SMAPE=\frac{1}{N}\sum _{i=1}^{N}\bigg (\frac{1}{n}\sum _{t=1}^{n}\frac{\mid F_t-A_t \mid }{(\mid F_t \mid + \mid A_t \mid )/2}\bigg ) \end{aligned}$$(4)where, \(A_t\) and \(F_t\) are actual and forecast values respectively. n represents the length of time series and N is the number of individual time series values being considered.
-
2.
Absolute percentage error (APE): In order to quantify the error distribution in individual time series data we introduced APE, described below.
$$\begin{aligned} APE=\frac{1}{n}\sum _{t=1}^{n}\frac{\mid F_t-A_t \mid }{(\mid F_t \mid + \mid A_t \mid )/2} \end{aligned}$$(5)where, \(A_t\) and \(F_t\) are the actual and forecast values respectively. n represents the length of time series data.
-
1.
-
Hyper-parameter selection and model training: Initial weights of the proposed model are chosen randomly from a truncated normal distribution with zero mean and 0.05 standard deviation. L2 regularization factor of 0.001 is used. Proposed model has seven dilated causal layers with varying filter sizes. Initial three layers with filter width of 2 is intended to capture short duration trend or seasonal patterns in time series data, however to capture the longer duration trend, seasonal patterns and cyclic periodicities, filter width 4, seemed adequate. We used three fully connected layers, each with 32 hidden units and ReLu activations. The proposed model has been trained for 3000 epochs.
-
Data Preprocessing: CIF-2016 data required no pre-processing, minimum pre-processing has been carried out on other two datasets. SME dataset had missing values which we replaced by moving averages. For our study, we converted the half-hourly power readings of SMEs into hourly data. Train and test sets for the CIF-2016 data has been predefined. For SMEs, we kept the last 24 h as test set and for the Turkish electricity data, we kept last one year as the test set.
3.2 Results and Analysis
As shown in the Table 1, proposed model DaNSe significantly outperforms SeriesNet for SME and Turkish electricity data while the performance is comparable for CIF-2016 dataset. In case of SME and Turkish electricity data, DaNSe efficiently learns multiple seasonalities in the data giving better results. The time required for achieving this performance gain in DaNSe is same as that of SeriesNet architecture. DaNSe has also shown improved performance over other classical single layered CNN and LSTM models. Reason for improved performance in DaNSe is because the fully connected layers helps reducing the sparsity of ReLu activation giving an improved performance.

Error distribution plot for SMEs, CIF-2016 and Turkish electricity data
We further analyze the error distribution for all the three datasets in terms of APE error, shown in Fig. 2. Outliers noticed in case of CIF-2016 data for both the models, is due to the time series that have less 6 months training data. In case of SMEs, we found high error rate for SeriesNet when there exists cyclic periodicity in the data. Turkish electricity has a single nine year dataset, DaNSe shows significant improvement as that of SeriesNet.

Plot for comparison of DaNSe and SeriesNet in case of SME, CIF-2016 and Turkish electricity datasets.
Further we analyze the performance of a few randomly selected time series from CIF-2016 and SME data. In Fig. 3, the actual versus predicted consumption is shown for 4 randomly chosen time series of CIF-2016 dataset. As shown in the Fig. 3, time series 13 and 19 has linear increasing trend while time series 6 and 30 has non-linear damping trend pattern. DaNSe architecture significantly outperformed in all cases particularly for non-linear damping pattern.
The actual versus predicted consumption for 4 randomly chosen meter IDs of SME dataset has also been shown in Fig. 3. The proposed model is successful in capturing daily and weekly seasonality for meter ID 4623 and 6939 and 2687. Though for meter ID 2242, both methods exhibit degraded performance due to cyclic behavior in data while in rest of the meter IDs, proposed model significantly outperforms SeriesNet.
Figure 3 shows that the proposed model has \(33\%\) higher accuracy than the SeriesNet. The weekly seasonality has been efficiently learned by the proposed model as compared to that of yearly seasonal pattern.
