
Abstract
Content caching in mobile edge networks has stirred up tremendous research attention. However, most existing studies focus on predicting content popularity in mobile edge servers (MESs). In addition, they overlook how the content is cached, especially how to cache the content with user devices. In this paper, we propose CMU, a three-layer (Cloud-MES-Users) content caching framework and investigate the performance of different caching strategies under this framework. A user device who has cached the content can offer the content sharing service to other user devices through device-to-device communication. In addition, we prove that optimizing the transmission performance of CMU is an NP-hard problem. We provide a solution to solve this problem and describe how to calculate the number of distributed caching nodes under different parameters, including time, energy and storage. Finally, we evaluate CMU through a numerical analysis. Experiment results show that content caching with user devices could reduce the requests to Cloud and MESs, and decrease the content delivery time as well.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
To cope with massive data traffic brought by the ever-increasing mobile users, the traditional centralized network model exhibits the disadvantages of high delay, poor real-time and high energy consumption. To solve these problems, the mobile edge network model is proposed, which can provide cloud computing and caching capabilities at the edge of cellular networks. According to the survey report by Cisco [1], the number of connected devices and connections will reach 28.5 billion by 2022, especially mobile devices, such as smartphones, which will reach 12.3 billion. Cisco also points out that traffic of video will account for 82% of the total IP traffic. Due to the massive content transmission traffic generated by user requests, content caching is regarded as a research hotspot of mobile edge network [2, 3]. Liu et al. [4] also indicates that mobile edge caching can efficiently reduce the backhaul capacity requirement by 35%.
When a user requests the content in a traditional centralized network, the content will be provided by a remote server or Cloud, wherein there is usually duplicated traffic during the content transmission. By caching the content from the Cloud to the edge of the network (e.g., gateway and base station), the duplicated traffic can be avoided when the user chooses the closest mobile edge server. At the same time, it has a better network quality than the traditional centralized network. Due to the limited storage space, user devices cannot cache all the contents. But with the development of the hardware, the computing and storage capabilities of mobile devices have been improved greatly. Even though the storage capabilities of a user device cannot be compared with that of Cloud and MES, we can build a huge local content caching network relying on the explosive growth of mobile devices, which could use D2D to provide content sharing services [13, 14]. More and more studies show that a local content caching network has a great potential to achieve content sharing.
In this paper, we apply a three-layer content caching framework in the mobile edge network and aim to investigate the performance of different caching ways under this framework. Caching the content from Cloud and MES to user device could reduce the requests to Cloud and MES, as well as save the valuable bandwidth resources. It can also reduce the content transmission time and energy consumption. Paakkonen et al. [18] studies the performance of local content caching network when using different caching ways. We refer their caching strategies and make these caching strategies applicable to both MESs and user devices. We assume that the content popularity is known and it conforms to the ZipF model [22]. The main contributions of this paper can be summarized as follows. (1) We combine MESs and user devices to cache the content to create a multi-layer mobile edge caching framework. To the best of our knowledge, content caching that is assisted by user devices in mobile edge network has not been well studied in previous work. (2) We prove that minimizing transmission costs between MESs and user devices is an NP-Hard problem. We provide a solution to solve this problem and describe how to calculate the number of distributed caching nodes in a cluster. (3) We evaluate the performance of different caching strategies under the proposed framework through a numerical analysis. Results show that caching contents with user devices is feasible and effective.
The rest of the paper is organized as follows. Section 2 presents the related work. Section 3 introduces the proposed framework. Problem description and theoretical derivation are presented in Sect. 4. Numerical analysis results are shown in Sect. 5. Finally, the paper is concluded in Sect. 6.
2 Related Work
Recent studies use different machine learning methods to predict the popular content or apply other technologies to maximize the storage and computing capabilities of MESs [5,6,7,8,9,10,11,12]. For example, Chen et al. [5] used a self-supervising deep neural network to train the data and predict the distribution of contents. Liu et al. [9] proposed a novel MES-enabled blockchain framework, wherein mobile miners utilize the closest MES to compute or cache the content (storing the cryptographic hashs of blocks). In these studies, even there are many caching strategies, the predicted contents are simply copied in MESs and the main optimization objective is the MES. A survey of content caching for mobile edge network [3] indicated that mobile traffic could reduce one to two thirds by caching at the edge of the network. In addition, D2D as one of the key technologies of 5G could easily help user to utilize the locally stored resources. And the QoE of users could have a great improvement by local content caching [15, 17]. Video traffic accounts for the vast majority of IP traffic [1], and Wu et al. [16] proposed a user-centric video transmission mechanism based on D2D communications allowing mobile users to cache and share videos with each other. Paakkonen et al. [18] also investigated different D2D caching strategies.
