
Abstract
Decreasing defects, waste time, meeting customer demand and being adaptable are the goals of a Zero Defect Manufacturing (ZDM) strategy. Scheduling is an important tool to perform that. It should take in account buffer size allocation. In this study, a method to solve the Buffer Sizing Problem (BSP), which is NP-hard problem. The current research work focuses on finding the optimal buffer allocation using Tabu-search (TS) algorithm. The goal is to minimize buffers’ sizes while maintaining a certain productivity. The evaluation of the alternative buffer solutions were performed using the following performance indicators; Makespan, Tardiness and the Buffers Cost. In the developed method the following are considered: multitasking machines subjected to non-deterministic failure, non-homogeneous buffer sizing, and non-sequential production line. The propose approach was tested via a real life industrial use case from a leading Swiss company in high precision sensors. The simulation results showed that the proposed methodology can effectively design the buffer strategy for complex production lines.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Modern industry, 4.0, wants to reach new goals. Nowadays, manufacturing includes data to analyze and treat, changing and advancing communication and information technology. Flexible production and batch processes are the path adopted. Furthermore, manufacturers give special attention to the improvement of the quality using one of the latest paradigms, Zero Defect Manufacturing (ZDM) which is achieved by implementing industry 4.0 technologies. ZDM paradigm is relying on a huge data collection about product and processes. In ZDM, not only detection takes place, but also the right reaction must be done [1]. Implementing the ZDM concept can create loses in the performance of the manufacturing system because extra processes are added, such as inspections or part re-work. In addition, to stay competitive, companies should answer properly to customer different customization needs, since the production has changed from mass production to mass customization [2]. The way to do is to move from systematics inspections to a flexible structure, while products are not mass product but became in form of batches, augmenting the level of defects probability and occurrence. ZDM is a complex strategy to implement and therefore, new approaches are needed for successful implementation.
The current research work focuses on giving a solution to the Buffer Size Problem (BSP) for unreliable multitask machine in non-sequential production line. Furthermore, the parts waiting time in the buffers are utilized for the ZDM processes. The solution proposed is implemented inside a ZDM oriented scheduling tool [3]. Tabu search is used for both scheduling and Buffer Size optimization. The proposed approach is tested in a real industrial use case from a Swiss leading micro-sensors company. Finally, a comparison is performed between the buffer solution with and without ZDM in order to discover the different needs that ZDM requires.
2 State of the Art
Buffer sizing problem (BSP) is a combinatorial problem ranked as a NP-hard [4]. Buffers have a big importance because their presence increases workstations’ independence. It eliminates common issues such as starving or blocked machines [5]. However big buffer’s size means bigger investment and bigger use costs. The problem can take many forms as shown by many authors. First mathematical formulations are done by Buzacott in 1954 [6]. The most common method for optimizing Buffer Size is metaheuristics algorithms. In general, a solution for the BSP is compound of two parts, an evaluative part that determines performance measures and a generative part based on which the different Buffer size are generated. Evaluation could be done for big cases with simulation, or an approximation is made based on the generalized expansion method like for example [7], the aggregation method in [8] for their serial line using the aggregate model from [9] or the decomposition method used by [10] where they followed the DDX model from [11].
This drives the subject to the generative part of the solution, which is the main part of this paper, that determines the buffer capacity and find the solution. This is typically an optimization problem. Many traditional techniques exist such as Gradient search and degraded ceiling, however their main drawback is that they can trapped into a local optimum. Meta-heuristic are the best solution for medium to large problems because they can avoid local optima by putting some laws to manage the search space [5]. The most widely known meta-heuristic methods are the tabu-search, simulated annealing, genetic algorithm and ant colony. Many authors treated this topic such as Spinellis et al. who used decomposition method with simulated annealing to optimize line’s production rate [12], where others have used genetic algorithm to find the optimal buffer sizes [13]. Blumenfeld and Li developed a methodology for solving the BSP for multiple machines but always with identical speeds, number of failures per hour and repair rate [14].
Compared to the current literature, the paper offers new perspectives. The added value of the proposed tabu list is its simplicity and robustness. Indeed, it is simple to tune and quite straightforward for visualizing parameters influence on result. It has proven to be effective on various production network and machine configuration.
In the current literature there are no articles discussing the BSP, ZDM and scheduling together. The implementation of ZDM into a manufacturing system can cause great disturbances, because for achieving zero defects numerous of actions are needed to be implemented into the schedule in order to counteract problems or to prevent future problems [1]. ZDM actions might create delays on the production or intensify some bottleneck stations and therefore the correct buffer size is imperative in order to mitigate those effects.
3 Methodology and Industrial Case Definition
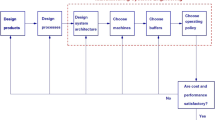
In this section, the methodology for the buffer size optimization will be analyzed. The difference from existing research works is that the production system under investigation is composed from different machines. In addition, each task can be performed in more than one machine with different processing times. The optimization of the buffer size and the schedule is performed using Tabu-search, because of the good solution quality compared to the computation time. The buffer size optimization is done via tabu-search. Then the scheduling optimization is performed via a different tabu search program. The focus of the current research work is the neighbor creation for the evolution of the initial solution. The neighborhood generation is done in two phases: heterogeneous and homogeneous. Heterogeneous means that neighbors are obtained by adding 1 on each buffer iteration. Homogeneous iteration is used |when a local minimum happens. It forces the generation of buffer profiles that will necessary provide a better objective function. Two approaches to build the neighbor are used. The first is to generate n neighbors from the current buffer distribution, n being the number of buffers. Each neighbor is a vector of size n × 1. They differ from the current buffer distribution by a unity added to one buffer (i.e. to one line in the vector). Neighbors distinguishes themselves by the buffer where the unity is added. This is the heterogeneous distribution. If the current buffer distribution is still better than the neighbor, a new way to generate buffer is adopted. The maximum of the current buffer distribution is put as the size of all other buffers. This is the homogeneous distribution. Each time a new distribution is found, the program goes back by default to the heterogenous distribution. Concerning the objective function computation, it is done inside the associated scheduling tool. Furthermore, if a buffer is full, all the production is stopped and emptying the full buffer becomes the priority. Not emptying a buffer may lead to non-feasible schedule. When this happens, a specifically designed algorithm is dynamically tweaking the schedule in specific points in order to achieve a feasible schedule. Figure 1 illustrates the buffer optimization procedure that is followed in the current research work.

