
Abstract
An interesting observation was made that only a few (far shorter than the prefix) low-frequency tokens are enough to help finding similarity pairs for processing top-k set joins. This phenomenon is ubiquitous in all real datasets we have experimented with, covering domains as varied as text, social network, protein sequence data. Possible explanations are discussed. Based on this observation, we propose an algorithm called AEtop-k for processing both approximate and exact top-k similarity join in a unified framework. Comprehensive experiments demonstrate that, compared with the state-of-the-art algorithm on a large collection of real-life datasets, the approximate version of our algorithm can achieve up to 10000\(\times \) speedup with little sacrifice on accuracy and the exact version runs up to 5\(\times \) faster than the existing algorithm.
The work reported in this paper is partially supported by NSFC under grant number 61370205.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
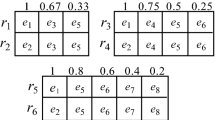
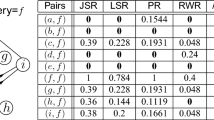

Notes
- 1.
http://dblp.uni-trier.de/db/, a snapshot of the bibliography records from the DBLP web site, contains about 0.9M records (author names + title).
- 2.
http://www.cs.cmu.edu/enron, about 0.25M ENRON emails from about 150 users.
- 3.
http://ftp.acc.umu.se/mirror/wikimedia.org/dumps/, picked from enwiki-*-pages-articles*.xml (title + content).
- 4.
BIBLE is a KJV version bible, and take one verse to one record.
- 5.
PARADISE is from Paradise Lost by the poet John Milton (1608–1674).
- 6.
http://snap.stanford.edu/data, Social circles from Twitter. It take every node as a record and every edge connected by this node as its tokens.
- 7.
https://archive.org/download/stackexchange, Stack Overflow collections.
- 8.
ZIPF is generated by python’s numpy.random.zipf package.
- 9.
- 10.
- 11.
http://www.uniprot.org/downloads, protein sequence datas from the UniProt.
- 12.
A customer’s product views from jd.com’s data-mining contest.
References
Inverted index. Wikipedia. https://en.wikipedia.org/wiki/Inverted_index
Zipf’s law. Wikipedia. https://en.wikipedia.org/wiki/Zipf%27s_law
Angiulli, F., Pizzuti, C.: An approximate algorithm for top-k closest pairs join query in large high dimensional data. Data Knowl. Eng. 53(3), 263–281 (2005)
Bayardo, R.J., Ma, Y., Srikant, R.: Scaling up all pairs similarity search. In: Proceedings of the 16th International Conference on World Wide Web, pp. 131–140 (2007)
Cohen, W.W.: Integration of heterogeneous databases without common domains using queries based on textual similarity. In: Proceedings of the 1998 ACM SIGMOD International Conference on Management of Data, pp. 201–212 (1998)
Das, A.S., Datar, M., Garg, A., Rajaram, S.: Google news personalization: scalable online collaborative filtering. In: Proceedings of the 16th International Conference on World Wide Web, pp. 271–280 (2007)
Henzinger, M.: Finding near-duplicate web pages: a large-scale evaluation of algorithms. In: Proceedings of the 29th Annual International ACM SIGIR conference on Research and Development in Information Retrieval, pp. 284–291 (2006)
Hernández, M.A., Stolfo, S.J.: Real-world data is dirty: data cleansing and the merge/purge problem. Data Mining Knowl. Disc. 2(1), 9–37 (1998)
Kim, Y., Shim, K.: Parallel top-k similarity join algorithms using mapreduce. In: 2012 IEEE 28th International Conference on Data Engineering, pp. 510–521 (2012)
Malkov, Y., Ponomarenko, A., Logvinov, A., Krylov, V.: Approximate nearest neighbor algorithm based on navigable small world graphs. Inf. Syst. 45, 61–68 (2014)
Mann, W., Augsten, N., Bouros, P.: An empirical evaluation of set similarity join techniques. Proc. VLDB Endowment 9(9), 636–647 (2016)
Mann, W., Augsten, N., Jensen, C.S.: Swoop: Top-k similarity joins over set streams. arXiv preprint arXiv:1711.02476 (2017)
Serrano, M.Á., Flammini, A., Menczer, F.: Modeling statistical properties of written text. PLoS ONE 4(4), e5372 (2009)
Spertus, E., Sahami, M., Buyukkokten, O.: Evaluating similarity measures: a large-scale study in the orkut social network. In: Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, pp. 678–684 (2005)
SriUsha, I., Choudary, K.R., Sasikala, T., et al.: Data mining techniques used in the recommendation of e-commerce services. ICECA 2018, 379–382 (2018)
Theobald, M., Weikum, G., Schenkel, R.: Top-k query evaluation with probabilistic guarantees. In: Proceedings of the Thirtieth International Conference on Very Large Data Bases, vol. 30, pp. 648–659 (2004)
Wang, J., Li, G., Feng, J.: Can we beat the prefix filtering? an adaptive framework for similarity join and search. In: Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, pp. 85–96 (2012)
Wang, X., Qin, L., Lin, X., Zhang, Y., Chang, L.: Leveraging set relations in exact set similarity join. In: Proceedings of the VLDB Endowment (2017)
Xiao, C., Wang, W., Lin, X., Shang, H.: Top-k set similarity joins. In: 2009 IEEE 25th International Conference on Data Engineering, pp. 916–927 (2009)
Xiao, C., Wang, W., Lin, X., Yu, J.X., Wang, G.: Efficient similarity joins for near-duplicate detection. ACM Trans. Database Syst. (TODS) 36(3), 1–41 (2011)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Sun, C., Wang, H., Xiao, Y., Liu, Z. (2020). A Unified Framework for Processing Exact and Approximate Top-k Set Similarity Join. In: Wang, X., Zhang, R., Lee, YK., Sun, L., Moon, YS. (eds) Web and Big Data. APWeb-WAIM 2020. Lecture Notes in Computer Science(), vol 12318. Springer, Cham. https://doi.org/10.1007/978-3-030-60290-1_33
Download citation
DOI: https://doi.org/10.1007/978-3-030-60290-1_33
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-60289-5
Online ISBN: 978-3-030-60290-1
eBook Packages: Computer ScienceComputer Science (R0)