
Abstract
Traditionally, elections polls have been widely used to analyse trend and to predict likely election results. However, these methods are very expensive and labour intensive. With the widespread development of several social media platforms, a large amount of unstructured data become easily available, which in turn could be processed and analysed to extract meaningful information about several topics and events such as election, sports, natural hazards etc. Hence, in this study, we utilise twitter data to analyse the 2019 Indian general election and to predict possible outcomes. We have collected 41 million election related tweets during the months of April and May 2019. The proposed approach works by initially performing hashtags based tweets segregation to generate data for training the classification model. Subsequently, we augment different word embeddings with deep learning classification model to support improved classification accuracy. The model achieves 87.30% classification accuracy in amalgamation with fasttext word embedding. Finally, the opinion analysis is performed on the classified tweets to determine possible election outcomes. To evaluate our proposed model, the output results are validated with the available ground truth and have shown a close correlation to the actual results. Furthermore, we have also performed an in-depth analysis of the selected political parties tweets, to provide an insight into top trending hashtags and mentions used by people during election campaigns.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Sentiment analysis
- Deep learning
- LSTM
- Indian general election 2019
- Lok Sabha election
- Bhartiya Janta Party (BJP)
- Indian National Congress (INC)
1 Introduction
In the year 2019, the tenure of the \(16^{th}\) Lok Sabha got completed and India, the world’s largest democracy witnessed \(17^{th}\) Lok Sabha election in the year 2019. These elections were held in the seven phases for the 546 parliament constituencies during the month of April and May; the first one held on April 19, 2019 and the last phase held on May 19, 2019. For any party, these general elections are the biggest exercise to form government at the center (by winning 272 seats or by proving majority with the help of alliances) and thus elect the Prime Minister of India. The main responsibility for conducting elections in a fair manner lies in the hands of the Election Commission of India (ECI). Even though the number of parties registered for the general elections with the ECI has increased to 2354 as compared to 1616 in the year 2014, the main battle is between some major parties namely Bhartiya Janta Party (BJP), Indian National Congress (INC) and some other national parties Aam Aadmi Party, Mahagathbandhan (alliance of several parties like Samajwadi party, Bahujan Samaj party and many more).
In the year 2019, the general elections were different from the previous elections in various ways. Firstly, the people of India were highly inclined towards the positive governance of the current PM Narendra Modi (BJP). Secondly, the various alliances were formed to oppose the current governing party BJP. Thirdly, in the last few years, it has been seen that political parties are increasingly engaging in dialogues with people over social media platforms (specifically Twitter) and people are also increasingly using social platforms to express their views on different political topics. Majority of the political parties leaders/candidates have verified accounts and pages on Twitter, which they are using for their party campaigns.
With the increasing popularity of social media platforms for expressing views or opinions, information dissemination and social interactions, a large amount of real-time data becomes easily available. Over the election duration, this real-time data can be analysed to determine people semantics or opinions on the different political parties or political orientations of the people, which in turn could provide beneficial information on the election results. Hence, there is a need for an automated system that could efficiently utilise such real-time tweet data to predict election results. In the current work, we propose a system to serve the desired purpose. The main research contribution of this work can be summarised as follows:
-
Over the decades, standard methods such as polls, surveys have been widely used for predicting election results. Despite being accurate and reliable, these methods require more efforts, costly and are time consuming. Hence, in current work, we propose Twitter as a reliable platform to predict election results from people tweets sentiments/opinions.
-
In the current work, we proposed a semi-automated hashtag based approach to initially segregate tweets for building sentiment classification model (to support supervised learning).
-
The current work combines deep learning based classification model (Long Short Term Memory Network) with different word embeddings to provide support for improved prediction accuracy.
-
In the current work, we perform the State-wise analysis of people opinions on two main national parties of India (BJP and Congress).
-
To evaluate the reliability and accuracy of the proposed work, a comparative analysis has been performed between the prediction results and available ground truth.