Buffer optimization overall framework
Each buffer solution is fed into a scheduling tool where with the help of Tabu-Search a local optimum solution is produced based on three performance indicators (PIs). The used PIs are the Makespan and the Tardiness, which are described in [15] and the total buffers cost which is a function of the size of the buffer times the cost per square meter times the area that each component needs.
Each buffer solution is fed into a scheduling tool where with the help of Tabu-Search a local optimum solution is produced based on three performance indicators (PIs). The used PIs are the Makespan and the Tardiness, which are described in [15] and the total buffers cost which is a function of the size of the buffer times the cost per square meter times the area that each component needs. The comparison of the alternative schedule solutions is performed by aggregating the three PIs into one value.
This is achieved by normalizing each PI value in order to eliminate the units and then perform a weighted sum. The weight factors for each PI is user defined, but the sum of all the weight factors should be 1. The result will be a value in the range [0,1]. The result of the weighted sum is called “Utility Value” and closer to 1 it is the higher the quality of the produced schedule. This procedure is based on Simple Additive Weighting (SAW) method which is explained in details in [16, 17]. In this point should be mentioned that the ZDM is implemented into the scheduling tool via a procedure to re-schedule the production every time that actions are needed in order to mitigate problems and therefore achieve ZDM.
3.1 Industrial Case
The propose approach was tested using data coming from a real-life industrial use case from a leading Swiss company in high precision sensors. The case treated in this paper is more realistic but also more complex. Indeed, the literature concentrated on different problems: single production line with two machines or more that are similar, with a sequential organization. Machines in literature also are non-multitask. In the case treated there is no line but a network, in other terms the machines are compound by non-similar workstations The production line/network is not sequential, and machines are multitask, which add more complexity to what is found in literature. Figure 2 shows the bill of process for the product under investigation. In reality the product BoP is more complex but for the current study a simplification was performed and the BoP presented in Fig. 2 illustrates the grouped BoP, composed by seven tasks. Also there are four inspection processes at the following levels of BoP, 904, 102, 101 and 901. If a defected part is detected the part is repaired if it is feasible in order to achieve ZDM. Furthermore, the current industrial case is susceptible to order delays and the financial penalties in case of delays are significant. This is the reason behind the selection of the Makespan and the Tardiness as PI for the current problem. In addition, the buffers cost another aspect that needs to be in balance with the manufacturing times and therefore those three PI are the final choice.

