
Abstract
Deep neural network (DNN) which is applied to extract high-level features plays an important role in the Click Through Rate (CTR) task. Although the necessity of high-level features has been recognized, how to integrate high-level features with low-level features has not been studied well. There are some works fuse low- and high-level features by simply sum or concatenation operations. We argue it is not an effective way because they treat low- and high-level features equally. In this paper, we propose a novel hybrid feature fusion model named HFF. HFF model consists of two different layers: feature interaction layer and feature fusion layer. With feature interaction layer, our model can capture high-level features. And the feature fusion layer can make full use of low- and high-level features. Comprehensive experiments on four real-world datasets are conducted. Extensive experiments show that our model outperforms existing the state-of-the-art models.
This work was supported in part by the National Key Research and Development Program of China (No. 2018YFB1601102), and the Shenzhen Science and Technology Project under Grant (GGFW2017040714161462).
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


1 Introduction
CTR prediction is critical to many web applications including web search, recommendation system, sponsored search, and display advertising. The aim of this task is to estimate the probability that a user clicks on a given item. In online advertising application, which is a billions of dollars scenario, the precision of prediction has a direct impact on the final revenue of business providers. So CTR prediction with high precision is a core task of online advertising.
Combinatorial features are helpful for good performance in CTR prediction task. For example, it is reasonable to recommend Before Sunrise, a famous romance movie to an eighteen-year-old girl. In this case, \(<Gender=Female, Age=18, MovieGenre=Romance>\) is a third-order combinatorial feature which is informative for prediction. But it takes great efforts to explore the meaningful combinatorial features, especially when the number of raw features is huge. So a lot of works have been proposed to learn combinatorial features automatically by feature interactions. Factorization Machines (FM) [1,2,3] and its variants are widely used for modeling pairwise feature interactions. It captures second-order combinatorial features by modeling second-order feature interactions. But in real scenario, second-order feature interactions may not have enough expression ability. As aforementioned case, we need third-order feature interactions.
Extensive literatures [3,4,5] have shown that the high-order feature interactions are crucial for a good performance. With the success of deep learning in computer vision, speech recognition and natural language processing, some works [6,7,8,9] have been proposed to utilize DNN for CTR prediction task. They stack multiple interaction layers to extract high-level features. The deeper the network is, the more high-order feature interactions are captured by high-level features. CrossNet [9] applies a multi-layer residual network to learn high-level features. xDeepFM [5] stacks Compressed Interaction Network (CIN), which aims to learn high-order feature interaction explicitly, to extract high-level features. AutoInt cascades [4] multi-head self-attention layers [10] with residual connection for high-level features. But these models achieve the best performance when the depth of DNN is only 3 or 4. The performance of these models drop significantly as the number of interaction layers increases continuously. We argue that when these models go deeper, the high-level features capture more high-order feature interactions and lost more low-order feature interactions which are also essential for prediction. Even the models with residual connection also face the same problem. Although there are some hybrid models which contain low- and high-level features have been studied, such as Wide&Deep [6] and DeepFM [7], they both need extra models to capture low-level features. (Wide&Deep utilizes linear model (wide part) for low-level features. DeepFM applies FM for low-level feature.) What’s more, these models fuse high- and low-level features by simple sum or concatenation operations and can’t utilize low-level features effectively.
In this paper, we propose a novel hybrid feature fusion model named HFF. HFF model consists of two different layers: feature interaction layer and feature fusion layer. With the feature interaction layer, our model can extract high-level features. The outputs of the first few feature interaction layers can also be utilized as low-level features. So extra part isn’t necessary for low-level features in our model. After obtaining high- and low-level features, our feature fusion layer fuses them by multi-head self-attention mechanism. The experimental results show that our feature fusion layer can utilize these low-level features more effectively.
