
Abstract
To meet the standard of differential privacy, noise is usually added into the original data, which inevitably deteriorates the predicting performance of subsequent learning algorithms. In this chapter, motivated by the success of improving predicting performance by ensemble learning, we propose to enhance privacy-preserving logistic regression by stacking. We show that this can be done either by sample-based or feature-based partitioning. However, we prove that when privacy-budgets are the same, feature-based partitioning requires fewer samples than sample-based one, and thus likely has better empirical performance. As transfer learning is difficult to be integrated with a differential privacy guarantee, we further combine the proposed method with hypothesis transfer learning to address the problem of learning across different organizations. Finally, we not only demonstrate the effectiveness of our method on two benchmark data sets, i.e., MNIST and NEWS20, but also apply it into a real application of cross-organizational diabetes prediction from RUIJIN data set, where privacy is of a significant concern.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Notes
- 1.
—\(q_k\) to partitions.
- 2.
When feature importance is not known,
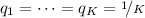 .
.
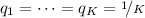 .
.References
Abadi, M., et al.: Deep learning with differential privacy. In: SIGSAC, pp. 308–318. ACM (2016)
Bassily, R., Smith, A., Thakurta, A.: Private empirical risk minimization: efficient algorithms and tight error bounds. In: FOCS, pp. 464–473. IEEE (2014)
Boyd, S., Parikh, N., Chu, E.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 3(1), 1–122 (2011)
Breiman, L.: Bagging predictors. ML 24(2), 123–140 (1996)
Breiman, L.: Stacked regressions. ML 24(1), 49–64 (1996)
Chaudhuri, K., Monteleoni, C., Sarwate, A.: Differentially private empirical risk minimization. JMLR 12, 1069–1109 (2011)
Dwork, C., McSherry, F., Nissim, K., Smith, A.: Calibrating noise to sensitivity in private data analysis. In: Halevi, S., Rabin, T. (eds.) TCC 2006. LNCS, vol. 3876, pp. 265–284. Springer, Heidelberg (2006). https://doi.org/10.1007/11681878_14
Dwork, C., Roth, A.: The algorithmic foundations of differential privacy. Found. Trends® Mach. Learn. 9(3–4), 211–407 (2014)
Džeroski, S., Ženko, B.: Is combining classifiers with stacking better than selecting the best one? ML 54(3), 255–273 (2004)
Emekçi, F., Sahin, O., Agrawal, D., El Abbadi, A.: Privacy preserving decision tree learning over multiple parties. TKDE 63(2), 348–361 (2007)
Fong, P., Weber-Jahnke, J.: Privacy preserving decision tree learning using unrealized data sets. TKDE 24(2), 353–364 (2012)
Friedman, J., Hastie, T., Tibshirani, R.: Additive logistic regression: a statistical view of boosting. Ann. Stat. 28(2), 337–407 (2000)
Hastie, T., Tibshirani, R., Friedman, J.: The Elements of Statistical Learning. SSS. Springer, New York (2009). https://doi.org/10.1007/978-0-387-84858-7
Hamm, J., Cao, Y., Belkin, M.: Learning privately from multiparty data. In: ICML. pp. ,555–563 (2016)
Hanley, J., McNeil, B.: A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology 148(3), 839–843 (1983)
Kasiviswanathan, P., Jin, H.: Efficient private empirical risk minimization for high-dimensional learning. In: ICML, pp. 488–497 (2016)
Kuzborskij, I., Orabona, F.: Stability and hypothesis transfer learning. In: ICML, pp. 942–950 (2013)
Lang, K.: NewsWeeder: learning to filter netnews. In: ICML. Citeseer (1995)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
Ozay, M., Vural, F.: A new fuzzy stacked generalization technique and analysis of its performance. Technical report. arXiv:1204.0171 (2012)
Pan, J., Yang, Q.: A survey on transfer learning. TKDE 22(10), 1345–1359 (2010)
Papernot, N., Abadi, M., Erlingsson, U., Goodfellow, I., Talwar, K.: Semi-supervised knowledge transfer for deep learning from private training data. In: ICLR (2017)
Pathak, M., Rane, S., Raj, B.: Multiparty differential privacy via aggregation of locally trained classifiers. In: NIPS, pp. 1876–1884 (2010)
Rajkumar, A., Agarwal, S.: A differentially private stochastic gradient descent algorithm for multiparty classification. In: AISTAT, pp. 933–941 (2012)
Shokri, R., Shmatikov, V.: Privacy-preserving deep learning. In: SIGSAC, pp. 1310–1321 (2015)
Smyth, P., Wolpert, D.: Linearly combining density estimators via stacking. ML 36(1–2), 59–83 (1999)
Ting, K., Witten, I.: Issues in stacked generalization. JAIR 10, 271–289 (1999)
Wang, Y., Gu, Q., Brown, D.: Differentially private hypothesis transfer learning. In: ECML (2018)
Wolpert, D.: Stacked generalization. Neural Netw. 5(2), 241–259 (1992)
Xie, L., Baytas, I., Lin, K., Zhou, J.: Privacy-preserving distributed multi-task learning with asynchronous updates. In: SIGKDD, pp. 1195–1204 (2017)
Zhou, Z.H.: Ensemble Methods: Foundations and Algorithms. Chapman and Hall/CRC, New York (2012)
Acknowledgments
We acknowledge the support of Hong Kong CERG-16209715. The first author also thanks Bo Han from Riken for helpful suggestions.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Guo, X. et al. (2020). Privacy-Preserving Stacking with Application to Cross-organizational Diabetes Prediction. In: Yang, Q., Fan, L., Yu, H. (eds) Federated Learning. Lecture Notes in Computer Science(), vol 12500. Springer, Cham. https://doi.org/10.1007/978-3-030-63076-8_19
Download citation
DOI: https://doi.org/10.1007/978-3-030-63076-8_19
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-63075-1
Online ISBN: 978-3-030-63076-8
eBook Packages: Computer ScienceComputer Science (R0)