
Abstract
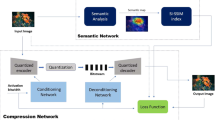
Recent researches have shown that deep convolutional neural networks (CNN) have achieved promising results in the field of image compression. In this paper, we propose an end-to-end image compression framework based on effective attention modules. In the proposed method, two channel attention mechanisms are employed jointly. The first is the Squeeze-and-Excitation block (SEblock) in the encoder. The other is the novel inversed SEblock (ISEblock) placed in decoder. These blocks, named coupled SEblocks, are placed behind the convolutional layer in both encoder and decoder. By using SEblocks, the encoder learns the interdependencies between different channels and the feature maps can be better distributed after entropy coding. In decoder, the inversed SEblock is employed which adaptively learns the weights and divides weights between the channels to supplement information compressed from the encoder. The whole network is trained as a joint rate-distortion optimization by using a subset of the ImageNet dataset. We evaluate our method on public Kodak test set. At low bit rates, our approach outperforms the existing Ballè’s, JPEG, JPEG2000 and WebP on multi-scale structural similarity (MS-SSIM) and gets good visual qualities for all images at test set.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Wallace, G.K.: The jpeg still picture compression standard. IEEE Trans. Consum. Electron. 38(1), xviii–xxxiv (1992)
Skodras, A., Christopoulos, C., Ebrahimi, T.: The jpeg 2000 still image compression standard. IEEE Signal Process. Mag. 18(5), 36–58 (2001)
Google.: WebP: Compression techniques (2017). http://developers.google.com/speed/webp/docs/compression. Accessed 30 Jan 2017
Foi, A., Katkovnik, V., Egiazarian, K.: Pointwise shape-adaptive DCT for high-quality denoising and deblocking of grayscale and color images. IEEE Trans. Image Process. 16(5), 1395–1441 (2007)
Zhang, X., Xiong, R., Ma, S., Gao, W.: Reducing blocking artifacts in compressed images via transform-domain non-local coefficients estimation. In: IEEE International Conference on Multimedia and Expo (ICME), pp. 836–841 (2012)
Zhang, X., Xiong, R., Fan, X., Ma, S., Gao, W.: Compression artifact reduction by overlapped-block transform coefficient estimation with block similarity. IEEE Trans. Image Process. 22(12), 4613–4626 (2013)
Zhang, X., Xiong, R., Zhao, G., Zhang, Y., Ma, S., Gao, W.: CONCOLOR: Constrained non-convex low-rank model for image deblocking. IEEE Trans. Image Process. 25(3), 1246–1259 (2016)
Dong, C., Loy, C.C., He, K., Tang, X.: Learning a deep convolutional network for image super-resolution. In: European Conference on Computer Vision (ECCV), pp. 184–199 (2014)
Dong, C., Loy, C.C., He, K., Tang, X.: Compression artifacts reduction by a deep convolutional network. In: IEEE International Conference on Computer Vision (ICCV), pp. 576–584 (2015)
Toderici, G., et al.: Variable rate image compression with recurrent neural networks. In: International Conference on Learning Representations (ICLR). arXiv: 1511.06085 (2015)
Toderici, G., et al.: Full resolution image compression with recurrent neural networks. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5435–5443 (2017)
Ballé, J., Laparra, V., Simoncelli, E.P.: End-to-end optimized image compression. In: International Conference on Learning Representations (ICLR). arXiv: 1608.05148 (2016)
Theis, L., Shi, W., Cunningham, A., Huszár, F.: Lossy image compression with compressive autoencoders. In: International Conference on Learning Representations (ICLR). arXiv:1703.00395 (2017)
Li, M., Zuo, W., Gu, S., Zhao, D., Zhang, D.: Learning convolutional networks for content-weighted image compression. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3214–3223 (2018)
Mentzer, F., Agustsson, E., Tschannen, M., Timofte, R., Van Gool, L.: Conditional probability models for deep image compression. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4394–4402 (2018)
Hu, J., Shen, L., Albanie, S., Sun, G., Wu, E.: Squeeze-and-excitation networks. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7132–7141 (2018)
Park, J., Woo, S., Lee, J.Y., Kweon, I.S.: BAM: Bottleneck Attention Module. In: The British Machine Vision Conference (BMVC). arXiv:1807.06514 (2018)
Hinton, G. E.: Rectified linear units improve restricted boltzmann machines. In: International Conference on International Conference on Machine Learning (ICML), pp. 807–814 (2010)
Eastman Kodak.: Kodak Lossless True Color Image Suite (2012). http://r0k.us/graphics/kodak. Accessed Oct 2012
Marpe, D., Schwarz, H., Wiegand, T.: Context-based adaptive binary arithmetic coding in the h.264/avc video compression standard. IEEE Trans. Circuits Syst. Video Technol. 13(7), 620–636 (2003)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Du, J., Xu, Y., Wei, Z. (2019). Coupled Squeeze-and-Excitation Blocks Based CNN for Image Compression. In: Cui, Z., Pan, J., Zhang, S., Xiao, L., Yang, J. (eds) Intelligence Science and Big Data Engineering. Visual Data Engineering. IScIDE 2019. Lecture Notes in Computer Science(), vol 11935. Springer, Cham. https://doi.org/10.1007/978-3-030-36189-1_17
Download citation
DOI: https://doi.org/10.1007/978-3-030-36189-1_17
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-36188-4
Online ISBN: 978-3-030-36189-1
eBook Packages: Computer ScienceComputer Science (R0)