Existing studies have combined the local devices with the cellular network for traffic offloading. Kai et al. [23] considered a D2D-assisted MES scenario that achieves the task offloading. Zhang et al. [24] focused on the requested contents cached in the nearby peer mobile devices. They aimed to optimize the D2D throughput while guaranteeing the quality of D2D channels. However, devices randomly cached the popular contents and there was no global content caching policy. In addition, devices are distributed within a small range so that the communication could be established at any time. But in practice, we should consider the scenario where the requesting device is far from the caching device.
3 System Model
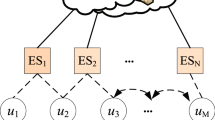
The mobile edge network structure used in this paper is shown in Fig. 1. The top layer is the Cloud, followed by the mobile edge server layer and the local user device layer. In the local user device layer, the devices (nodes) are divided into two types, i.e., Normal node and Caching node. When a device requests the content, the sequence of the request is Local \({>}\) \({>}\) MES \({>}\) \({>}\) Cloud.

The architecture of the mobile edge network.
3.1 Caching Strategies
Four caching strategies are adopted, and some contents are randomly distributed across the MESs in the beginning.
Default Caching (DC): Some contents are randomly stored in the MESs and remain unchanged. If the MESs do not have the requested content, the request will be sent to the Cloud.
Replication Caching (RC): User caching nodes are called the caching nodes, and MES is called the caching server. The MESs and user nodes store a full copy of each content when the transmission process is finished. User nodes are regarded as the content servers after they cache the contents. They could send the desired content to the requesting device by the D2D communication. But if the caching node leaves, all the caching contents are lost. It has to request the desired content from the farther caching nodes or the MESs.
Distributed Replication Caching (DRC): User caching nodes are called the distributed caching nodes, and MES is called the distributed caching server. Assuming that the number of user nodes is N, and n (\(n\,{<}{<}\,N\)) nodes are selected as the distributed caching nodes by MESs. Distributed caching nodes are responsible for content sharing to the normal nodes. Note that, distributed caching nodes do not actively request any content for themselves. If a distributed caching node requests the content for a normal node from the upper layer, all distributed caching nodes cache the full copy of each content, which is returned from the upper layer. That is to say each content is cached in n nodes. When a distributed caching node leaves its cluster, an available node from that cluster will replace it. Using this strategy, the cached contents are not easily lost. But there is an additional compensation consumption when a new distributed caching node recovers the previously cached content.
Distributed Fragment Caching (DFC): Different from DRC, the content is divided into several parts according to the number of distributed caching nodes in the requesting cluster. That is to say each distributed caching node stores a part of the content. The upper layer performs the content fragmentation automatically during the experiment. Note that MESs use the DRC caching strategy when user nodes use DFC.
3.2 User State
We assume that state space of a user is \( State= \left\{ Leave,Stay,Request \right\} \), and the state-transition is a Markov chain with two reflective walls on a straight line as shown in Fig. 2.

The state-transition diagram.
Where Leave means the user leaves and deletes the cached contents. The probability of Leave is \( p_{l} \). We assume that a user returns back to the cluster conforming to the Poisson process. Stay means the user stay in the place with no actions, and the probability of Stay is \( p_{s} \). Request means the user requests the desired content, and the probability of Request is \( p_{r} \). We have \( p_{s}+ p_{r}+p_{l}=1 \). We assume that the number of all the users is \( \mathcal {N} \), \( \mathcal {N}=\left\{ 1,2,...,n \right\} \). The state matrix of the user is denoted by \( State=\left\{ State_{ij} \mid i\in N, j=1,2,3 \right\} \). We use 0 and 1 to represent the user state, where 1 represents that the user is in the corresponding state. The users can utilize the Service Set Identifier (SSID) to access the cached content and sense the state of other users. In addition, the users could receive the data from the MESs while they share the data to the other user devices. To avoid the transmission game, we define a game strategy set of \( a_{n}\in \left\{ 0 \right\} \cup \mathcal {N} \), wherein \( a_{n}>0 \) means the user of n is willing to provide the content sharing service. The value of \( a_{n} \) is subtracted by 1 whenever the content is transmitted successfully. If \( a_{n} = 0 \), the user n is willing to request its desired content, and set \( a_{n} \) with the default value after successfully requesting.