The contribution of our paper are summarized as follows:
-
We propose a novel hybrid feature fusion model named HFF for CTR prediction task which can not only extract high-level features but also make full use of low-level features which are also helpful for performance promotion;
-
Compared to simple sum or concatenation operations, we adopt multi-head self-attention mechanism to utilize low- and high-level feature effectively;
-
We conduct extensive experiments on four real-world dataset, and the results demonstrate that our HFF model outperforms the existing state-of-the-art models.
Our work is organized as follows. In Sect. 2, we summarize the related work. Section 3 presents our proposed model for CTR prediction task. In Sect. 4, we present experimental results and detailed analysis. We conclude this paper in Sect. 5.
2 Related Work
With the rapid development of online advertising, how to predict the probability of a user will click a recommended advertisement plays a significant role in recommendation systems. The accuracy of CTR prediction affects not only user experience but also the revenue of advertising agencies. So CTR prediction task has drawn great attention from both academia and industry.
Combinatorial features are helpful for good performance in CTR prediction task. In order to capture meaningful combinatorial features, engineers have to take a lot of manual efforts for cross features. To tackle the above problem, some models have been proposed to learn combinatorial features automatically by feature interactions. A well-known model is Factorization Machine (FM) [1]. This model transforms features into low dimension latent vector and learns second-order combinatorial features by modeling second-order feature interactions [11, 12]. Afterward, different variants of factorization machines have been proposed. Field-aware Factorization Machines (FFM) [2] extends FM by making the feature representation field-specific. AFM [3] improves performance by adding attention net and also offers good explainability.
Although FM based models can learn combinatorial feature automatically, they can only model the second-order feature interactions due to the architecture of FM. With the success of DNN, there are some works have been proposed to modeling higher-order feature interactions by DNN. With the depth of DNN increases, the more high-order feature interactions are captured by high-level features. PNN [13], FNN [14], and DeepCrossing [15] utilized a feed-forward neural network to learn high-level features. CrossNet [9] is proposed to capture high-level features by cross operation AutoInt [4] utilizes multi-head attention mechanism to extract high-level features.
Although DNN models perform well, the fact is that not deeper the DNN is, the better the model performs. With the increasing of network’s depth, the low-level features are ignored. This is detrimental to prediction performance. Some hybrid models have been proposed to combine high- and low-level features. Wide&Deep [6] combines a linear model (wide part) for low-level features and a DNN (deep part) for high-level features. In this model, two different inputs are required for the “wide part” and “deep part”, respectively, and the input of “wide part” still relies on expertise feature engineering. DeepFM [7] replaces the liner model in Wide&Deep with FM and add the raw features to the output of DNN. Both of the above hybrid models need extra models to capture low-level features and fuse high- and low-level features by simple sum or concatenation operations. To utilize high- and low-level features effectively, we propose a novel hybrid feature fusion model named HFF. The proposed model can capture low- and high-level features and make full use of them. The experimental results on four datasets show the effectiveness of our model.
3 Our Model
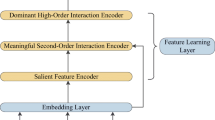
In this section, we start with problem definition. For a sample \(\{\mathcal {X}, \mathcal {Y}\}\), \(\mathcal {X}=\{\mathbf {x}_{{field}_1}, \cdots , \mathbf {x}_{{field}_m}, \cdots , \mathbf {x}_{{field}_M}\}\) is a M-fields features input which records the context information about user and item, and \(\mathcal {Y}\in \{0, 1\}\) is the associated label indicating user’s click behaviors (\(\mathcal {Y}=1\) means the user clicked the item, and \(\mathcal {Y}=0\) otherwise). \(\mathcal {X}\) may include categorical fields (e.g., gender, location) and continuous fields (e.g., age). Each categorical field is represented as a vector of one-hot encoding, and each continuous field is represented as the value itself. Normally, \(\mathcal {X}\) is high-dimensional and extremely sparse. The task of CTR prediction is to build a prediction model \(\hat{y}=F(\mathcal {X})\) to estimate the probability of a user clicking a specific item in a given context. The overall architecture of our proposed HFF model is shown in Fig. 1. Our model is composed of four parts: Embedding layer, Feature interaction layer, Feature fusion layer and Prediction layer. Compared to existing models, our model not only focuses on modeling high-level features but also make full use of low-level features which are essential to performance.

