
Abstract
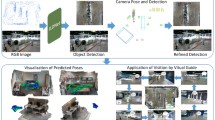
Monocular 3D object detection aims to extract the 3D position and properties of objects from a 2D input image. This is an ill-posed problem with a major difficulty lying in the information loss by depth-agnostic cameras. Conventional approaches sample 3D bounding boxes from the space and infer the relationship between the target object and each of them, however, the probability of effective samples is relatively small in the 3D space. To improve the efficiency of sampling, we propose to start with an initial prediction and refine it gradually towards the ground truth, with only one 3d parameter changed in each step. This requires designing a policy which gets a reward after several steps, and thus we adopt reinforcement learning to optimize it. The proposed framework, Reinforced Axial Refinement Network (RAR-Net), serves as a post-processing stage which can be freely integrated into existing monocular 3D detection methods, and improve the performance on the KITTI dataset with small extra computational costs.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Alhaija, H.A., Mustikovela, S.K., Mescheder, L., Geiger, A., Rother, C.: Augmented reality meets computer vision: efficient data generation for urban driving scenes. IJCV 126(9), 961–972 (2018)
Bertozzi, M., Broggi, A., Fascioli, A.: Vision-based intelligent vehicles: state of the art and perspectives. Robot. Auton. Syst. 32(1), 1–16 (2000)
Brazil, G., Liu, X.: M3d-rpn: monocular 3d region proposal network for object detection. In: CVPR (2019)
Caicedo, J.C., Lazebnik, S.: Active object localization with deep reinforcement learning. In: ICCV (2015)
Cao, C., et al.: Look and think twice: capturing top-down visual attention with feedback convolutional neural networks. In: ICCV (2015)
Chabot, F., Chaouch, M., Rabarisoa, J., Teulière, C., Chateau, T.: Deep manta: a coarse-to-fine many-task network for joint 2d and 3d vehicle analysis from monocular image. In: CVPR (2017)
Chang, J., Wetzstein, G.: Deep optics for monocular depth estimation and 3d object detection. In: ICCV (2019)
Chen, C., Seff, A., Kornhauser, A., Xiao, J.: Deepdriving: learning affordance for direct perception in autonomous driving. In: ICCV (2015)
Chen, X., Kundu, K., Zhang, Z., Ma, H., Fidler, S., Urtasun, R.: Monocular 3d object detection for autonomous driving. In: CVPR (2016)
Chen, X., et al.: 3D object proposals for accurate object class detection. In: NeurIPS (2015)
Ding, M., et al.: Learning depth-guided convolutions for monocular 3d object detection. In: CVPR (2020)
Duan, Y., Wang, Z., Lu, J., Lin, X., Zhou, J.: Graphbit: bitwise interaction mining via deep reinforcement learning. In: CVPR (2018)
Fidler, S., Dickinson, S., Urtasun, R.: 3D object detection and viewpoint estimation with a deformable 3d cuboid model. In: NeurIPS (2012)
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: the kitti dataset. IJRR 32(11), 1231–1237 (2013)
Geiger, A., Lenz, P., Urtasun, R.: Are we ready for autonomous driving the kitti vision benchmark suite. In: CVPR (2012)
Guo, M., Lu, J., Zhou, J.: Dual-agent deep reinforcement learning for deformable face tracking. In: ECCV (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
Janai, J., Güney, F., Behl, A., Geiger, A.: Computer vision for autonomous vehicles: problems, datasets and state-of-the-art. arXiv preprint arXiv:1704.05519 (2017)
Ku, J., Pon, A.D., Waslander, S.L.: Monocular 3d object detection leveraging accurate proposals and shape reconstruction. In: CVPR (2019)
Kundu, A., Li, Y., Rehg, J.M.: 3d-rcnn: instance-level 3d object reconstruction via render-and-compare. In: CVPR (2018)
Levine, S., Pastor, P., Krizhevsky, A., Ibarz, J., Quillen, D.: Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. IJRR 37(4–5), 421–436 (2018)
Li, B., Ouyang, W., Sheng, L., Zeng, X., Wang, X.: Gs3d: an efficient 3d object detection framework for autonomous driving. In: CVPR (2019)
Li, Y., Wang, G., Ji, X., Xiang, Y., Fox, D.: Deepim: deep iterative matching for 6d pose estimation. In: ECCV (2018)
Littman, M.L.: Reinforcement learning improves behaviour from evaluative feedback. Nature 521(7553), 445 (2015)
Liu, L., Lu, J., Xu, C., Tian, Q., Zhou, J.: Deep fitting degree scoring network for monocular 3d object detection. In: CVPR (2019)