4 Theoretical Analysis
We first introduce the NP-Hard problem and present how to calculate the performance of each caching strategy. Then, the derivation of calculating the number of the distributed caching nodes is presented.
4.1 Problem Formulation and Solution
The contents are denoted as \( \mathcal {R}=\left\{ r_{1},...,r_{E} \right\} \), and the size of each content is set to s.There are m MESs and the set of MESs is denoted as \( \mathcal {S}=\left\{ S_{1},...,S_{m} \right\} \). The set of \( \alpha =\left\{ \alpha _{1},...,\alpha _{m}\right\} \) means the maximum storage space of the MESs, while \( \beta = \left\{ \beta _{1},...,\beta _{n} \right\} \) is the maximum storage space of the users. And we have \( \beta \,{<}{<}\,\alpha \). The content caching matrix of the MESs is \(X=\left\{ X_{m,E}\mid S_{m}\in \mathcal {S},r_{E}\in \mathcal {R}\right\} \), and the content matrix of the users is \(Y=\left\{ Y_{n,E}\mid n\in \mathcal {N},r_{E}\in \mathcal {R}\right\} \). If a mobile edge server of m has cached the content of E, then \( X_{m,E} = 1 \), otherwise \( X_{m,E} = 0 \). The content matrix of the users has the same operations. The storage space of the MESs and the users should meet the following constraints.
When the storage space reaches to the maximum capacity and a copy of new content needs to be cached, the Least Recently Used (LRU) algorithm is utilized to realize the space release and content replace. In addition, we assume that the transmission consumption of the users is \( \eta _{u} \), and the transmission rate is \( TR_{u} \). The values for each MES are marked as \( \eta _{s} \) and \( TR_{s} \). Similarly, the symbols of the Cloud are \( \eta _{c} \) and \( TR_{c} \). We assume that \( C^{E}\) is the energy consumption and \( T^{E} \) is the time overhead caused by transmitting the content of E. We should make sure that the energy consumption and the time overhead are minimized during each transmission. e.g., node k transmits the content of E to node o, \( C^{E}_{k,o} \) and \( T^{E}_{k,o} \) should reach the minimum. That is to say the distance or the route path between them should be minimized. The distance matrix of the users is denoted as \( DU=\left\{ DU_{i,j}\mid i,j=1,2,...,n;i\ne j\right\} \), while for each MES, the expression is \( DS=\left\{ DS_{i,j}\mid i,j=1,2,...,m;i\ne j\right\} \). When the content of E is transmitted from node k to node o, the following constraints (Problem 1, P1) should be satisfied.
Where, after the transmission is completed, the required caching space should not exceed the maximum storage capacity of the node. During the transmission process, the shortest distance or route path should be chosen.
Theorem 1
Energy consumption and time overhead reach the minimum in P1 is an NP-Hard problem.
Proof
Travel Sale-man Problem (TSP) is a classical NP-Hard problem. During the experiment, we assume that any object (i.e., any user) of \( o\in \left\{ \mathcal {N}\right\} \) requests the content from the Cloud. The Cloud sends the content to the request object of o going through the MES layer and the user layer. The route path of the user layer is \( R_{user} \), and the consumption of the single-hop routing is \(\nu _{u}\). Let \( R_{sever} \) denote the route path of the MES layer, and the consumption of the single-hop routing is \(\nu _{s}\). We have \( \nu _{all}= \nu _{u}*R_{user}+ \nu _{s}* R_{sever} \), and our goal is to minimize \( \nu _{all} \). We treat the request object of o as the Sale-man and consider the Cloud as the destination. The total number of the travel itinerary between them is \( R_{user}+ R_{sever} \), and there are \( R^{R_{sever}}_{user} \) schemes. We need to find the smallest \( \nu _{all} \) of these schemes. Therefore, P1 is equivalent to the Travel Sale-man Problem, i.e., P1 is NP-Hard.
Since P1 is NP-hard, we need to resort to a sub-optimal solution for P1. We use a clustering algorithm to reduce the number of the available route paths, e.g., the improved K-means++ algorithm. In RC, the requesting nodes give priority to scanning other nodes within their own clusters. Frequent communication can enrich the cache community greatly. In the distributed caching strategies, each cluster has its own distributed caching nodes, wherein the normal nodes could request the contents from the closest distributed caching nodes.