The overall architecture of our HFF model. Our model is composed of four parts: Embedding layer, Feature interaction layer, Feature Fusion layer and Prediction layer.
3.1 Embedding Layer
For input feature \(\mathcal {X}=\{\mathbf {x}_{{field}_1},\cdots , \mathbf {x}_{{field}_m}, \cdots , \mathbf {x}_{{field}_M}\}\), \(\mathbf {x}_{field_m}\) is a one-hot vector if the m-th field is categorical feature, while \(\mathbf {x}_{field_m}\) is a scalar value if the m-th field is numerical feature. For categorical feature, it often leads to excessively high-dimensional feature space for large feature size. To reduce such high-dimensional feature space, we employ an embedding procedure (similar to word embedding in NLP) to transform these binary features into dense vectors:
where \(\mathbf {e}_m \in \mathcal {R}^{d_e}\) is the categorical embedding vector of m-th filed, \(d_e\) is the dimension of embedding vector and \(\mathbf {x}_{{field}_m }\) is one-hot input in the m-th field, \(\mathbf {W}_m\) is embedding matrix of the m-th field. For the numerical feature, we represent it as:
where \(\mathbf {w}_m\) is the embedding vector of the m-th field, and \(\mathbf {x}_{{field}_m }\) is the scalar value of the m-th field. Finally, we obtain the input of Intra-layer FI layer as follows:
where \(\mathbf {W}_E \in \mathbb {R}^{d\times d_e}\) is transformation matrix in case of dimension mismatching. d is the number of hidden units of Intra-layer FI layer.
3.2 Feature Interaction Layer
For feature interaction layer, we model high-level features by multi-head self-attention mechanism [10] which was proposed in the area of natural language processing. With this mechanism, it is easy to capture rich and effective feature interactions. The multi-head mechanism transposes features into different semantic subspaces and helps to learn the diversified polysemy of feature. The self-attention mechanism determines which features should be combined to form meaningful high-level features. We stack L feature interaction layers to capture high-level features.
For l-th feature interaction layer, the input is the output of the previous layer \(\mathbf {H^{l-1}} = [\mathbf {h}^{l-1}_{1}; \cdots ; \mathbf {h}^{l-1}_{m}; \cdots ; \mathbf {h}^{l-1}_{M}]\). Firstly, we split \(\mathbf {h}^{l-1}_{m}\) into N heads \(\{\mathbf {h}^{l-1}_{m,n}\}_{n=1}^N\) and then apply a N heads self-attention setup:
where \(\oplus \) denotes the concatenation operator and \(\mathbf {W}^l_{V,n} \in \mathbb {R}^{d \times d}\) is transformation matrix. Attention function \(a(\cdot , \cdot )\) is calculated in the following form:
where \(\mathbf {W}_Q, \mathbf {W}_K \in \mathbb {R}^{d \times d}\) are transformation matrices for \(\mathbf {q}_m\) and \(\mathbf {k}_j\) respectively, and the result is scaled by \(\frac{1}{\sqrt{d}}\) [10].
To obtain the output of l-th layer, a norm layer is added:
where \(ReLU(z)=max(0,z)\) is a non-linear activation function.