Ma, X., Wang, Z., Li, H., Zhang, P., Ouyang, W., Fan, X.: Accurate monocular 3d object detection via color-embedded 3d reconstruction for autonomous driving. In: CVPR (2019)
Mahler, J., et al.: Dex-net 2.0: deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics. In: RSS (2017)
Manhardt, F., Kehl, W., Gaidon, A.: Roi-10d: monocular lifting of 2d detection to 6d pose and metric shape. In: CVPR (2019)
Manhardt, F., Kehl, W., Navab, N., Tombari, F.: Deep model-based 6d pose refinement in rgb. In: ECCV (2018)
Mathe, S., Pirinen, A., Sminchisescu, C.: Reinforcement learning for visual object detection. In: CVPR (2016)
Mnih, V., et al.: Human-level control through deep reinforcement learning. Nature 518(7540), 529 (2015)
Mousavian, A., Anguelov, D., Flynn, J., Košecká, J.: 3D bounding box estimation using deep learning and geometry. In: CVPR (2017)
Payet, N., Todorovic, S.: From contours to 3d object detection and pose estimation. In: ICCV (2011)
Pepik, B., Stark, M., Gehler, P., Schiele, B.: Multi-view and 3d deformable part models. TPAMI 37(11), 2232–2245 (2015)
Qin, Z., Wang, J., Lu, Y.: Monogrnet: a geometric reasoning network for monocular 3d object localization. In: AAAI (2019)
Rao, Y., Lu, J., Zhou, J.: Attention-aware deep reinforcement learning for video face recognition. In: ICCV (2017)
Rematas, K., Kemelmacher-Shlizerman, I., Curless, B., Seitz, S.: Soccer on your tabletop. In: CVPR (2018)
Ren, L., Yuan, X., Lu, J., Yang, M., Zhou, J.: Deep reinforcement learning with iterative shift for visual tracking. In: ECCV (2018)
Roddick, T., Kendall, A., Cipolla, R.: Orthographic feature transform for monocular 3d object detection. In: BMVC (2019)
Saxena, A., Driemeyer, J., Ng, A.Y.: Robotic grasping of novel objects using vision. IJRR 27(2), 157–173 (2008)
Schaul, T., Quan, J., Antonoglou, I., Silver, D.: Prioritized experience replay. In: ICLR (2016)
Simonelli, A., Bulò, S.R.R., Porzi, L., López-Antequera, M., Kontschieder, P.: Disentangling monocular 3d object detection. In: ICCV (2019)
Sutton, R.S., Barto, A.G.: Reinforcement Learning: An Introduction. MIT press, Cambridge (2018)
Wang, Y., Chao, W.L., Garg, D., Hariharan, B., Campbell, M., Weinberger, K.Q.: Pseudo-lidar from visual depth estimation: bridging the gap in 3d object detection for autonomous driving. In: CVPR (2019)
Xiang, Y., Choi, W., Lin, Y., Savarese, S.: Data-driven 3d voxel patterns for object category recognition. In: CVPR (2015)
Xiang, Y., Choi, W., Lin, Y., Savarese, S.: Subcategory-aware convolutional neural networks for object proposals and detection. In: WACV (2017)
Xu, B., Chen, Z.: Multi-level fusion based 3d object detection from monocular images. In: CVPR (2018)
Yoo, D., Park, S., Lee, J.Y., Paek, A.S., So Kweon, I.: Attentionnet: aggregating weak directions for accurate object detection. In: ICCV (2015)
Yu, Q., Xie, L., Wang, Y., Zhou, Y., Fishman, E.K., Yuille, A.L.: Recurrent saliency transformation network: incorporating multi-stage visual cues for small organ segmentation. In: CVPR (2018)
Yun, S., Choi, J., Yoo, Y., Yun, K., Young Choi, J.: Action-decision networks for visual tracking with deep reinforcement learning. In: CVPR (2017)
Acknowlegements
This work was supported in part by the National Key Research and Development Program of China under Grant 2017YFA0700802, in part by the National Natural Science Foundation of China under Grant 61822603, Grant U1813218, Grant U1713214, and Grant 61672306, in part by Beijing Natural Science Foundation under Grant No. L172051, in part by Beijing Academy of Artificial Intelligence (BAAI), in part by a grant from the Institute for Guo Qiang, Tsinghua University, in part by the Shenzhen Fundamental Research Fund (Subject Arrangement) under Grant JCYJ20170412170602564, and in part by Tsinghua University Initiative Scientific Research Program.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Liu, L., Wu, C., Lu, J., Xie, L., Zhou, J., Tian, Q. (2020). Reinforced Axial Refinement Network for Monocular 3D Object Detection. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, JM. (eds) Computer Vision – ECCV 2020. ECCV 2020. Lecture Notes in Computer Science(), vol 12362. Springer, Cham. https://doi.org/10.1007/978-3-030-58520-4_32
Download citation
DOI: https://doi.org/10.1007/978-3-030-58520-4_32
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-58519-8
Online ISBN: 978-3-030-58520-4
eBook Packages: Computer ScienceComputer Science (R0)