
Abstract
We present a vision-based activity recognition system for centrally connected humanoid robots. The robots interact with several human participants who have varying behavioral styles and inter-activity-variability. A cloud server provides and updates the recognition model in all robots. The server continuously fetches the new activity videos recorded by the robots. It also fetches corresponding results and ground-truths provided by the human interacting with the robot. A decision on when to retrain the recognition model is made by an evolving performance-based logic. In the current article, we present the aforementioned adaptive recognition system with special emphasis on the partitioning logic employed for the division of new videos in training, cross-validation, and test groups of the next retraining instance. The distinct operating logic is based on class-wise recognition inaccuracies of the existing model. We compare this approach to a probabilistic partitioning approach in which the videos are partitioned with no performance considerations.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Notes
- 1.
A mechanism exists to generate a robot specific recognition model tailor-made with a more elevated emphasis on videos recorded by that particular robot in its environment.
- 2.
The server records meta-data on model performance across history (current/past/cumulative), class (specific/cumulative), group (Database/TR/CV/TS) and many other parameters such as time since last retraining, run-time addition or deletion of an activity class and more. Depending on the objective of an experiment, one or a combination of these is used as a trigger for retraining. For the experiment presented in the current article, the retraining was triggered whenever the current F score (TS-group class-cumulative) drops below that of cumulative F score (TS-group class-cumulative) producing a simplistic class-neutral mechanism.
- 3.
Class-wise recognition inaccuracies of the existing model are used for performance-based partitioning. This is not to be confused with performance measure used for triggering the retraining mechanism. Partitioning is part of the retraining mechanism and is not the mechanism that triggers retraining.
- 4.
Nao robot (specifications): 25 DoF, 2 face-mounted cameras (920p HD maximum 1280x960 resolution at 30 fps) pointing front and floor, animated LEDs, speakers, 4 microphones, voice recognition capabilities on a predefined dictionary, capability to identify human faces, Infrared, pressure and tactile sensors, wireless LAN, battery-operated, Intel Atom 1.6 GHz processor, Linux kernel.
- 5.
In experiments other than the ones presented in this article, the “initial” #classes may be a subset of the total 22 classes, with remaining classes introduced as previously unknown activity for the recognition model.
- 6.
22 ADLs: Walk [\(\times \)4](Right
 \(\Rightarrow \))(Left\(\Leftarrow \)
\(\Rightarrow \))(Left\(\Leftarrow \)
 )(Towards
)(Towards
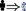 )(Away
)(Away
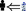 ); Open door [\(\times 2\)](
); Open door [\(\times 2\)](
 )(
)(
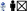 \(\boxtimes \)); Close door [\(\times 2\)](
\(\boxtimes \)); Close door [\(\times 2\)](
 )(
)(
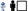 \(\Box \)); Sit and Stand; Human enacts gestures [\(\times \)6] (Clap hands)(Pick up the phone)(Pick up the glass to drink)(Thumbs up)(Wave hands)(Italian gesture); Human enacts gestures looking towards robot [\(\times \)6] (Come closer)(Go away)(Stand up)(Sit down)(Move towards my left)(Move towards my right).
\(\Box \)); Sit and Stand; Human enacts gestures [\(\times \)6] (Clap hands)(Pick up the phone)(Pick up the glass to drink)(Thumbs up)(Wave hands)(Italian gesture); Human enacts gestures looking towards robot [\(\times \)6] (Come closer)(Go away)(Stand up)(Sit down)(Move towards my left)(Move towards my right). - 7.
Video used by the robot for recognition (Signal): Camera: One (Front facing); Resolution: 160 \(\times \) 120 \(\times \) 1 (Gray); Time: 2 s; 24 Frames (2 s); Frame-rate: 12; Scales: 4 Scale Dense sampling. Outside the scope of this article, we use other signals as well.
- 8.
Video recorded by the robot (Record): Camera: One (Front facing); Resolution: 1280 \(\times \) 960 \(\times \) 3 (RGB); Time: 5 s (2 s of activity, 1.5 s of pre-activity and 1.5 s of post-activity recording); Frame-rate: 12; Scales: 8 Scale Dense sampling. We have stored all original videos in a secondary database for future employment when robots with better computational and memory capabilities will be accessible.
- 9.
F score, also known as F1 score/F measure is a measure of accuracy for classification results that considers both precision and recall to compute the score. It is the harmonic mean of precision and recall i.e. 2*((precision*recall)/(precision+recall)).