The clustering algorithms can be used for both the MES layer and the user layer, and we take the user layer as an example to illustrate. The coordinate vectors of the users is regarded as the training sample, which is denoted as \( I=\left\{ I_{i}\mid I_i\in R^2, i=1,2,3,...,n\right\} \), e.g., \(I_{i}=\left\{ x_{i},y_{i}\right\} \). There are K clusters, e.g., \( \varPhi =\left\{ \varPhi _{1},...,\varPhi _{K}\right\} \). The center of the cluster is denoted as \( \pi =\left\{ \pi _{i},...,\pi _{K}\right\} \). The number of the cluster members is denoted as \( \varphi =\left\{ \varphi _{1},...,\varphi _{K}\right\} \). We calculate the euclidean distance of each sample from the center. For \( \forall I_{i}\in \varPhi _{i} \), we have:
The indicator function g is used to check whether the distance between the center and each sample is the shortest, which is expressed as
When \( \sum \limits _{i=1}^{n}{\sum \limits _{j=1}^{K}g_{i,j}} \) is at its maximum, the error rate of cluster is the lowest. The new centres will be calculated by the following expression.
We use the improved K-means++ algorithm as shown in Algorithm 1.
If the center nodes are randomly selected and they are too close to each other, the convergence will become slow, which degrades the performance of K-means. Therefore, how to select the initial center nodes is optimized in Algorithm 1 (line 1–line 11). We select the farthest node from the existing centres every time, so the selected center could cover all the samples as far as possible. When the center selection process is completed, the iteration process is enabled (line 12–line 17).
4.2 Performance Formulation
To better describe the performance, we have \(\mathcal {B}=\left\{ b_{1},...,b_{n},b_{n+1},...,b_{n+m}\right\} \). For example, \( b^{E}_{u}=1\) is utilized to represent that the content of E is transmitted by the user node of u.

Default Caching and Replication Caching have the same performance expressions from the aspects of storage, energy and time. The utilized storage space is represented as follows.
\( C^{E} \) is expressed as:
\( T^{E} \) is expressed as:
Distributed Caching. When using the distributed caching strategies of DRC and DFC, the requesting nodes first request a distributed caching node. If the required content is not found, the distributed caching node will request the closest distributed caching server. Then, the required content is cached by the distributed caching node and transmitted to the requesting nodes by D2D communication. To prevent the requesting nodes from the same cluster to occupy too much bandwidth resources of the closest distributed caching server, contents are always sent from distributed caching servers to distributed caching nodes by default. If the distributed caching server does not have the requested content, it will request the Cloud with the same process. There are K clusters in the user layer divided by K-means++. However, each cluster cannot specify only one node as the distributed caching node. If there is only one distributed caching node, it will be difficult to handle a large number of concurrent requests, because transmitting the content to the requesting nodes from one distributed caching node by D2D communication is infeasible.
Taking the user cluster as an example, \(\xi \) denotes the number of distributed caching nodes. It is assumed that \( \xi _{K} \) nodes are selected from cluster K as the distributed caching nodes to cache and share the contents. For the distributed caching strategies of DRC and DFC, the multi-objective optimization problem (Problem 2, P2) is expressed as follows.
Where, \( f_{1} \) denotes the storage space, and \( f_{1} \) of each node can not exceed the limit value. Similarly, \( f_{2} \) denotes the time required to complete all of the requests, and \( f_{3} \) denotes the energy consumption caused by all of the successful requests. The optimization object of \( f_{1} \) is opposite to \( f_{2} \) and \( f_{3} \). When \( f_{1} \) decreases, fewer distributed caching nodes provide the content sharing services, but at the same time, \( f_{2} \) and \( f_{3} \) increase. When minimizing \( f_{2} \) and \( f_{3} \), \( f_{1} \) increases.
In order to solve P2, the Linear Weighting Method is adopted to make P2 become a single-objective optimization problem. The weight vectors are denoted as \( u=\left\{ u_{i}\mid u_{i}\ge 0,i=1,2,3\right\} \), and \( \sum \limits _{i=1}^{3}{u_{i}=1} \). Each weight coefficient is corresponding to \( f_{i} \) in P2. Then P2 can be expressed as follows.
Let \( u_{i}=\xi _{i}\). And \( \xi _{i} \) is satisfied by expression (9).