2 Literature Review
Election results prediction has emerged as a significant area of research in the last few years. Traditional studies in the field have implemented econometric methods to predict election results through demographic information. However, with the emergence of social media platform, real-time people opinions data has become the enrich source of information [9]. This real-time information can be efficiently analysed for the task of decision making and results prediction [1, 3, 13, 20]. In literature, a number of research studies have been implemented on the election related twitter data and some of them are as follows:
Srivastva et al. [20] analysed social network content for analyzing Delhi assembly elections 2015 and trained classification model on the manually annotated dataset for predicting election outcomes. The prediction results are evaluated on the basis of the root-mean squared performance measure. Jose et al. [13] proposed a lexicon analysis or word sense disambiguation based approach for election results prediction. Amit et al. [4] they have performed geo-spatial sentiment analysis for UK-EU referendum by utilizing the Twitter data. Mehndiratta et al. [16] performed twitter based sentiment analysis over 0.25 million public tweets in reference to different politicians or political parties for the 2014 general elections. Ahmed et al. [6] investigate the use of Twitter as a tool for campaigns during the 2014 elections. The study aims to find answers to several research queries including: identifying the party that most frequently uses twitter for campaigns, to identify the dominant issues or topics and many other related queries. Khatua et al. [15] performed sentiment analysis on the 2014 election related data. The author investigated whether Twitter data predict the outcomes of the elections. From the research results of this paper following inferences were drawn: (a) Twitter can serve as an efficient tool for predicting election results (b) Out of the tweet volume and sentiment score, sentiment score can be used as an effective predictor of vote swing.
Ibrahim et al. [12] integrated buzzer (bot) detection tool with twitter analysis to predict results for Indonesia Presidential elections. On the basis of experimental results, the authors have stated that Twitter can serve as an important tool for any political activities. Tsakalidis et al. [22] proposed a novel approach that combined twitter data with opinion polls for Germany, Netherlands and Greece 2014 election results prediction. The model treated twitter based features as time series and implemented three different forecasting models to predict the target results. The output results have proven the effectiveness of combining twitter based features with polls by generating minimum prediction error. Burnap et al. [8] combined prior party support data with current twitter results to predict UK 2015 election results. The approach work by initially calculating tweets and Leader based sentiment score, which in turn are combined to generate party overall positive sentiment score. Subsequently, the integration of the UK 2010 election results with current sentiment scores is utilised to make constituency based election results prediction.
Ebrahimi et al. [10] listed several challenges that occurs while performing sentiment analysis on dynamic events such as elections such as candidate dependency (name of both candidates in the same tweet), identifying users’ political preferences, availability of limited training dataset and interpretation related challenges. Paul et al. [18] performed spatio-temporal analysis of US elections. The approach combined machine learning models with twitter sentiment analysis for results prediction. The approach works by initially segregating tweets on the basis of their relevance to the target event. Subsequently, sentiment analysis is applied to calculate sentiment polarity related to each tweet. Finally, after being processed by burst event and spatio-temporal analytic modules, machine learning models are trained to the learn abstract representation of the data, which in turn were used for results prediction. The approach provided a prediction accuracy of 84.4%.
As listed above, a number of research studies have been performed on election results prediction and sentiment analysis. However, the majority of these research studies have targeted at United States (US) elections and very limited research work has been carried out on India’s general election. Furthermore, to the best of our knowledge, no previous studies have augmented deep learning models with twitter data for election results prediction or target labeled data generation on India’s election. Hence, in the current work, we proposed a twitter data based hybrid approach for election results prediction while resolving all major issues associated with analysis on dynamic events (as mentioned in). In addition to this, the current approach combines deep learning model with different word embeddings to achieve 87.30% classification accuracy.
3 Methodology
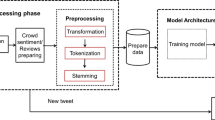
In this section, we explicate the methodology of the proposed election results prediction approach. Figure 1 shows the broad level diagram of the methodology.

Methodology of the proposed approach for election results prediction.
3.1 Dataset Collection
We have collected data by using the Twitter streaming API. Data crawling can be done in two ways, i.e. by using hashtags and the other one by using bounding box. In this study, we collected dataset of \(17^{th}\) Lok Sabha election which held in seven phases for 546 parliament constituencies. We have crawled the dataset by using the hashtags corresponding to BJP and INC. Hashtags used for BJP are (‘narendramodi’, ‘narendramodi_in’, ‘BJP4India’, ‘modi’, ‘NDA’, ‘BJP’) whereas hashtags used for INC are (‘RahulGandhi’, ‘Congress’, ‘INCIndia’, ‘INC’) and collected around 41 million tweets during April 5-2019 to May-20-2019. Since, collected tweets contains a lot of meta information itself which is off no use. So while downloading the tweets we store only useful information such as userid, tweetid, tweet, location, date and time, RT count, Fav count, hashtags, mentions. After that, we have performed data pre-possessing over the collected tweets.