 )(Towards
)(Towards
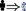 )(Away
)(Away
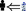 ); Open door [
); Open door [ )(
)(
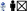
 )(
)(
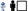
Abbreviations
- ADLs::
-
Activities of daily living
- BOW::
-
Bag of words
- CV/cv Group::
-
Cross-validation group
- EADLs::
-
Enhanced ADLs
- GMM::
-
Generalized method of moments
- HAR::
-
Human activity recognition
- HOF::
-
Histogram of optical flows
- HOG::
-
Histogram of gradients
- HSV::
-
Hue, saturation and value
- IADLs::
-
Instrumental ADLs
- IKSVM::
-
Intersection kernel based SVM
- IP::
-
Interest point
- LSTM::
-
Long short-term memory
- MBH::
-
Motion boundary histogram
- MBHx::
-
MBH in x orientation
- MBHy::
-
MBH in y orientation
- NLP::
-
Natural language processing
- P-CS/CS::
-
Probabilistic contribution Split
- P-RS/RS::
-
Probabilistic ratio Split
- RNN::
-
Recurrent neural network
- STIPs::
-
Space-time interest points
- ST-LSTM::
-
Spatio-temporal LSTM
- SVM::
-
Support vector machine
- TR/tr Group::
-
Training group
- TS/ts Group::
-
Test group
References
Begum, M., et al.: Performance of daily activities by older adults with dementia: the role of an assistive robot. In: 2013 IEEE 13th International Conference on Rehabilitation Robotics (ICORR), pp. 1–8 (2013). https://doi.org/10.1109/ICORR.2013.6650405
Bertsch, F.A., Hafner, V.V.: Real-time dynamic visual gesture recognition in human-robot interaction. In: 2009 9th IEEE-RAS International Conference on Humanoid Robots, pp. 447–453 (2009). https://doi.org/10.1109/ICHR.2009.5379541
Bilinski, P., Bremond, F.: Contextual statistics of space-time ordered features for human action recognition. In: 2012 IEEE Ninth International Conference on Advanced Video and Signal-Based Surveillance, pp. 228–233 (2012)
Boucenna, S., et al.: Learning of social signatures through imitation game between a robot and a human partner. IEEE Trans. Auton. Mental Dev. 6(3), 213–225 (2014). https://doi.org/10.1109/TAMD.2014.2319861. ISSN 1943-0604
Chen, T.L., et al.: Robots for humanity: using assistive robotics to empower people with disabilities. IEEE Robot. Autom. Mag. 20(1), 30–39 (2013). https://doi.org/10.1109/MRA.2012.2229950. ISSN 1070-9932
Cho, K., Chen, X.: Classifying and visualizing motion capture sequences using deep neural networks. In: VISAPP 2014 - Proceedings of the 9th International Conference on Computer Vision Theory and Applications, vol. 2, June 2013
Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: In CVPR, pp. 886–893 (2005)
Du, Y., Wang, W., Wang, L.: Hierarchical recurrent neural network for skeleton based action recognition. pp. 1110–1118, June 2015. https://doi.org/10.1109/CVPR.2015.7298714
El-Yacoubi, M.A., et al.: Vision-based recognition of activities by a humanoid robot. Int. J. Adv. Robot. Syst. 12(12), 179 (2015). https://doi.org/10.5772/61819
Falco, P., et al.: Representing human motion with FADE and U-FADE: an efficient frequency-domain approach. In: Autonomous Robots, March 2018
Farnebäck, G.: Two-frame motion estimation based on polynomial expansion. In: Bigun, J., Gustavsson, T. (eds.) Image Analysis: 13th Scandinavian Conference, SCIA 2003 Halmstad, Sweden, 29 June–2 July 2003 Proceedings, pp. 363–370. Springer, Heidelberg (2003). ISBN: 978-3-540-45103-7
Ho, Y., et al.: A hand gesture recognition system based on GMM method for human-robot interface. In: 2013 Second International Conference on Robot, Vision and Signal Processing, pp. 291–294 (2013). https://doi.org/10.1109/RVSP.2013.72
Kotseruba, I., Tsotsos, J.K.: 40 years of cognitive architectures: core cognitive abilities and practical applications. In: Artificial Intelligence Review (2018). https://doi.org/10.1007/s10462-018-9646-y. ISSN 1573-7462
Kragic, D., et al.: Interactive, collaborative robots: challenges and opportunities. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI 2018), pp. 18–25. AAAI Press, Stockholm (2018). http://dl.acm.org/citation.cfm?id=3304415.3304419. ISBN 978-0-9992411-2-7
Kruger, V., et al.: Learning actions from observations. IEEE Robot. Autom. Mag. 17(2), 30–43 (2010). https://doi.org/10.1109/MRA.2010.936961. ISSN 1070-9932
Laptev, I.: On space-time interest points. Int. J. Comput. Vis. 64(2), 107–123 (2005). ISSN 1573-1405
Laptev, I., et al.: Learning realistic human actions from movies, June 2008. https://doi.org/10.1109/CVPR.2008.4587756