Where, \( \xi _{i} \) is the optimization value making the object of \( f_{i} \) reach the minimum. Then we have the following expression.
We substitute Eq. (10) into Eq. (8).
\(\bar{\beta }\) is the average caching space, \(\bar{T}\) is the average transmission time and \(\bar{C}\) is the average energy consumption. We take the derivative of \( \xi _{K} \) and set Eq. (11 ) to 0. Then we have the following expression.
The result is an efficient solution to Eq. (11). It is round up to an integer and considered as the number of the distributed caching nodes. We then discuss the performance of DRC and DFC.
1) Distributed Replication Caching (DRC): MES layer has KS clusters, e.g., \( \psi =\left\{ \psi _{1},...,\psi _{KS}\right\} \). The number of the distributed caching servers in each cluster is denoted as \( \bar{S} \). The utilized caching space can be estimated by the following expression.
The distributed caching servers within a cluster cache the same contents so that only the copies of the content cached in one distributed caching server need to be recorded. Then, multiplying the copies by the content size and the number of the distributed caching servers, the result is the utilized caching space. In addition, in order to guarantee the consistency of the distributed caching servers, Algorithm 2 is applied to add and delete the content. We take the MES layer as an example to illustrate the algorithm. The energy consumption can be calculated by Eq. (6). But if the content of E is transmitted from the upper layer, it needs to be cached in the distributed caching server, as well as the distributed caching nodes. So each layer will have additional transmission consumption: multiplying the number of distributed caching servers or nodes by \( C^E \). When a distributed caching node leaves, an available node from the same cluster will be selected as the new distributed caching node. The selection rule follows Algorithm 1 (line 1–line 11 ). The extra consumption caused by recovering the cached content is also calculated by Eq. (6). We denote \( \bar{N}_{r} \) as the number of nodes requesting content of E simultaneously. If the requesting nodes are more than the distributed caching nodes, some requesting nodes have to wait until the distributed caching nodes have the capacity to provide the content sharing services. The required time is calculated by the following expression.

2) Distributed Fragment Caching (DFC): The content is divided into several parts. The size of each part of the content is different across the clusters. The caching space is expressed as follows.
If the target distributed caching node is busy, other parts of the required content will be transmitted from other distributed caching nodes. The required time is expressed as follows.
The energy consumption can be calculated by Eq. (6). There is no extra transmission consumption when the content is transmitted from the upper layer, because the total size that needs to be transmitted is equal to the size of the original content. When a node is selected as the new distributed caching node, the extra consumption caused by recovering the cached content is calculated by \( \sum \limits _{i=1}^{E}{C^{i}} \), wherein
If all the distributed caching nodes are busy, the MESs will help to recover the cached content. Then, for each content that needs to be recovered, the extra consumption is calculated by \( C=\eta _{s} \cdot \frac{s}{\xi } \).
5 Experiment
5.1 Experiment Setup
10 MESs and 100 user nodes are randomly distributed within \(500\,\times \,500\,\)m. The simulation ends after the transmission is performed for 5000 times successfully. The caching space of each MES is 100 MB, while the size of each user node is 20 MB. We assume that the expectation of the Poisson process for the leaving nodes is 100. All the MESs are distributed caching servers in their own clusters, and they will not leave their places. The transmission parameters are set according to a survey report [25], where \( \eta _{u} \) is 5 j/MB. The MESs and the Cloud utilize the cellular network, where \( \eta _{s} \) and \( \eta _{c} \) are 100 j/MB. The transmission rate of the user is between 54 Mb/s and 11 Mb/s within 200 m, while for the MESs, the value is between 1 Mb/s and 0.5 Mb/s within 500 m. The value for the Cloud is set to 0.5 Mb/s. There are 1000 video items and the size of each item is 20 Mb. The popularity distribution of the items is generally modeled as a ZipF distribution. The default shape parameter \( \theta \) is set to 0.56 [26]. The default game strategy value of a is set to 1. The default requesting probability of \( p_r \) is 0.6, and \( p_s \) is equal to \( p_l \), i.e., 0.2.
In addition, we add two comparison objects, i.e., DRC-Extra and DFC-Extra. All user nodes in RC could cache the contents, while only the distributed caching nodes have the caching ability in DRC and DFC. Therefore, to guarantee the same caching capacity, we increase the caching space of the distributed caching nodes in DRC-Extra and DFC-Extra. The new caching space of each distributed caching node is calculated as follows.
