
Abstract
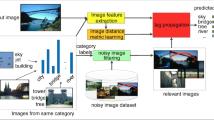
The existing image feature extraction methods are primarily based on the content and structure information of images, and rarely consider the contextual semantic information. Regarding some types of images such as scenes and objects, the annotations and descriptions of them available on the web may provide reliable contextual semantic information for feature extraction. In this paper, we introduce novel semantic features of an image based on the annotations and descriptions of its similar images available on the web. Specifically, we propose a new method which consists of two consecutive steps to extract our semantic features. For each image in the training set, we initially search the top k most similar images from the internet and extract their annotations/descriptions (e.g., tags or keywords). The annotation information is employed to design a filter bank for each image category and generate filter words (codebook). Finally, each image is represented by the histogram of the occurrences of filter words in all categories. We evaluate the performance of the proposed features in scene image classification on three commonly-used scene image datasets (i.e., MIT-67, Scene15 and Event8). Our method typically produces a lower feature dimension than existing feature extraction methods. Experimental results show that the proposed features generate better classification accuracies than vision based and tag based features, and comparable results to deep learning based features.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Bojanowski, P., Grave, E., Joulin, A., Mikolov, T.: Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 5, 135–146 (2017)
Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), pp. 886–893 (2005)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: Proceedings IEEE Conference Computer Vision and Pattern Recognition (CVPR) (2009)
Fei-Fei, L., Perona, P.: A Bayesian hierarchical model for learning natural scene categories. In: Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), vol. 2, pp. 524–531, June 2005
Gong, Y., Wang, L., Guo, R., Lazebnik, S.: Multi-scale orderless pooling of deep convolutional activation features. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8695, pp. 392–407. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10584-0_26
Guo, S., Huang, W., Wang, L., Qiao, Y.: Locally supervised deep hybrid model for scene recognition. IEEE Trans. Image Process. 26(2), 808–820 (2017)
Guo, Y., Liu, Y., Lao, S., Bakker, E.M., Bai, L., Lew, M.S.: Bag of surrogate parts feature for visual recognition. IEEE Trans. Multimedia 20(6), 1525–1536 (2018)
Hartigan, J.A.: Clustering Algorithms, 99th edn. Wiley, New York (1975)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778 (2016)
Hearst, M.A.: Support vector machines. IEEE Intell. Syst. 13(4), 18–28 (1998)
Huang, A.: Similarity measures for text document clustering. In: Proceedings of Sixth New Zealand Computer Science Research Student Conference (NZCSRSC 2008), pp. 9–56 (2008)
Juneja, M., Vedaldi, A., Jawahar, C., Zisserman, A.: Blocks that shout: distinctive parts for scene classification. In: Proceedings of IEEE Conference Computer Vision Pattern Recognition (CVPR), pp. 923–930, June 2013
Khan, S.H., Hayat, M., Bennamoun, M., Togneri, R., Sohel, F.A.: A discriminative representation of convolutional features for indoor scene recognition. IEEE Trans. Image Process. 25(7), 3372–3383 (2016)
Kim, Y.: Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882 (2014)
Kuzborskij, I., Maria Carlucci, F., Caputo, B.: When Naive Bayes nearest neighbors meet convolutional neural networks. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2100–2109 (2016)
Lazebnik, S., Schmid, C., Ponce, J.: Beyond bags of features: spatial pyramid matching for recognizing natural scene categories. In: Proceedings of IEEE Computer Society Conference on Computer Vision Pattern Recognition, pp. 2169–2178, June 2006
Li, L.J., Li, F.F.: What, where and who? Classifying events by scene and object recognition. In: ICCV, vol. 2, p. 6 (2007)
Li, L.J., Su, H., Fei-Fei, L., Xing, E.P.: Object bank: a high-level image representation for scene classification & semantic feature sparsification. In: Proceedings of Advance Neural Information Processing Systems (NIPS), pp. 1378–1386 (2010)
