
Abstract
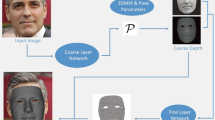
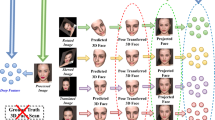
Recently, deep learning based 3D face reconstruction methods have shown promising results in both quality and efficiency. However, most of their training data is constructed by 3D Morphable Model, whose space spanned is only a small part of the shape space. As a result, the reconstruction results lose the fine-grained geometry and look different from real faces. To alleviate this issue, we first propose a solution to construct large-scale fine-grained 3D data from RGB-D images, which are expected to be massively collected as the proceeding of hand-held depth camera. A new dataset Fine-Grained 3D face (FG3D) with 200k samples is constructed to provide sufficient data for neural network training. Secondly, we propose a Fine-Grained reconstruction Network (FGNet) that can concentrate on shape modification by warping the network input and output to the UV space. Through FG3D and FGNet, we successfully generate reconstruction results with fine-grained geometry. The experiments on several benchmarks validate the effectiveness of our method compared to several baselines and other state-of-the-art methods. The proposed method and code will be available at https://github.com/XiangyuZhu-open/Beyond3DMM.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Amberg, B., Romdhani, S., Vetter, T.: Optimal step nonrigid ICP algorithms for surface registration. In: 2007 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8. IEEE (2007)
Bagdanov, A.D., Del Bimbo, A., Masi, I.: The florence 2D/3D hybrid face dataset. In: Proceedings of the 2011 Joint ACM Workshop on Human Gesture and Behavior Understanding, pp. 79–80. ACM (2011)
Bas, A., Huber, P., Smith, W.A., Awais, M., Kittler, J.: 3D morphable models as spatial transformer networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 904–912 (2017)
Bhagavatula, C., Zhu, C., Luu, K., Savvides, M.: Faster than real-time facial alignment: a 3D spatial transformer network approach in unconstrained poses (2017)
Blanz, V., Vetter, T.: Face recognition based on fitting a 3D morphable model. IEEE Trans. Pattern Anal. Mach. Intell. 25(9), 1063–1074 (2003)
Cai, Y., Lei, Y., Yang, M., You, Z., Shan, S.: A fast and robust 3D face recognition approach based on deeply learned face representation. Neurocomputing 363, 375–397 (2019)
Deng, Y., Yang, J., Xu, S., Chen, D., Jia, Y., Tong, X.: Accurate 3D face reconstruction with weakly-supervised learning: from single image to image set. In: IEEE Computer Vision and Pattern Recognition Workshops (2019)
Dou, P., Shah, S.K., Kakadiaris, I.A.: End-to-end 3D face reconstruction with deep neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5908–5917 (2017)
Feng, Y., Wu, F., Shao, X., Wang, Y., Zhou, X.: Joint 3D face reconstruction and dense alignment with position map regression network. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 534–551 (2018)
Hassner, T.: Viewing real-world faces in 3D. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 3607–3614 (2013)
Jackson, A.S., et al.: Large pose 3D face reconstruction from a single image via direct volumetric CNN regression (2017)
Guo, J., Zhu, X., Lei, Z.: 3DDFA (2018). https://github.com/cleardusk/3DDFA
Jourabloo, A., Liu, X.: Pose-invariant 3d face alignment. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 3694–3702 (2015)
Jourabloo, A., Liu, X.: Large-pose face alignment via CNN-based dense 3D model fitting. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4188–4196 (2016)
Kemelmacher-Shlizerman, I., Basri, R.: 3D face reconstruction from a single image using a single reference face shape. IEEE Trans. Pattern Anal. Mach. Intell. 33(2), 394–405 (2011)
Li, S.: Casia 3D face database - center for biometrics and security research (2004)
Liu, F., Tran, L., Liu, X.: 3D face modeling from diverse raw scan data. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 9408–9418 (2019)
Liu, F., Zeng, D., Zhao, Q., Liu, X.: Joint face alignment and 3D face reconstruction. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9909, pp. 545–560. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46454-1_33
Liu, Y., Jourabloo, A., Ren, W., Liu, X.: Dense face alignment. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1619–1628 (2017)
Mu, G., Huang, D., Hu, G., Sun, J., Wang, Y.: Led3D: a lightweight and efficient deep approach to recognizing low-quality 3D faces. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5773–5782 (2019)