Data Preprocessing: Twitter post are generally informal, brief, unstructured and often contain grammatical mistakes, misspelling and a lot of noise. It might be due to the 140 character limit imposed on tweets previously, but on November 7, 2017, the restriction is doubled for most of the languages except Chinese, Japanese, and Korean. Authors from the previous studies claim that users knowingly use the abbreviation, shortened, slang words and also uses an amalgamation of prefix and suffix of the word. So it becomes very cumbersome to understand some of the tweets like “Hvy trafic at strt of andheri brdge going 2wrds aiprt & further”. Previously Agarwal et al. [2, 5] and Subramainum et al. [21] uses different text mining techniques like edit Distance, Longest Common Subsequence and Prefix_Suffix match to handle noisy text in SMS. We have used the same approach so that it could be converted to a readable form like “Heavy traffic at start of andheri bridge going towards airport & further”. The various steps involved in data pre-processing are as follows:
-
“@” is used in Tweet by user to tag or refer other twitter users so that they may follow on the tweet. So we remove “@” from the tweets.
-
#hashtags were used by users before any relevant keyword or phrase to categorize their tweets and show their tweets more easily in twitter search. So hashtags symbol # were removed as they carry no relevance.
-
“URL” it is used to shared other web resource. But they carry no relevance information. So we remove it.
-
Remove all non-alphabetic terms and stop words (except only Userid, Tweetid, date and time).
-
Remove all the repeated characters like (“Trafficcccc” for “traf- fic”), (“stuckkkk” for “stuck”).
-
Replacement of Abbreviation and Slang words
-
Convert all the characters in to lower case.
3.2 Hashtags Based Tweets Segregation
Hashtags play a predominant role in the identification and characterisation of the tweets. They are basically synonyms that are used to represent the ongoing twitter trends at any particular point of time. In the recent past, various knowledge based or polarity lexicon based research techniques have been proposed to generate sentiments polarity from the tweet hashtags i.e. to distinguish tweets into different target sentiment classes [23]. With the emergence of a topic, new hashtags go on quickly adding to the follow-up tweets of the same topic. So, the process of defining sentiment polarity on the basis of tweets hashtags become very cumbersome. In this context, we proposed a hybrid classification framework to semi-automatically identify and categorize tweets on the basis of initially available trending hashtags. The step by step working of this framework is as follows:
-
1.
Extract trending hashtags in relation to our current topic of interest.
-
2.
Manually analyse and classify hashtags to target sentiment analysis.
-
3.
Build initial tagged tweets dataset on the basis of resultant hashtags to train classification model.
-
4.
Train and Build sentiment polarity classification model.
-
5.
utilise trained model to classify follow up/real-time tweets of a topic.
The set of initially extracted top 20 hashtags along with their target classes are shown in Table 1. Furthermore, the statistics regarding the number of tweets extracted (in relation to each target class) on the basis of initially available hashtags are listed in Table 2.
3.3 Twitter Sentiment Classification
In the proposed work, initially, hashtags-based segmentation (as described in Sect. 3.2) is applied to segment crawled dataset into two different target datasets (BJP, Congress). Each of these data-sets are then individually used to train independent classification models. In the present work, we have implemented the Long-short term memory network (LSTM) [11] model for the classification purpose. LSTM network models [11] have achieved state of the art performance in several computer vision and text mining tasks [12]. These neural networks have the capability of persisting the information or context present in the text. Furthermore, in the present work, these classification models are augmented with different vector representations i.e. word embeddings such as Word2Vec, Glove and fasttext of the tweets to achieve better classification accuracy. The brief introduction to these embeddings are given as follows:
-
Word2Vec [17]: are basically two layer neural network models used to generate vector representations for the input text corpus. The vector representations are generated from a skip-gram model. The task of the model is to learn the weights for the 300 (embedding dim) neurons in the hidden layer. These weights themselves represent the distributed representation for a particular word. The output of the output layer represents the probability distribution for the remaining words.