3.3 Feature Fusion Layer
Previous models focused on modeling high-level features and pay less attention on low-level features which are also essential for prediction accuracy. So we propose feature fusion layer to make full use of low-level features. The input of feature fusion layer is \(\mathbf {H}=[\mathbf {h}^0;\cdots ;\mathbf {h}^l;\cdots ;\mathbf {h}^L]\), which are combined by the outputs of embedding layer and L feature interaction layer. For \(\mathbf {h}^l=[\mathbf {h}_1^l\oplus \cdots \oplus \mathbf {h}_m^l \oplus \cdots \oplus \mathbf {h}_M^l]\), \(\mathbf {h}^l\) is the output of embedding layer when \(l=0\) and \(\mathbf {h}^l\) is the output of l-th feature interaction layer when \(l \in \{1, \cdots , L\}\).
For dimension matching, an affine transformation is firstly applied as follows:
where \(\mathbf {W}_H \in \mathbb {R}^{d_h \times d}\) is transformation matrix. To utilize all the features effectively, we also adopt muti-head self-attention mechanism to modeling interaction between high-level and low-level features. Firstly, we split \(\mathbf {\tilde{h}}^l\) into N heads \(\{\mathbf {\tilde{h}}^{l}_{n}\}_{n=1}^N\) and then apply a N heads self-attention setup:
where \(\alpha (\cdot )\) is similar to eq. (7) and \(\mathbf {W}^o_{V,n} \in \mathbb {R}^{d_h \times d_h}\) is a transformation matrix. Finally, we obtain the output of feature fusion layer as follows:
3.4 Prediction Layer
We simply concatenate all the output of feature fusion layer and then apply a non-linear projection to predict the click probability:
where \(\mathbf {w}\in \mathbb {R}^{D}\) ( \(D=(L+1)\times d_h\)) is a column projection vector, \(b\in \mathbb {R}\) is bias, and \(\sigma (x)=1/(1+\exp (-x))\).
We choose LogLoss which is widely used in CTR prediction task as our target loss function:
where \(y_i\) and \(\hat{y}_i\) are ground truth and predicted user click. N is the total number of training samples. The parameters are learned by minimizing the total LogLoss using gradient descent.
4 Experiments
To show the effectiveness of our HFF model, We conduct extensive experiments on four public real-world datasets. We present all the experimental results in this section. Codes for fully reproducibility will be open source soon after necessary polishment.
4.1 Datasets
We evaluate the performance of our model on four public real-world datasets, which are CriteoFootnote 1, AvazuFootnote 2, KDD12Footnote 3 and MovieLens-1MFootnote 4. Criteo is a benchmark dataset for CTR prediction published by criteo lab. It contains 26 categorical feature fields and 13 numerical feature fields. Avazu contains users’ mobile behaviors including whether a displayed mobile ad is clicked by a user or not. It has 23 feature fields spanning from user/device features to ad attributes. KDD12 was released by KDDCup 2012, which originally aimed to predict the number of clicks. Since our work focuses on CTR prediction rather than the exact number of clicks, we treat this problem as a binary classification problem (1 for clicks, 0 for without click). MovieLens-1M contains users’ratings on movies. During binarization, we treat samples with a rating less than 3 as negative samples because a low score indicates that the user does not like the movie. We treat samples with a rating greater than 3 as positive samples and remove neutral samples, i.e., a rating equal to 3. In Table 1, we present the statistics of the four datasets.
4.2 Data Preparation
All the data preparation strategies are similar to AutoInt [4]. First, we remove the infrequent features (appearing in less than threshold instances), where threshold is set to 10, 5, 10 for Criteo, Avazu and KDD12 data sets respectively. And we keep all features for MovieLens-1M. Then, we normalize numerical values by transforming a value z to \(log^{2}(z)\) if \(z > 2\). Finally, we randomly select 80% of all samples for training and randomly split the rest into validation and test sets with equal size.
Evaluation Metrics. We use two metrics to evaluate the performance of all models: AUC (Area Under the ROC curve) and Logloss (cross entropy).
-
AUC. AUC measures the probability that a positive instance will be ranked higher than a randomly chosen negative one. It only takes into account the order of predicted instances and is insensitive to class imbalance problem. A higher AUC indicates a better performance.