We calculate the average transmission time (ATT), average energy consumption (AEC) and the number of local requests (LR) that are served by the caching nodes or the distributed caching nodes. These metrics are used to evaluate the effect on reducing the requests to the MESs and the Cloud. The caching space (CS) is adopted for choosing an appropriate caching strategy when the caching space is restricted.
5.2 Numerical Analysis
The DC strategy is utilized as a baseline for numerical analysis. In DC, contents are randomly stored across the MESs and the cached contents remain unchanged during the whole experiment. The numerical analysis results under different parameters are shown in Fig. 3a to Fig. 3o.

Experimental results under different parameters. a to d, \(items= 1000\), \( \theta =0.56 \), \( p_r \in [0.1, 0.9]\). e to h, \( \theta =0.56 \), \( p_r = 0.6 \), \(items \in [100, 1000]\). i to l, \( p_r = 0.6 \), \( items = 1000\) , \( \theta \in [0.1, 2]\). m to p, \(p_r=0.6\), \(\theta =0.56\), \( items = 1000\).
In Fig. 3a to Fig. 3d, items and \( \theta \) are set to 1000 and 0.56 respectively, while \( p_r \) changes from 0.1 to 0.9. The increase of the request probability means fewer nodes leave away and more different contents are cached. As a result, the caching space increases (Seen in Fig. 3c), while the energy consumption decreases (Seen in Fig. 3b). For DFC, DFC-Extra and RC, the copies of local contents increase with the growth of \( p_r \). So the transmission time of them decreases. For DRC and DRC-Extra, since they have to cache the full copy of each content and the caching space is limited, the amount of the content cached locally is small. They have to request new contents from the upper layer frequently, so the transmission time of DRC and DRC-extra remains unchanged. Since the amount of content cached on MESs increases, DRC and DRC-Extra spend less time than DC. Note that the time consumption of DFC-Extra is high when \( p_r \) is equal to 0.1. The low request rate causes a large number of distributed caching nodes to leave, and the requesting nodes have to wait for new distributed caching nodes to recover the cached content. Compared with RC, cached contents are not lost when using distributed caching strategies so that the caching space remains unchanged. Meanwhile, the extra consumption of recovering the cached contents causes higher energy consumption when using distributed caching strategies.
In Fig. 3e to Fig. 3h, \( \theta \) and \( p_r \) are set to 0.56 and 0.6 respectively, while items change from 100 to 1000. When the number of items is 100 (most of the contents are cached locally), the performance of each strategy is optimal, especially DRC and DRC-Extra. It means that the distributed caching strategies perform better with a larger caching space. The increase of items means more different contents can be requested and the content caching update is more frequent, which causes the increase of the transmission time (Seen in Fig. 3e), the energy consumption (Seen in Fig. 3f) and the caching space (Seen in Fig. 3g). Meanwhile, it reduces the number of local requests (Seen in Fig. 3h). The caching space of distributed caching strategies remains unchanged because the number of the distributed servers is fixed and the cached contents are not lost. The caching space of RC fluctuates greatly caused by the leaving caching nodes. DRC and DRC-Extra have to cache several full backups after each successful request, resulting in the highest energy consumption (Seen in Fig. 3f).
In Fig. 3i to Fig. 3l, \( p_r = 0.6 \) and items are set to 0.6 and 1000 respectively, while \( \theta \) changes from 0.1 to 2. The parameter of \( \theta \) determines the popularity of the items. When \( \theta \) is too small or too large, some contents will be requested frequently. The performance of each strategy is optimal when \( \theta \) is equal to 2, where the popularity of the items is high. When \( \theta \) changes from 0.1 to 1, the transmission time increases (Seen in Fig. 3i), wherein the popularity of items are evenly distributed gradually. The cached contents update frequently, resulting in more energy consumption (Seen in Fig. 3j) and fewer local requests (Seen in Fig. 3l). When \( \theta \) is greater than 1, some contents are requested frequently. The transmission time and energy consumption decrease, while the number of local requests increases. The caching space (Seen in Fig. 3k) remains high because other requested contents are still cached.