4 Conclusions and Future Work
In this work, we propose a dilated causal convolutional network model with fully-connected layers for load forecasting. The proposed model named as DaNSe architecture achieves \(33\%\) higher accuracy over the existing SeriesNet architecture [12]. Plugging the fully connected layers with a combination of SeLU and ReLU non-linear activation has shown significant improvement as compared to that in SeriesNet architecture. The lower layers of the model, having small filter width learns the patterns with small periodicity in the data while the higher layers, with larger filter widths, learn the patterns with larger periodicity. The proposed model gives more accurate results in case of short as well as long seasonal patterns as compared to SeriesNet.
As future improvement to DaNSe model, we aim to explore its performance in case of varying forecast horizons, apply the distributed learning approaches and automate the hyper-parameter tuning. We also aim to explore the possibilities of incorporating gated memory layers capable to learn the cyclic periodicity present in the time series data.
References
Electricity smart metering technology trials findings report (2011). https://www.ucd.ie/t4cms/Electricity%20Smart%20Metering%20Technology%20Trials%20Findings%20Report.pdf
Amarasinghe, K., Marino, D.L., Manic, M.: Deep neural networks for energy load forecasting. In: 2017 IEEE 26th International Symposium on Industrial Electronics (ISIE), pp. 1483–1488. IEEE (2017)
Borovykh, A., Bohte, S., Oosterlee, C.W.: Conditional time series forecasting with convolutional neural networks. arXiv preprint arXiv:1703.04691 (2017)
De Livera, A.M., Hyndman, R.J., Snyder, R.D.: Forecasting time series with complex seasonal patterns using exponential smoothing. J. Am. Stat. Assoc. 106(496), 1513–1527 (2011)
Fan, C., Wang, J., Gang, W., Li, S.: Assessment of deep recurrent neural network-based strategies for short-term building energy predictions. Appl. Energy 236, 700–710 (2019)
Computational Intelligence in Forecasting: CIF 2016 (2016). http://irafm.osu.cz/cif/main.php
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Klambauer, G., Unterthiner, T., Mayr, A., Hochreiter, S.: Self-normalizing neural networks. In: Advances in Neural Information Processing Systems, pp. 971–980 (2017)
Kong, W., Dong, Z.Y., Hill, D.J., Luo, F., Xu, Y.: Short-term residential load forecasting based on resident behaviour learning. IEEE Trans. Power Syst. 33(1), 1087–1088 (2018)
Kong, W., Dong, Z.Y., Jia, Y., Hill, D.J., Xu, Y., Zhang, Y.: Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans. Smart Grid 10, 841–851 (2017)
Oord, A.V.D., et al.: WaveNet: a generative model for raw audio. arXiv preprint arXiv:1609.03499 (2016)
Papadopoulos, K.: Seriesnet: a dilated causal convolutional neural network for forecasting. https://github.com/kristpapadopoulos/seriesnet (2018)
Rahman, A., Srikumar, V., Smith, A.D.: Predicting electricity consumption for commercial and residential buildings using deep recurrent neural networks. Appl. Energy 212, 372–385 (2018)
Ryu, S., Noh, J., Kim, H.: Deep neural network based demand side short term load forecasting. Energies 10(1), 3 (2016)
Shi, H., Xu, M., Li, R.: Deep learning for household load forecasting-a novel pooling deep RNN. IEEE Trans. Smart Grid 9(5), 5271–5280 (2018)
Zhang, B., Wu, J.L., Chang, P.C.: A multiple time series-based recurrent neural network for short-term load forecasting. Soft. Comput. 22(12), 4099–4112 (2018)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Mishra, K., Basu, S., Maulik, U. (2019). DaNSe: A Dilated Causal Convolutional Network Based Model for Load Forecasting. In: Deka, B., Maji, P., Mitra, S., Bhattacharyya, D., Bora, P., Pal, S. (eds) Pattern Recognition and Machine Intelligence. PReMI 2019. Lecture Notes in Computer Science(), vol 11941. Springer, Cham. https://doi.org/10.1007/978-3-030-34869-4_26
Download citation
DOI: https://doi.org/10.1007/978-3-030-34869-4_26
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-34868-7
Online ISBN: 978-3-030-34869-4
eBook Packages: Computer ScienceComputer Science (R0)