-
Logloss. Logloss measures the distance between the predicted score and the true label for each instance. This metric is defined in Eq. 15.
It is noticeable that a slightly higher AUC or lower Logloss at 0.001-level is regarded significant for CTR prediction task, which has also been pointed out in existing works [6, 7, 9].

Impact of network hyper-parameters on AUC and Logloss performance.
Model Comparison. We compare 9 models in our experiments: LR, FM [1], Wide&Deep [6], Deep&Cross [9], AFM [3], NFM [8], DeepFM [7], xDeepFM [5], and AutoInt [4].
Implementation Details. Our models are trained to minimize the loss in Eq. 15 in an end-to-end fashion. We choose Adam as optimizer. The embedding size is 16 and the number of attention head is 2. The number of hidden units for feature interaction layer and feature fusion layer are both 64. We set the number of feature interaction layers to 3.
4.3 Experimental Results
The performance for CTR prediction of different models on four datasets is shown in Table 2. In CTR prediction tasks, a slightly higher AUC or Logloss value at 0.001-level is regarded as a huge improvement. We can observe that our HFF model outperforms all other models on four datasets. This shows the effectiveness of our HFF model. Note that AutoInt also utilizes the same multi-head self-attention mechanism as our HFF model to capture high-level feature. But AutoInt performs worse than our model on four datasets. Our model also outperforms hybrid models like Wide&Deep and DeepFM. All the above observations indicates the importance of feature interaction layer and the effectiveness of our feature fusion layer.
4.4 Analysis
The Efffect of Hyper-Parameters. In this section, we mainly analysis the impact of hyper-parameters on our HFF model. We conduct experiments on MovieLens-1M dataset and analysis from the following three aspects: the number of feature interaction layers, the number of hidden units in feature interaction layer and the number of hidden units in feature fusion layer.
As shown in Fig. 2(a), model performance increases steadily when increasing the number of feature interaction layers from 1 to 3 and achieves best performance when the layer number is 3. However, when the number of feature interaction layers is greater than 3, the model performance degrades. So the most suitable number of feature interaction layers is 3.
Figure 2(b) and 2(c) demonstrate how the number of hidden units in feature interaction layer and feature fusion layer impact the model performance. In Fig. 2(b), our model achieves the best performance on Logloss when the number of hidden units in feature interaction layer is 64. But our model obtain the highest AUC value when the number of hidden units is 80. Considering that the AUC value achieved when the number of hidden units is 64 is only slightly lower than the value achieved when the number is 80. We set the number of hidden units in feature intercation layer to 64 for less model parameters. In Fig. 2(c), we can observe that the performance of our model increases with the number of hidden units in feature fusion layer. However, model performance degrades when the number of hidden units in feature fusion layer is set greater than 64.

Performance w.r.t the number of interaction layers for different models.
Analysis on Effectiveness and Efficiency. To prove the effectiveness of our HFF model, we conduct the following experiments on MovieLens-1M dataset.
We choose AutoInt [4] as our comparative model because it extracts high-level feature with the same multi-head self-attention mechanism as our HFF model. And we also keep the number of hidden units in interaction layer equally for AutoInt and our HFF model. If the number of feature interaction layers is L, AutoInt only utlizes the features of the last L-th interaction layer to predict the result and ignores the low-level features captured by the first 1-th to \((L-1)\)-th interaction layers. To prove the importance of low-level features, We add a model named AutoInt(high&low). The AutoInt(high&low) concatenates the outputs of all L interaction layers in AutoInt to predict the result.
As shown in Fig. 3, with the increase of interaction layers, the performance of AutoInt degrades quickly because the information in low-level features lost. But AutoInt(high&low) and our HFF model don’t perform badly as the number of interaction layers increases, which exactly shows the importance of low-level features. Our HFF model still outperforms AutoInt(high&low) which introduces low-level features by simple concatenation operation. It demonstrates the power of our feature fusion layer.