Bill of Processes (BoP)
The production line is composed by seven stations, each one has two machines. Each machine in each station has different processing time, failure and repair rates from the other. Furthermore, the buffers are considered to be after each machine. The proposed approach is validated through a real life industrial use case and considers the production of 250 products, which they represent the 30% of the annual sales. In total the investigated product, occupy 0.03 sqm each when fully assembled. For each manufacturing step, the components occupying area were calculated in order to accurately calculate the Buffers cost. In the current study, the cost per sqm is considered 50CHF.
4 Experimental Results
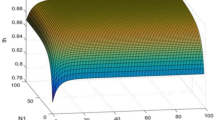
The simulations for validating the current method were conducted for a period of three months, which corresponds to 250 parts. In order to demonstrate the evolution of the solution all the alternatives saved in the tabu-list (Tabu-Search (a) Fig. 1) were used for figures Figs. 3, 4, 5 and 6. The tabu-list contains the best alternative solutions revealed during the tabu-search algorithm and therefore worth illustrating their performance. The performance indicators for those solutions are presented in Fig. 3, Fig. 4 and Fig. 5 and corresponds to the Makespan, Tardiness and Buffers cost accordingly. The x-axis of all figures corresponds to the total sum of buffer places for all the workstations. In this point should be mentioned that the buffer size on each machine was considered as separate variable and independent from the rest. For example the solution [3, 5, 6] is treated as different solution than the [1, 3, 10] regardless that the total sum is the same. The total sum of buffers was selected only of demonstrating purposes and for simplifying the graphs.

