
Abstract
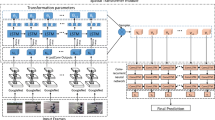
Aiming at the problem of unbalanced distribution of spatio-temporal information in video images, this paper proposes a 2D/3D hybrid convolutional network that introduces attention mechanism, which fully captures video space information and dynamic motion information, and better reveals motion features. With the help of the dual-stream convolutional network structure, we built 2D convolution and 3D convolution parallel neural networks. In the 2D convolutional neural network, the residual structure and the LSTM network model are used to focus on the spatial feature information of the video behavior. Secondly, the 3D convolutional neural network constructed by Inception structure is used to extract the spatiotemporal feature information of video behavior. On the basis of the two high-level semantics extracted, the attention mechanism is introduced to fuse the features. Finally, the obtained significant feature vector is used for video behavior recognition. Compared with other network models on the UCF101 and HMDB51 datasets, it can be seen from the results that the proposed 2D/3D hybrid convolutional network has good recognition performance and robustness.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recognition in videos. In: Computer Vision and Pattern Recognition (2014)
Wang, L., et al.: Temporal segment networks: towards good practices for deep action recognition. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 20–36. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_2
Zhou, B., Andonian, A., Oliva, A., Torralba, A.: Temporal relational reasoning in videos. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11205, pp. 831–846. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01246-5_49
Zhu, Y., Lan, Z., Newsam, S., Hauptmann, A.: Hidden two-stream convolutional networks for action recognition. In: Jawahar, C.V., Li, H., Mori, G., Schindler, K. (eds.) ACCV 2018. LNCS, vol. 11363, pp. 363–378. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-20893-6_23
Tran, D., Bourdev, L., Fergus, R., et al.: Learning spatiotemporal features with 3D convolutional networks. In: IEEE International Conference on Computer Vision, Santiago, pp. 4489–4497. IEEE Computer Society (2015)
Diba, A., Fayyaz, M., Sharma, V., et al.: Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification. Computing Research Repository (2017)
Carreira, J., Zisserman, A.: Quo Vadis, action recognition? A new model and the kinetics dataset. In: IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, pp. 4724–4733. IEEE Computer Society (2017)
Ji, S., Xu, W., Yang, M., Yu, K.: 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 35(1), 221–231 (2013)
He, K., Zhang, X., Ren, S., et al.: Deep residual learning for image recognition. CoRR abs/1512.03385 (2015)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Vaswani, A., et al.: Attention is all you need. CoRR abs/1706.03762 (2017)
Soomro, K., Zamir, A.R., Shah, M.: UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. CoRR abs/1212.0402 (2012)
Hara, K., Kataoka, H., Satoh, Y.: Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet? In: IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, pp. 6546–6555. IEEE Computer Society (2018)
Tran, D., Wang, H., Torresani, L., et al.: A closer look at spatiotemporal convolutions for action recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, pp. 6450–6459. IEEE Computer Society (2018)
Liu, Z., Hu, H., Zhang, J.: Spatiotemporal fusion networks for video action recognition. Neural Process. Lett. 50(2), 1877–1890 (2019). https://doi.org/10.1007/s11063-018-09972-6
Li, Q., Qiu, Z., Yao, T., et al.: Action recognition by learning deep multi-granular spatio-temporal video representation. In: International Conference on Multimedia Retrieval, pp. 159–166. ACM, New York (2016)
Zhou, Y., Sun, X., Zha, Z.-J., Zeng, W.: MiCT: mixed 3D/2D convolutional tube for human action recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, pp. 449–458. IEEE Computer Society (2018)
Yu, W., Wei, Y., Li, L.: Human behavior recognition model based on multi-model fusion. Comput. Eng. Des. 40(10), 3030–3036 (2019)
Zeng, M., Zheng, Z., Luo, S.: Dual-convolution human behavior recognition combined with LSTM. Modern Electron. Tech. 42(19), 37–40 (2019)
Ma, C., Mao, Z., Cui, J., Yi, W.: Behavior recognition based on deep LSTM and dual stream convergence network. Comput. Eng. Des. 40(09), 2631–2637 (2019)
Ma, L., Yu, W., Zhu, Y., Wang, C., Wang, P.: Recognition of fall behavior based on deep learning. Comput. Sci. 46(09), 106–112 (2019)
Rodríguez-Moreno, I., Martínez-Otzeta, J.M., Sierra, B., Rodriguez, I., Jauregi, E.: Video activity recognition: state-of-the-art. Sensors (Basel, Switzerland) 19(14), 3160 (2019)
Wishart, D.S., Tzur, D., et al.: HMDB: the human metabolome database. Nucleic Acids Res. 35, 521–526 (2007)
Shah, S.M.S., Malik, T.A., Khatoon, R., Hassan, S.S., Shah, F.A.: Human behavior classification using geometrical features of skeleton and support vector machines. Comput. Mater. Continua 61(2), 535–553 (2019)
Yang, K., Wang, Y., Zhang, W., Yao, J., Le, Y.: Keyphrase generation based on self-attention mechanism. Comput. Mater. Continua 61(2), 569–581 (2019)
Song, W., Yu, J., Zhao, X., Wang, A.: Research on action recognition and content analysis in videos based on DNN and MLN. Comput. Mater. Continua 61(3), 1189–1204 (2019)
Acknowledgments
This research was funded by Beijing Natural Science Foundation-Haidian Primitive Innovation Joint Fund grant number (L182007) and the National Natural Science Foundation of China grant number (61702020).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Song, Y., Tan, L., Zhou, L., Lv, X., Ma, Z. (2020). Video Action Recognition Based on Hybrid Convolutional Network. In: Sun, X., Wang, J., Bertino, E. (eds) Artificial Intelligence and Security. ICAIS 2020. Lecture Notes in Computer Science(), vol 12240. Springer, Cham. https://doi.org/10.1007/978-3-030-57881-7_40
Download citation
DOI: https://doi.org/10.1007/978-3-030-57881-7_40
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-57880-0
Online ISBN: 978-3-030-57881-7
eBook Packages: Computer ScienceComputer Science (R0)