Paysan, P., Knothe, R., Amberg, B., Romdhani, S., Vetter, T.: A 3D face model for pose and illumination invariant face recognition. In: Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance, AVSS 2009, pp. 296–301. IEEE (2009)
Phillips, P.J., et al.: Overview of the face recognition grand challenge. In: 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), vol. 1, pp. 947–954. IEEE (2005)
Richardson, E., Sela, M., Kimmel, R.: 3D face reconstruction by learning from synthetic data. In: 2016 Fourth International Conference on 3D Vision (3DV), pp. 460–469. IEEE (2016)
Richardson, E., Sela, M., Or-El, R., Kimmel, R.: Learning detailed face reconstruction from a single image. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1259–1268 (2017)
Romdhani, S., Vetter, T.: Efficient, robust and accurate fitting of a 3D morphable model. In: Proceedings of the Ninth IEEE International Conference on Computer Vision, pp. 59–66. IEEE (2003)
Romdhani, S., Vetter, T.: Estimating 3D shape and texture using pixel intensity, edges, specular highlights, texture constraints and a prior. In: 2005 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 2, pp. 986–993. IEEE (2005)
Saval-Calvo, M., Azorin-Lopez, J., Fuster-Guillo, A., Villena-Martinez, V., Fisher, R.B.: 3D non-rigid registration using color: color coherent point drift. Comput. Vis. Image Underst. 169, 119–135 (2018)
Sela, M., Richardson, E., Kimmel, R.: Unrestricted facial geometry reconstruction using image-to-image translation. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1576–1585 (2017)
Shen, T., Huang, Y., Tong, Z.: FaceBagNet: bag-of-local-features model for multi-modal face anti-spoofing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (2019)
Snta, Z., Kato, Z.: 3D Face Alignment Without Correspondences (2016)
Tewari, A., et al.: MoFA: model-based deep convolutional face autoencoder for unsupervised monocular reconstruction. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1274–1283 (2017)
Tran, A.T., Hassner, T., Masi, I., Paz, E., Nirkin, Y., Medioni, G.G.: Extreme 3D face reconstruction: seeing through occlusions. In: CVPR, pp. 3935–3944 (2018)
Tran, L., Liu, X.: Nonlinear 3D face morphable model. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018
Tran, L., Liu, X.: On learning 3D face morphable model from in-the-wild images. IEEE Trans. Pattern Anal. Mach. Intell. (2019)
Tuan Tran, A., Hassner, T., Masi, I., Medioni, G.: Regressing robust and discriminative 3D morphable models with a very deep neural network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5163–5172 (2017)
Zhang, S., et al.: A dataset and benchmark for large-scale multi-modal face anti-spoofing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 919–928 (2019)
Zhang, X., et al.: Bp4d-spontaneous: a high-resolution spontaneous 3d dynamic facial expression database. Image Vis. Comput. 32(10), 692–706 (2014)
Zhu, K., Du, Z., Li, W., Huang, D., Wang, Y., Chen, L.: Discriminative attention-based convolutional neural network for 3d facial expression recognition. In: 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), pp. 1–8. IEEE (2019)
Zhu, X., Lei, Z., Liu, X., Shi, H., Li, S.Z.: Face alignment across large poses: a 3D solution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 146–155 (2016)
Zhu, X., Lei, Z., Yan, J., Yi, D., Li, S.Z.: High-fidelity pose and expression normalization for face recognition in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 787–796 (2015)
Zhu, X., Liu, X., Lei, Z., Li, S.Z.: Face alignment in full pose range: a 3D total solution. IEEE Trans. Pattern Anal. Mach. Intell. 41(1), 78–92 (2019)
Zhu, X., Yi, D., Lei, Z., Li, S.Z.: Robust 3D morphable model fitting by sparse sift flow. In: 2014 22nd International Conference on Pattern Recognition, pp. 4044–4049. IEEE (2014)
Acknowledgment
This work was supported in part by the National Key Research & Development Program (No. 2020YFC2003901), Chinese National Natural Science Foundation Projects #61806196, #61876178, #61872367, #61976229, #61673033.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhu, X. et al. (2020). Beyond 3DMM Space: Towards Fine-Grained 3D Face Reconstruction. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, JM. (eds) Computer Vision – ECCV 2020. ECCV 2020. Lecture Notes in Computer Science(), vol 12353. Springer, Cham. https://doi.org/10.1007/978-3-030-58598-3_21
Download citation
DOI: https://doi.org/10.1007/978-3-030-58598-3_21
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-58597-6
Online ISBN: 978-3-030-58598-3
eBook Packages: Computer ScienceComputer Science (R0)