Makespan vs total sum of buffers

Tardiness vs total sum of buffers

Buffers cost vs total sum of buffers

Utility value vs total sum of buffers for different weight factor sets
As someone would expect the Makespan is decreasing as the number of buffer places are increased. Until total buffer places 35 there is a significant drop of the Makespan value were as after that point there Makespan is decreasing with a significant lower rate. Similar trend is observed to the Tardiness, until buffer size 35 the Tardiness is rapidly decreased. After that point, there is a lower decreasing rate until reaches zero, which means that there are not orders due date delays. The Buffers cost is increasing as the number of buffer places is increasing. Having seen the three individual performance indicators is difficult to reach to a conclusion of the best solution. Therefore, the three performance indicators were combined into one value (Utility Value), ranging from [0, 1] with 0 to be the worst and 1 the best possible number [16]. Then the utility value was calculated for different weight factors for each performance indicator and presented in Fig. 6 (M:Makespan, C:Buffers Cost and T:Tardiness).
All the alternatives presented in Fig. 6 show some similarities in their behavior. At the beginning where the absolute number of buffer places is small the solutions are not good and when there is a small increase to a specific workstation the solution becomes significantly better. Interesting is that for total buffer size 35 and 36 all the solutions are very close together with an average standard deviation of 0.0162.
After that point and until total buffer size 54 there is an increase to the quality of the solution for all the cases. From that point three different behaviors are noticed. In the case where the weight for the buffer cost is minimum (0.2) the solution’s quality is continuing to getting better slightly. In the case where the weight for the buffer cost is maximum (0.5) the quality of the solution is getting worst as the total buffer size is increased. In all the other cases, the solution can be considered constant. The best solution regardless the PI weight factors was in the neighborhood of 50–54 buffer size with the absolute best solutions to be [9,7,10,7,7,7,7] and [8,7,10,7,6,8,7] for weight factors sets 3,5 and 1,2,4,6,7 respectively. Further to that from the simulation results, it was observed that workstation for T101 is the bottleneck and requires 10 buffer places, whereas the other workstation requires between 6–9. On the other hand, when the same case was simulated without ZDM active then the buffer sizes were [6,3,5,5,12,4] which are significantly different than the results obtained with ZDM active. In this case, the bottleneck is not any more the T101 but the T104 and this is caused because no ZDM actions are required to be implemented to the schedule.
5 Conclusions
The developed method proved to be robust enough to optimize the buffer size problem real complex production line. The results shows that the implementation of ZDM requires a different buffer sizes because of the quality control for every part and the actions that are required for counteracting a problem. The intelligent neighborhood generation method for shifting between heterogeneous and homogeneous buffer distribution proved useful for finding better solutions, because when the Tabu-search is “trapped” to a local maximum, it shifts to a homogeneous buffer distribution. Further to that, the Makespan is not depending on the absolute sum of buffer size, but it is more sensitive to the increase of a certain bottleneck buffer. Decreasing trends for Makespan and Tardiness and the increasing on for cost in function of buffers size is respect the findings in the literature.
References
Psarommatis, F., May, G., Dreyfus, P.-A., Kiritsis, D.: Zero defect manufacturing: state-of-the-art review, shortcomings and future directions in research. Int. J. Prod. Res. 7543, 1–17 (2019)
Mourtzis, D., Doukas, M., Psarommatis, F.: A multi-criteria evaluation of centralized and decentralized production networks in a highly customer-driven environment. CIRP Ann. Manuf. Technol. 61(1), 427–430 (2012)
Psarommatis, F., Kiritsis, D.: A scheduling tool for achieving zero defect manufacturing (ZDM): a conceptual framework. In: Moon, I., Lee, G.M., Park, J., Kiritsis, D., von Cieminski, G. (eds.) APMS 2018. IAICT, vol. 536, pp. 271–278. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-99707-0_34
Dolgui, A., Eremeev, A., Kovalyov, M.Y., Sigaev, V.: complexity of buffer capacity allocation problems for production lines with unreliable machines. J. Math. Model. Algorithms 12(2), 155–165 (2013)
Demir, L., Tunali, S., Eliiyi, D.T.: The state of the art on buffer allocation problem: a comprehensive survey. J. Intel. Manuf. 25(3), 371–392 (2014)
Buzacott, J.A., Shanthikumar, J.G.: Stochastic Models of Manufacturing Systems. Prentice Hall, Englewood Cliffs (1993)
Cruz, F.R.B., Van Woensel, T., Smith, J.M.G.: Buffer and throughput trade-offs in M/G/1/K queueing networks: a bi-criteria approach. Int. J. Prod. Econ. 125(2), 224–234 (2010)
Abu Qudeiri, J., Yamamoto, H., Ramli, R., Jamali, A.: Genetic algorithm for buffer size and work station capacity in serial-parallel production lines. Artif. Life Robot. 12(1–2), 102–106 (2008)
Li, J.: Overlapping decomposition: a system-theoretic method for modeling and analysis of complex manufacturing systems. IEEE Trans. Autom. Sci. Eng. 2(1), 40–53 (2005)
Shi, L., Men, S.: Optimal buffer allocation in production lines. IIE Trans. (Institute Ind. Eng.) 35(1), 1–10 (2003)
Dallery, Y., David, R., Xie, X.L.: An efficient algorithm for analysis of transfer lines with unreliable machines and finite buffers, IIE Trans. (Inst. Ind. Eng.) 20(3), 281–283 (1988)
Spinellis, D.D., Papadopoulos, C.T.: A simulated annealing approach for buffer allocation in reliable production lines. Ann. Oper. Res. 93(1–4), 373–384 (2000)
Qudeiri, J.A., Mohammed, M.K., Mian, S.H., Khadra, F.A.: A multistage approach for buffer size decision in serial production line. In: SIMULTECH 2015 - 5th International Conference on Simulation Modeling Methodologies, Technologies and Applications, pp. 145–153 (2015)
Blumenfeld, D.E., Li, J.: An analytical formula for throughput of a production line with identical stations and random failures (2005)
Psarommatis, F., Kiritsis, D.: Identification of the inspection specifications for achieving zero defect manufacturing. In: Ameri, F., Stecke, K.E., von Cieminski, G., Kiritsis, D. (eds.) APMS 2019. IAICT, vol. 566, pp. 267–273. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-30000-5_34
Mourtzis, D., Doukas, M., Psarommatis, F.: A toolbox for the design, planning and operation of manufacturing networks in a mass customisation environment. J. Manuf. Syst. 36, 274–286 (2015)
Tzeng, G.-H., Huang, J.-J.: Multiple Attribute Decision Making. Springer-Verlag, Berlin, Heidelberg (2011)
Acknowledgments
The presented work is supported by the EU H2020 project QU4LITY (No. 825030). The paper reflects the authors’ views and the Commission is not responsible for any use that may be made of the information it contains.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 IFIP International Federation for Information Processing
About this paper

Cite this paper
Psarommatis, F., Boujemaoui, A., Kiritsis, D. (2020). A Computational Method for Identifying the Optimum Buffer Size in the Era of Zero Defect Manufacturing. In: Lalic, B., Majstorovic, V., Marjanovic, U., von Cieminski, G., Romero, D. (eds) Advances in Production Management Systems. Towards Smart and Digital Manufacturing. APMS 2020. IFIP Advances in Information and Communication Technology, vol 592. Springer, Cham. https://doi.org/10.1007/978-3-030-57997-5_51
Download citation
DOI: https://doi.org/10.1007/978-3-030-57997-5_51
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-57996-8
Online ISBN: 978-3-030-57997-5
eBook Packages: Computer ScienceComputer Science (R0)