Lin, D., Lu, C., Liao, R., Jia, J.: Learning important spatial pooling regions for scene classification. In: Proceedings of IEEE Conference Computer Vision Pattern Recognition (CVPR), pp. 3726–3733, June 2014
Lin, T.Y., RoyChowdhury, A., Maji, S.: Bilinear convolutional neural networks for fine-grained visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 40(6), 1309–1322 (2018)
Margolin, R., Zelnik-Manor, L., Tal, A.: OTC: a novel local descriptor for scene classification. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8695, pp. 377–391. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10584-0_25
Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 (2013)
Miller, G.A.: WordNet: a lexical database for English. Commun. ACM 38(11), 39–41 (1995)
Oliva, A.: Gist of the scene. In: Neurobiology of Attention, pp. 251–256. Elsevier (2005)
Oliva, A., Torralba, A.: Modeling the shape of the scene: a holistic representation of the spatial envelope. Int. J. Comput. Vis. 42(3), 145–175 (2001)
Parizi, N., Oberlin, J.G., Felzenszwalb, P.F.: Reconfigurable models for scene recognition. In: Proceedings of Computer Vision Pattern Recognition (CVPR), pp. 2775–2782, June 2012
Patel, A., Sands, A., Callison-Burch, C., Apidianaki, M.: Magnitude: a fast, efficient universal vector embedding utility package. In: Proceedings Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 120–126 (2018)
Pennington, J., Socher, R., Manning, C.: Glove: global vectors for word representation. In: Proceedings of 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1532–1543 (2014)
Perronnin, F., Sánchez, J., Mensink, T.: Improving the fisher kernel for large-scale image classification. In: Daniilidis, K., Maragos, P., Paragios, N. (eds.) ECCV 2010. LNCS, vol. 6314, pp. 143–156. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-15561-1_11
Quattoni, A., Torralba, A.: Recognizing indoor scenes. In: Proceedings of IEEE Conference Computer Vision Pattern Recognition (CVPR), pp. 413–420, June 2009
ShenghuaGao, I.H., Liang-TienChia, P.: Local features are not lonely-Laplacian sparse coding for image classification, pp. 3555–3561 (2010)
Sitaula, C., Xiang, Y., Aryal, S., Lu, X.: Unsupervised deep features for privacy image classification. arXiv preprint arXiv:1909.10708 (2019)
Sitaula, C., Xiang, Y., Zhang, Y., Lu, X., Aryal, S.: Indoor image representation by high-level semantic features. IEEE Access 7, 84967–84979 (2019)
Tang, P., Wang, H., Kwong, S.: G-MS2F: GoogLeNet based multi-stage feature fusion of deep CNN for scene recognition. Neurocomputing 225, 188–197 (2017)
Wang, D., Mao, K.: Task-generic semantic convolutional neural network for web text-aided image classification. Neurocomputing 329, 103–115 (2019)
Wang, D., Mao, K.: Learning semantic text features for web text aided image classification. IEEE Trans. Multimedia PP, 1 (2019)
Wu, J., Rehg, J.M.: CENTRIST: a visual descriptor for scene categorization. IEEE Trans. Pattern Anal. Mach. Intell. 33(8), 1489–1501 (2011)
Xiao, Y., Wu, J., Yuan, J.: mCENTRIST: a multi-channel feature generation mechanism for scene categorization. IEEE Trans. Image Process. 23(2), 823–836 (2014)
Zeglazi, O., Amine, A., Rziza, M.: Sift descriptors modeling and application in texture image classification. In: Proceedings of 13th International Conference Computer Graphics, Imaging and Visualization (CGiV), pp. 265–268, March 2016
Zhang, C., Zhu, G., Huang, Q., Tian, Q.: Image classification by search with explicitly and implicitly semantic representations. Inf. Sci. 376, 125–135 (2017)
Zhou, B., Khosla, A., Lapedriza, A., Torralba, A., Oliva, A.: Places: An image database for deep scene understanding. arXiv preprint arXiv:1610.02055 (2016)
Zhu, J., Li, L.J., Fei-Fei, L., Xing, E.P.: Large margin learning of upstream scene understanding models. In: Proceedings of Advance Neural Information Processing Systems (NIPS), pp. 2586–2594 (2010)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Sitaula, C., Xiang, Y., Basnet, A., Aryal, S., Lu, X. (2019). Tag-Based Semantic Features for Scene Image Classification. In: Gedeon, T., Wong, K., Lee, M. (eds) Neural Information Processing. ICONIP 2019. Lecture Notes in Computer Science(), vol 11955. Springer, Cham. https://doi.org/10.1007/978-3-030-36718-3_8
Download citation
DOI: https://doi.org/10.1007/978-3-030-36718-3_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-36717-6
Online ISBN: 978-3-030-36718-3
eBook Packages: Computer ScienceComputer Science (R0)