We fix the number of feature interaction layers to 3 and decrease the number of hidden units for feature interaction layer and feature fusion layer from 64 to 40. As shown in Tab. 3, our HFF model has less parameters than AutoInt. But our little model still performs better than AutoInt, which furtherly demonstrates the efficiency and the effectiveness of our model.
5 Conclusion
In this paper, we proposed a novel model named HFF for CTR prediction. HFF consists of feature interaction layer and feature fusion interaction. So, our model can not only capture high-level feature, but also make full use of low-level feature whichs most high-level based models ignore. The experimental results on four open datasets show the effectiveness of our approach.
References
Rendle, S.: Factorization machines. In: ICDM 2010, pp. 995–1000 (2010)
Juan, Y., Zhuang, Y., Chin, W., Lin, C.: Field-aware factorization machines for CTR prediction. In: RecSys 2016, pp. 43–50 (2016)
Xiao, J., Ye, H., He, X., Zhang, H., Wu, F., Chua, T.: Attentional factorization machines: learning the weight of feature interactions via attention networks. In: IJCAI 2017, pp. 3119–3125 (2017)
Song, W., et al.: Autoint: automatic feature interaction learning via self-attentive neural networks. In: Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM 2019, Beijing, China, 3–7 November, pp. 1161–1170 (2019)
Lian, J., Zhou, X., Zhang, F., Chen, Z., Xie, X., Sun, G.: xDeepfm: combining explicit and implicit feature interactions for recommender systems. In: ACM SIGKDD 2018, pp. 1754–1763 (2018)
Cheng, H., et al.: Wide & deep learning for recommender systems. In: DLRS@RecSys 2016, pp. 7–10 (2016)
Guo, H., Tang, R., Ye, Y., Li, Z., He, X.: Deepfm: a factorization-machine based neural network for CTR prediction. In: IJCAI 2017, pp. 1725–1731 (2017)
He, X., Chua, T.: Neural factorization machines for sparse predictive analytics. In: ACM SIGIR 2017, pp. 355–364 (2017)
Wang, R., Fu, B., Fu, G., Wang, M.: Deep & cross network for ad click predictions. In: ADKDD 2017, pp. 1–7 (2017)
Vaswani, A., et al.: Attention is all you need. In: NIPS 2017, pp. 6000–6010 (2017)
Rendle, S., Freudenthaler, C., Schmidt-Thieme, L.: Factorizing personalized Markov chains for next-basket recommendation. In: WWW 2010, pp. 811–820 (2010)
Rendle, S., Gantner, Z., Freudenthaler, C., Schmidt-Thieme, L.: Fast context-aware recommendations with factorization machines. In: ACM SIGIR 2011, pp. 635–644 (2011)
Qu, Y., et al.: Product-based neural networks for user response prediction. In: ICDM 2016, pp. 1149–1154 (2016)
Zhang, W., Du, T., Wang, J.: Deep learning over multi-field categorical data. In: Ferro, N., et al. (eds.) ECIR 2016. LNCS, vol. 9626, pp. 45–57. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-30671-1_4
Shan, Y., Hoens, T.R., Jiao, J., Wang, H., Yu, D., Mao, J.C.: Deep crossing: Web-scale modeling without manually crafted combinatorial features. In: ACM SIGKDD 2016, pp. 255–262 (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Shi, Y., Yang, Y. (2020). HFF: Hybrid Feature Fusion Model for Click-Through Rate Prediction. In: Yang, Y., Yu, L., Zhang, LJ. (eds) Cognitive Computing – ICCC 2020. ICCC 2020. Lecture Notes in Computer Science(), vol 12408. Springer, Cham. https://doi.org/10.1007/978-3-030-59585-2_1
Download citation
DOI: https://doi.org/10.1007/978-3-030-59585-2_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-59584-5
Online ISBN: 978-3-030-59585-2
eBook Packages: Computer ScienceComputer Science (R0)