-
Glove [19]: The model combines the count based word embedding generation model with the skip-gram model for word generation to improve the training speed. This involves the generation of a co-occurrence matrix(X) for each pair of words.
-
Fasttext [14]: Fasttext interprets a single word as a collection of n-gram characters obtained from the individual word. Thus, a word like ‘trendy’ is represented by the collection of chunks of the original word, that is, the chunks [‘trendy’, ‘trend’, ‘tren’, ‘tre’, ‘tr’, ‘t’ ] represent the original word. This is useful for generating embedding for rare words and the words appearing from out of the vocabulary of the training dataset.
The working of classification model in conjunction with different word embeddings is summarized in Algorithm 1 where \(\mathcal {G}, \mathcal {W}\) and \(\mathcal {F}\) represents glove, word2vec and fasttext embeddings respectively. Furthermore, the corresponding sentiment class prediction results in terms of average prediction accuracy are listed in Table 3. The term average prediction accuracy denotes the average of the classification model prediction performance on two initially segregated data-sets i.e. Congress and BJP datasets.
3.4 Opinion Analysis Corresponding to Different States
In this section, we make use of the above classification results to perform the BJP (Bharatiya Janata Party) and INC (Indian National Congress) related tweets based opinion analysis. Previous studies [15, 16, 22] in the field have performed the sentiment analysis (SA) with respect to different political parties as well as some of the work also performed SA over the top leaders of different parties. However, to the best of our knowledge, no previous studies have performed opinion analysis with respect to different political parties at state-level. This type of analysis could provide more insight about the users’ views corresponding to different political parties at state-level as well as it can play a pivot role in predicting the Exit polls results by analyzing the real-time state-wise segregated tweets. So, in the preceding section, we find out users opinion w.r.t different parties and try to find the correlation between the actual election results and our findings [7].


State-wise opinion analysis with respect to Bharatiya Janata Party (BJP) and Indian National Congress (INC)

State-wise comparative analysis of opinions for Bharatiya Janata Party (BJP) and Indian National Congress (INC)
Opinion Analysis Corresponding to BJP (Bharatiya Janata Party). While performing the Opinion analysis, we first segregate the tweets with respect to location information. The location information can be extracted into three ways i.e. Profile Location, GPS enabled tweets (Lat and Log), and Content based location information. In the current study, we segregate the tweets on the basis of location information given in the users’ profile and also from GPS enabled tweets (latitude and Longitude basis). Content based location information is not useful in these type of studies because tweets only contain users views corresponding to different political parties as well as their leaders, however it can play a vital role during some emergency situation, crises etc. that contains location information in the tweets itself.
By using profile location information, we are able to collect 12,71,658 positive tweets and 5,04,976 negative tweets with respect to BJP (Bhartiya Janta Party) as well as 2,29,645 positive tweets and 2,92,650 negative tweets corresponding to INC (Indian National Congress) and the corresponding whole statistics are listed in Table 2. While on the basis of latitude and longitude information, we extracted only 657 tweets and 438 tweets, which constitute only 0.036% of total BJP tweets and 0.083% of total INC tweets. After performing state-wise (location based) tweets segregation, we calculated the ratio of positive and negative tweets corresponding to each political party (BJP and INC) as per given Eqs. 1 and 2.
Figure 2(a) shows the state wise individual views in the form of positive and negative with respect to BJP. It clearly shows that in 26 states BJP headed with the higher positive response from total 29 states and 7 Union Territories. A similar state-wise analysis is performed on tweets related to the INC and the corresponding results are demonstrated in Fig. 2(b). From Fig. 2(b), it can be seen that INC received a positive response from 21 states and Union Territories. As the objective of our current research work is to provide an overall estimate of people opinions on the two political parties (BJP and Congress), we further performed a comparative analysis of people opinions on the tweets related to two political parties and the corresponding results are demonstrated in Fig. 3. From the comparative experimental analysis, we came to the conclusion that 28 states and Union territory are in favour of BJP out of 29 states and 7 union territories, whereas 7 states are in favour of INC. In order to validate our research outcomes or election predictions, we have compared our results with the actual Lok Sabha election resultsFootnote 1. From the comparative analysis, we have found that our results align with the actual outcomes with an absolute error of 0.12%.