In Fig. 3m to Fig. 3p, \( p_r\), items and \( \theta \) are set to 0.6, 1000 and 0.56 respectively. We evaluate the performance under different successful requests. As depicted in Fig. 3m, DFC-Extra has the minimum transmission time, and the transmission time of RC and DFC is gradually approaching to each other. In the beginning, the amount of the cached content of RC is small. However, the cached content of RC is enriched gradually and the transmission time decreases, while the transmission time of the distributed caching strategies increases due to the small amount of the cached content and frequent content caching updates. The energy consumption increases slightly (Seen in Fig. 3m) caused by updating and recovering the content. The caching space (Seen in Fig. 3o) of the distributed caching strategies remains unchanged after it reaches the maximum limit, while the caching space of RC still fluctuates. The local requests (Seen in Fig. 3p) of DFC-Extra and RC tend to grow faster due to caching a large number of popular contents.
The findings are summarized as follows. (1) The transmission time and energy consumption of RC, DFC and DFC-Extra are better than other caching strategies in most cases. DFC-Extra performs best, but it needs a large cache space and presents high energy consumption as well. (2) RC performs well in all the scenarios. However, the cached contents are easily lost and the performance degrades if the nodes in the community are not willing to share the contents. (3) All the distributed caching strategies work badly when the nodes leave frequently (e.g., \( p_r = 0.1 \)). However, all of them work well under high request probability and popularity (e.g., \( \theta =2 \)). The distributed caching strategies need more caching space to work better, but they also cause higher energy consumption. DRC and DRC-Extra seem to present the worst performance, but they can keep working when only one distributed caching node provides service. In DFC and DFC-Extra, the nodes have to wait when one of the distributed caching nodes is lost. (4) More importantly, using user devices to cache the content could not only reduce the requests to the Cloud and the MESs, but also decrease the content transmission time as shown in Fig. 3a and Fig. 3d.
6 Conclusions
In this paper, we propose CMU, a three-layer (Cloud-MESs-Users) content caching framework, which could offload the traffic from Cloud-MESs to user devices. We describe the content caching problem and evaluate the performance of different caching strategies under this framework. Numerical results show that content caching with user devices could reduce the requests to Cloud-MESs, as well as decrease the content transmission time. To attract more nodes to participate in content caching and sharing, an incentive mechanism is needed for the distributed caching strategies in the future.
References
Cisco: Cisco visual networking index: global mobile data traffic forecast update, 2017–2022 (2019)
Wang, X., Chen, M., Taleb, T., Ksentini, A., Leung, V.C.M.: Cache in the air: exploiting content caching and delivery techniques for 5G systems. IEEE Commun. Mag. 52(2), 131–139 (2014)
Wang, S., Zhang, X., Zhang, Y., Wang, L., Yang, J., Wang, W.: A survey on mobile edge networks: convergence of computing, caching and communications. IEEE Access 5, 6757–6779 (2017)
Liu, D., Yang, C.: Energy efficiency of downlink networks with caching at base stations. IEEE J. Sel. Areas Commun. 34(4), 907–922 (2016)
Chen, J., Chen, S., Wang, Q., Cao, B., Feng, G., Hu, J.: iRAF: a deep reinforcement learning approach for collaborative mobile edge computing IoT networks. IEEE Internet Things J. 6(4), 7011–7024 (2019)
Jiang, W., Feng, G., Qin, S., Liang, Y.: Learning-based cooperative content caching policy for mobile edge computing. In: 2019 IEEE International Conference on Communications, ICC 2019, Shanghai, China, 20–24 May 2019, pp. 1–6 (2019)
Ale, L., Zhang, N., Wu, H., Chen, D., Han, T.: Online proactive caching in mobile edge computing using bidirectional deep recurrent neural network. IEEE Internet Things J. 6(3), 5520–5530 (2019)
Cui, Q., et al.: Stochastic online learning for mobile edge computing: learning from changes. IEEE Commun. Mag. 57(3), 63–69 (2019)
Liu, M., Yu, F.R., Teng, Y., Leung, V.C.M., Song, M.: Computation offloading and content caching in wireless blockchain networks with mobile edge computing. IEEE Trans. Veh. Technol. 67(11), 11008–11021 (2018)