Lee, D., Soloperto, R., Saveriano, M.: Bidirectional invariant representation of rigid body motions and its application to gesture recognition and reproduction. Auton. Robots 42, 1–21 (2017). https://doi.org/10.1007/s10514-017-9645-x
Liu, J., et al.: Spatio-temporal LSTM with trust gates for 3D human action recognition. vol. 9907, October 2016. https://doi.org/10.1007/978-3-319-46487-9_50
Maji, S., Berg, A.C., Malik, J.: Classification using intersection kernel support vector machines is efficient. In: 2008 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8 (2008). https://doi.org/10.1109/CVPR.2008.4587630
Margheri, L.: Dialogs on robotics horizons [student’s corner]. IEEE Robot. Autom. Mag. 21(1), 74–76 (2014). https://doi.org/10.1109/MRA.2014.2298365. ISSN 1070-9932
Microsoft. https://developer.microsoft.com/en-us/windows/kinect
Myagmarbayar, N., et al.: Human body contour data based activity recognition. In: 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pp. 5634–5637 (2013). https://doi.org/10.1109/EMBC.2013.6610828
Oi, F., et al.: Sequence of the most informative joints (SMIJ): a new representation for human skeletal action recognition. vol. 25, pp. 8 –13, June 2012. https://doi.org/10.1109/CVPRW.2012.6239231
Okamoto, T., et al.: Toward a dancing robot with listening capability: keypose-based integration of lower-, middle-, and upper-body motions for varying music tempos. IEEE Trans. Robot. 30(3), 771–778 (2014). https://doi.org/10.1109/TRO.2014.2300212. ISSN 1552-3098
Olatunji, I.E.: Human activity recognition for mobile robot. In: CoRR abs/1801.07633 arXiv: 1801.07633 (2018). http://arxiv.org/abs/1801.07633
Pers, J., et al.: Histograms of optical ow for efficient representation of body motion. Pattern Recog. Lett. 31, 1369–1376 (2010). https://doi.org/10.1016/j.patrec.2010.03.024
Santos, L., Khoshhal, K., Dias, J.: Trajectory-based human action segmentation. Pattern Recogn. 48(2), 568–579 (2015). https://doi.org/10.1016/j.patcog.2014.08.015. ISSN 0031-3203
Sasaki, Y.: The truth of the F-measure. In: Teach Tutor Mater, January 2007
Saveriano, M., Lee, D.: Invariant representation for user independent motion recognition. In: 2013 IEEE RO-MAN, pp. 650–655 (2013). https://doi.org/10.1109/ROMAN.2013.6628422
Schenck, C., et al.: Which object fits best? solving matrix completion tasks with a humanoid robot. IEEE Trans. Auton. Mental Dev. 6(3), 226–240 (2014). https://doi.org/10.1109/TAMD.2014.2325822. ISSN 1943-0604
Nandi, G.C., Siddharth, S., Akash, A.: Human-robot communication through visual game and gesture learning. In: International Advance Computing Conference (IACC), vol. 2, pp. 1395–1402 (2013). https://doi.org/10.1109/ICCV.2005.28
Wang, H., et al.: Action recognition by dense trajectories. In: CVPR 2011, pp. 3169–3176 (2011). https://doi.org/10.1109/CVPR.2011.5995407
Wang, H., et al.: Dense trajectories and motion boundary descriptors for action recognition. Int. J. Comput. Vis. 103(1), 60–79 (2013). https://doi.org/10.1007/s11263-012-0594-8. https://hal.inria.fr/hal-00803241
Yuan, F., et al.: Mid-level features and spatio-temporal context for activity recognition. Pattern Recogn. 45(12), 4182 –4191 (2012). https://doi.org/10.1016/j.patcog.2012.05.001. http://www.sciencedirect.com/science/article/pii/S0031320312002129. ISSN 0031-3203
Zhen, X., Shao, L.: Spatio-temporal steerable pyramid for human action recognition. In: 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), pp. 1–6 (2013). https://doi.org/10.1109/FG.2013.6553732
Zhu, W., et al.: Co-occurrence feature learning for skeleton based action recognition using regularized deep LSTM networks. In: CoRR abs/1603.07772. arXiv: 1603.07772 (2016). http://arxiv.org/abs/1603.07772
Acknowledgment
The authors would like to thank CARNOT MINES-TSN for funding this work through the ‘Robot apprenant’ project.
We are thankful to the Service Robotics Research Center at Technische Hochschule Ulm (SeRoNet project) for supporting the consolidation period of this article.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Nagrath, V., Hariz, M., Yacoubi, M.A.E. (2021). Adaptive Retraining of Visual Recognition-Model in Human Activity Recognition by Collaborative Humanoid Robots. In: Arai, K., Kapoor, S., Bhatia, R. (eds) Intelligent Systems and Applications. IntelliSys 2020. Advances in Intelligent Systems and Computing, vol 1251. Springer, Cham. https://doi.org/10.1007/978-3-030-55187-2_12
Download citation
DOI: https://doi.org/10.1007/978-3-030-55187-2_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-55186-5
Online ISBN: 978-3-030-55187-2
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)