For an instance our prediction results shows high positive opinions rate of BJP at several states and the corresponding actual outcomes are (Uttar Pradesh in which BJP won 62 seats out of 80 (62/80), Haryana (10/10), Himachal Pradesh (4/4), Arunachal Pradesh (2/2), Rajasthan (24/25), Chandigarh (1/1), Bihar (33/40), Delhi (7/7), Manipur (1/2), Gujarat (26/26), Madhya Pradesh (28/29), Maharastra (41/48), and Daman & Diu (1/1)) also evident/validates of our findings.
Whereas in case of INC also our results align with the final results by exhibiting positive response to INC for those states where INC acquire highest seat as compared to BJP i.e Andaman & Nicobar Islands (1/1), Kerala (15/20), Lakshadweep (1/1), Puducherry (1/1), Punjab (8/13), Tamilnadu (8/38). Furthermore, Mizoram and Sikkim are the two states in which INC received highest positive response as compared to the BJP but the seats are won by regional parties. The state-wise comparative analysis of negative response for both the political parties are demonstrated in Fig. 3.

Top trending hashtags
Trending Hashtags w.r.t BJP and INC. People use different hashtags to represent ongoing trends at any particular point of time. So it can play a vital role over the different micro-blogs such as Twitter, Facebook, and Instagram etc. for identification and characterisation of the tweets. In the present work, we have identified the top trending hashtags corresponding to BJP (Bhartiya Janta Party) and INC (Indian National Congress) as it can play a significant role during information diffusion. In our collected dataset, there were around 5532 different hashtags used by BJP and INC Supporters out of which we selected only those hashtags that were used by at least 10 (\(\mathcal {T}=10\)) different peoples. There are 1561 hashtags which satisfied this threshold condition. After that, we have manually identified the top 20 positive and negative hashtags corresponding to two parties as shown in Table 1. For example, the positive hashtags used for BJP are (‘PhirEkBaarModiSarkar’, ‘ModiHaiToVikasHai’, ‘AayegaToModiHi’, ‘DeshKiPasandModi’, ‘NamoAgain’) and negative are (‘AbHogaNyay’, ‘NyayForEmpowerment’, ‘BJPJumlaManifesto’, ‘NyayYatra’, ‘ShamelessChowkidars’) whereas the positive hashtags used for INC are (‘VoteForChang’, ‘AmethiKeDilMeinRahul’, ‘JanSankalpRally’, ‘VoteNyayVoteCongress’, ‘MyVoteForCongress’) and negative are (‘CongressTerror’, ‘CongressMuktBharat’, ‘CongressGundiHai’, ‘CongressGundiHai’, ‘corruptcongress’).
Above hashtags were some examples of the positive and negative trending hashtags that were used during the election period. Furthermore, we have analysed a broad picture of both the parties separately by identifying the top 20 hashtags used by the individuals. To extract the top hashtags, we set a threshold value (\(\mathcal {T}=500\)) over the extracted 1561 selected hashtags and we left with 281 trending hashtags that have frequency more than 500. For the visualization purpose, we have selected 20 hashtags out of these extracted 281 hashtags and the selected 20 hashtags along with their frequency count value are depicted in Fig. 4(a). From the Fig. 4(a), it can be clearly seen that 14 out of the 20 BJP trending hashtags are related to Prime Minister of India i.e (‘DeshKiPasandModi’, ‘NamoAgain’, ‘PhirEkBaarModiSarkar’, ‘ModiONceMOre’, ‘BharatKaGarvModi’, ‘AayegaToModiHi’, ‘ModiAgainsaysIndia’, ‘BharatBoleNaMoNaMo’, ‘ModiHiAayega’, ‘NaMoForNewIndia’, ‘IndiaBoleModiDobara’, ‘DeshModiKSaath’, ‘EveryVoteForModi’, ‘IndiaBoleNamoPhirSe’) and rest are related to Lok Sabha Election 2019. This clearly shows the influence of PMO Narendra Modi in all states.
The similar kind of analysis has been performed on the hashtags related to the INC and the corresponding top trending 20 hashtags are shown in Fig. 4(b). From the analysis of INC top trending hashtags, it has been found that most of the trending hashtags are related to other parties such as ‘AbHogaNyay’, ‘NYAY’, ‘NyayForEmpowement’, ‘BJPJumlaManifesto’, ‘NYAYforKarnataka’, ‘VoteNyayVoteCongress’ and there were no trending hashtags (in top 10) related to any leader like Rahul Gandhi. So it may be one of the reasons to loose in Lok Sabha election as they didn’t promote any leaders as other parties like BJP had done. Furthermore, it has also been found that there were no negative hashtags related to INC in BJP trending hashtags.