Zhang, S., He, P., Suto, K., Yang, P., Zhao, L., Shen, X.: Cooperative edge caching in user-centric clustered mobile networks. IEEE Trans. Mob. Comput. 17(8), 1791–1805 (2018)
Yu, D., Ning, L., Zou, Y., Yu, J., Cheng, X., Lau, F.C.M.: Distributed spanner construction with physical interference: constant stretch and linear sparseness. IEEE/ACM Trans. Networking 25(4), 2138–2151 (2017)
Xu, J., Chen, L., Zhou, P.: Joint service caching and task offloading for mobile edge computing in dense networks. In: 2018 IEEE Conference on Computer Communications, INFOCOM 2018, 16–19 April 2018, pp. 207–215 (2018)
Wang, Z., Li, F., Wang, X., Li, T., Hong, T.: A wifi-direct based local communication system. In: 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), June 2018, pp. 1–6 (2018)
Li, F., Wang, X., Wang, Z., Cao, J., Liu, X., et al.: A local communication system over Wi-Fi direct: implementation and performance evaluation. IEEE Internet Things J. (2020). https://doi.org/10.1109/JIOT.2020.2976114
Bai, B., Wang, L., Han, Z., Chen, W., Svensson, T.: Caching based socially-aware D2D communications in wireless content delivery networks: a hypergraph framework. IEEE Wirel. Commun. 23(4), 74–81 (2016)
Wu, D., Liu, Q., Wang, H., Yang, Q., Wang, R.: Cache less for more: exploiting cooperative video caching and delivery in D2D communications. IEEE Trans. Multimedia 21(7), 1788–1798 (2019)
Zhang, W., Wu, D., Yang, W., Cai, Y.: Caching on the move: a user interest-driven caching strategy for D2D content sharing. IEEE Trans. Veh. Technol. 68(3), 2958–2971 (2019)
Paakkonen, J., Barreal, A., Hollanti, C., Tirkkonen, O.: Coded caching clusters with device-to-device communications. IEEE Trans. Mob. Comput. 18(02), 264–275 (2019)
Asheralieva, A., Niyato, D.: Game theory and Lyapunov optimization for cloud-based content delivery networks with device-to-device and UAV–enabled caching. IEEE Trans. Veh. Technol. 68, 10094–10110 (2019)
Li, J., et al.: On social-aware content caching for D2D-enabled cellular networks with matching theory. IEEE Internet Things J. 6(1), 297–310 (2019)
Wang, J., Cheng, M., Yan, Q., Tang, X.: On the placement delivery array design for coded caching scheme in D2D networks. IEEE Trans. Commun., 12 (2017)
Jiang, L., Feng, G., Qin, S.: Cooperative content distribution for 5G systems based on distributed cloud service network. In: 2015 IEEE International Conference on Communication Workshop (ICCW), June 2015, pp. 1125–1130 (2015)
Kai, Y., Wang, J., Zhu, H.: Energy minimization for D2D-assisted mobile edge computing networks. In: ICC 2019–2019 IEEE International Conference on Communications (ICC), May 2019, pp. 1–6 (2019)
Zhang, X., Zhu, Q.: Distributed mobile devices caching over edge computing wireless networks. In: 2017 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), May 2017, pp. 127–132 (2017)
Hayat, O., Ngah, R., Hashim, S., Dahri, M., et al.: Device discovery in D2D communication: a survey. IEEE Access 7, 131114–131134 (2019)
Blasco, P., Gündüz, D.: Learning-based optimization of cache content in a small cell base station. In: 2014 IEEE International Conference on Communications (ICC), June 2014, pp. 1897–1903 (2014)
Acknowledgment
The work is supported by the National Key Research and Development Program of China under Grant Nos. 2018YFB1702000, 2018YFB1800201 and 2019YFB1802600; the National Natural Science Foundation of China under Grant Nos. 61602105, 61702049 and 61872420; the project of PCL Future Greater-Bay Area Network Facilities for Large-scale Experiments and Applications under Grant No. LZC0019; the Guangdong Key Research and Development Program under Grant No. 2019B121204009; the Fundamental Research Funds for the Central Universities under Grant Nos. N2016005, N171604006 and 2019RC03; CERNET Innovation Project under Grant Nos. NGII20170121 and NGII20180101.
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Guo, Z. et al. (2020). CMU: Towards Cooperative Content Caching with User Device in Mobile Edge Networks. In: Ku, WS., Kanemasa, Y., Serhani, M.A., Zhang, LJ. (eds) Web Services – ICWS 2020. ICWS 2020. Lecture Notes in Computer Science(), vol 12406. Springer, Cham. https://doi.org/10.1007/978-3-030-59618-7_14
Download citation
DOI: https://doi.org/10.1007/978-3-030-59618-7_14
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-59617-0
Online ISBN: 978-3-030-59618-7
eBook Packages: Computer ScienceComputer Science (R0)