Top Trending @Mentions w.r.t BJP and INC. In this section, we have find out the top mentions which were tagged by BJP and INC supporters. Figure 5 (a) shows the trending mention related to BJP such as ‘@BJP4India’, ‘@narendramodi’, ‘@AmitShah’, ‘@INCIndia’, ‘@RahulGandhi’, ‘@PMOIndia’, ‘@rsprasad’, ‘@ECISVEEP’, ‘@nsitharaman’, ‘@AamAadmiParty’ whereas in Fig. 5 (b) shows the trending mention related to INC such as ‘@INCIndia’, ‘@RahulGandhi’, ‘@BJP4India’, ‘@narendramodi’, ‘@priyankagandhi’, ‘@AamAadmiParty’, ‘@ECISVEEP’, ‘@priyankac19’, ‘@PMOIndia’, ‘@AmitShah’. We have also segregated the trending leaders in both of the parties such as @narendramodi, @AmitShah, @rsprasad, @nsitharaman, @arunjaitley, @PiyushGoyal, @nitin_gadkari, @smritiirani were from BJP. whereas from INC @RahulGandhi, @priyankagandhi, @JhaSanjay, @capt_amarinder, @divyaspandana, @digvijaya_28, @rssurjewala, @ShashiTharoor.

Top trending @Mentions
4 Conclusion
Twitter has emerged as a successful platform for users’ to share their opinions and views on various topics and events, information diffusion, and political activities, thus becoming a rich source of information. So, in the current study, we utilise this abundant source of information to predict the 2019 Indian Lok Sabha election results. The study initially performed hashtag based tweet segregation to generate training data for deep learning model. Subsequently, the trained model is then utilised to categorize tweets into their target political parties sentiment classes. The proposed model succeeds in achieving 87.30% classification accuracy. Finally, we have performed the spatial analysis of classified tweets to predict the state-wise election outcome. From the prediction results of the proposed approach, the following inferences are drawn:
-
Twitter can be utilised as a reliable media for election results prediction in the Indian context.
-
The amalgamation of deep learning model with fasttext word-embedding provides support for improved classification accuracy.
-
The outcome of the comparative analysis of prediction results with actual results has shown that the proposed approach does accurate results prediction and has lower (0.12) absolute error.
-
Lastly, from the analysis of top trending hashtags and mentions w.r.t each party, we found some interesting patterns which might be the conclusive factors to the 2019 Lok Sabha election outcomes. For example, most of the trending hashtags used by INC supporters correspond to the other parties, whereas BJP supporters have used hashtags corresponding to their party only.
Notes
References
Agarwal, A., Toshniwal, D.: Application of lexicon based approach in sentiment analysis for short tweets. In: 2018 International Conference on Advances in Computing and Communication Engineering (ICACCE), pp. 189–193, June 2018. https://doi.org/10.1109/ICACCE.2018.8441696
Agarwal, A., Gupta, B., Bhatt, G., Mittal, A.: Construction of a semi-automated model for FAQ retrieval via short message service. In: Proceedings of the 7th Forum for Information Retrieval Evaluation, pp. 35–38. ACM (2015)
Agarwal, A., Singh, B., Bedi, J., Toshniwal, D.: A datamining approach for emotions extraction and discovering cricketers performance from stadium to sensex. arXiv preprint arXiv:1809.00310 (2018)
Agarwal, A., Singh, R., Toshniwal, D.: Geospatial sentiment analysis using Twitter data for UK-EU referendum. J. Inf. Optim. Sci. 39(1), 303–317 (2018)
Agarwal, A., Toshniwal, D.: Face off: travel habits, road conditions and traffic city characteristics bared using Twitter. IEEE Access 7, 66536–66552 (2019)
Ahmed, S., Jaidka, K., Cho, J.: The 2014 Indian elections on Twitter: a comparison of campaign strategies of political parties. Telematics Inform. 33(4), 1071–1087 (2016)
Bedi, J., Toshniwal, D.: Attribute selection based on correlation analysis. In: Rajsingh, E.B., Veerasamy, J., Alavi, A.H., Peter, J.D. (eds.) Advances in Big Data and Cloud Computing. AISC, vol. 645, pp. 51–61. Springer, Singapore (2018). https://doi.org/10.1007/978-981-10-7200-0_5
Burnap, P., Gibson, R., Sloan, L., Southern, R., Williams, M.: 140 characters to victory?: using Twitter to predict the UK 2015 general election. Electoral. Stud. 41, 230–233 (2016)
Dwi Prasetyo, N., Hauff, C.: Twitter-based election prediction in the developing world. In: Proceedings of the 26th ACM Conference on Hypertext & Social Media, pp. 149–158. ACM (2015)
Ebrahimi, M., Yazdavar, A.H., Sheth, A.: Challenges of sentiment analysis for dynamic events. IEEE Intell. Syst. 32(5), 70–75 (2017)
Goodfellow, I., Bengio, Y., Courville, A.: Deep Learning. MIT Press, Cambridge (2016)
Ibrahim, M., Abdillah, O., Wicaksono, A.F., Adriani, M.: Buzzer detection and sentiment analysis for predicting presidential election results in a Twitter nation. In: 2015 IEEE International Conference on Data Mining Workshop (ICDMW), pp. 1348–1353. IEEE (2015)
Jose, R., Chooralil, V.S.: Prediction of election result by enhanced sentiment analysis on Twitter data using word sense disambiguation. In: 2015 International Conference on Control Communication & Computing India (ICCC), pp. 638–641. IEEE (2015)
Joulin, A., Grave, E., Bojanowski, P., Mikolov, T.: Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759 (2016)
Khatua, A., Khatua, A., Ghosh, K., Chaki, N.: Can# twitter\(\_\)trends predict election results? evidence from 2014 Indian general election. In: 2015 48th Hawaii International Conference on System Sciences, pp. 1676–1685. IEEE (2015)
Mehndiratta, P., Sachdeva, S., Sachdeva, P., Sehgal, Y.: Elections again, Twitter may help!!! a large scale study for predicting election results using Twitter. In: Srinivasa, S., Mehta, S. (eds.) BDA 2014. LNCS, vol. 8883, pp. 133–144. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-13820-6_11
Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., Dean, J.: Distributed representations of words and phrases and their compositionality. In: Advances in Neural Information Processing Systems, pp. 3111–3119 (2013)
Paul, D., Li, F., Teja, M.K., Yu, X., Frost, R.: Compass: spatio temporal sentiment analysis of us election what Twitter says! In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1585–1594. ACM (2017)
Pennington, J., Socher, R., Manning, C.: Glove: global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1532–1543 (2014)
Srivastava, R., Kumar, H., Bhatia, M., Jain, S.: Analyzing Delhi assembly election 2015 using textual content of social network. In: Proceedings of the Sixth International Conference on Computer and Communication Technology 2015, pp. 78–85. ACM (2015)
Subramaniam, L.V., Roy, S., Faruquie, T.A., Negi, S.: A survey of types of text noise and techniques to handle noisy text. In: Proceedings of The Third Workshop on Analytics for Noisy Unstructured Text Data, pp. 115–122. ACM (2009)
Tsakalidis, A., Papadopoulos, S., Cristea, A.I., Kompatsiaris, Y.: Predicting elections for multiple countries using Twitter and polls. IEEE Intell. Syst. 30(2), 10–17 (2015)
Wang, X., Wei, F., Liu, X., Zhou, M., Zhang, M.: Topic sentiment analysis in twitter: a graph-based hashtag sentiment classification approach. In: CIKM (2011)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Agarwal, A., Toshniwal, D., Bedi, J. (2020). Can Twitter Help to Predict Outcome of 2019 Indian General Election: A Deep Learning Based Study. In: Cellier, P., Driessens, K. (eds) Machine Learning and Knowledge Discovery in Databases. ECML PKDD 2019. Communications in Computer and Information Science, vol 1168. Springer, Cham. https://doi.org/10.1007/978-3-030-43887-6_4
Download citation
DOI: https://doi.org/10.1007/978-3-030-43887-6_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-43886-9
Online ISBN: 978-3-030-43887-6
eBook Packages: Computer ScienceComputer Science (R0)
