
Abstract
In this paper, we show how to significantly improve algebraic techniques for solving the MinRank problem, which is ubiquitous in multivariate and rank metric code based cryptography. In the case of the structured MinRank instances arising in the latter, we build upon a recent breakthrough [11] showing that algebraic attacks outperform the combinatorial ones that were considered state of the art up until now. Through a slight modification of this approach, we completely avoid Gröbner bases computations for certain parameters and are left only with solving linear systems. This does not only substantially improve the complexity, but also gives a convincing argument as to why algebraic techniques work in this case. When used against the second round NIST-PQC candidates ROLLO-I-128/192/256, our new attack has bit complexity respectively 71, 87, and 151, to be compared to 117, 144, and 197 as obtained in [11]. The linear systems arise from the nullity of the maximal minors of a certain matrix associated to the algebraic modeling. We also use a similar approach to improve the algebraic MinRank solvers for the usual MinRank problem. When applied against the second round NIST-PQC candidates GeMSS and Rainbow, our attack has a complexity that is very close to or even slightly better than those of the best known attacks so far. Note that these latter attacks did not rely on MinRank techniques since the MinRank approach used to give complexities that were far away from classical security levels.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others
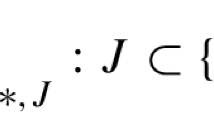


Keywords
1 Introduction
Rank Metric Code-Based Cryptography. In the last decade, rank metric code-based cryptography has proved to be a powerful alternative to traditional code-based cryptography based on the Hamming metric. This thread of research started with the GPT cryptosystem [22] based on Gabidulin codes [21], which are rank metric analogues of Reed-Solomon codes. However, the strong algebraic structure of those codes was successfully exploited for attacking the original GPT cryptosystem and its variants with the Overbeck attack [34] (see [32] for the latest developments). This is similar to the Hamming metric situation where essentially all McEliece cryptosystems based on Reed-Solomon codes or variants of them have been broken. However, recently a rank metric analogue of the NTRU cryptosystem [28] has been designed and studied, starting with the pioneering paper [23]. NTRU relies on a lattice with vectors of rather small Euclidean norm. It is precisely those vectors that allow an efficient decoding/deciphering process. The decryption of the cryptosystem proposed in [23] relies on LRPC codes with rather short vectors in the dual code, but this time for the rank metric. This cryptosystem can also be viewed as the rank metric analogue of the MDPC cryptosystem [31] relying on short dual code vectors for the Hamming metric.
This new way of building rank metric code-based cryptosystems has led to a sequence of proposals [5, 6, 23, 25], culminating in submissions to the NIST post-quantum competition [2, 3], whose security relies solely on decoding codes in rank metric with a ring structure similar to those used in lattice-based cryptography. Interestingly enough, one can also build signature schemes using the rank metric; even though early attempts which relied on masking the structure of a code [9, 26] have been broken [16], a promising recent approach [8] only considers random matrices without structural masking.
Decoding \(\mathbb {F}_{q^m}\)-Linear Codes in Rank Metric. In other words, in rank metric code-based cryptography we are now only left with assessing the difficulty of the decoding problem in rank metric. The trend there is to consider linear codes of length n over an extension \(\mathbb {F}_{q^m}\) of degree m of \(\mathbb {F}_{q}\), i.e., \(\mathbb {F}_{q^m}\)-linear subspaces of \(\mathbb {F}_{q^m}^n\). Let \((\beta _1,\dots ,\beta _m)\) be any basis of \(\mathbb {F}_{q^m}\) as a \(\mathbb {F}_{q}\)-vector space. Then words of those codes can be interpreted as matrices with entries in the ground field \(\mathbb {F}_{q}\) by viewing a vector \(\varvec{x}=(x_1,\dots ,x_n) \in \mathbb {F}_{q^m}^n\) as a matrix \(Mat(\varvec{x}) = (X_{ij})_{i,j}\) in \(\mathbb {F}_{q}^{m \times n}\), where \((X_{ij})_{1 \le i \le m}\) is the column vector formed by the coordinates of \(x_j\) in \((\beta _1,\dots ,\beta _m)\), i.e., \(x_j = \beta _1X_{1j} + \cdots + \beta _mX_{mj}\). Then the “rank” metric d on \(\mathbb {F}_{q^m}^n\) is the rank metric on the associated matrix space, namely
Hereafter, we will use the following terminology.
Problem 1
((m, n, k, r)-decoding problem).
Input: an \(\mathbb {F}_{q^m}\)-basis \((\varvec{c}_1,\dots ,\varvec{c}_k)\) of a subspace \({\mathcal {C}}\) of \(\mathbb {F}_{q^m}^n\), an integer \(r \in \mathbb {N}\), and a vector \(\varvec{y}\in \mathbb {F}_{q^m}^n\) such that \(\left| \varvec{y}-\varvec{c} \right| _{\textsc {rank}} \le r\) for some \(\varvec{c}\in {\mathcal {C}}\).
Output: \(\varvec{c}\in {\mathcal {C}}\) and \(\varvec{e}\in \mathbb {F}_{q^m}^n\) such that \(\varvec{y}=\varvec{c}+\varvec{e}\) and \(\left| \varvec{e} \right| _{\textsc {rank}} \le r\).
This problem is known as the Rank Decoding problem, written RD. It is equivalent to the Rank Syndrome Decoding problem, for which one uses the parity check matrix of the code. There are two approaches to solve RD instances: the combinatorial ones such as [10, 24] and the algebraic ones. For some time it was thought that the combinatorial approach was the most threatening attack on such schemes especially when q is small, until [11] showed that even for \(q=2\) the algebraic attacks outperform the combinatorial ones. If the conjecture made in [11] holds, the complexity of solving by algebraic attacks the decoding problem is of order \(2^{O(r \log n)}\) with a constant depending on the code rate \(R=k/n\).
Even if the decoding problem is not known to be NP-complete for these \(\mathbb {F}_{q^m}\)-linear codes, there is a randomized reduction to an NP-complete problem [27] (namely to decoding in the Hamming metric). The region of parameters which is of interest for the NIST submissions corresponds to \(m = \varTheta \left( n \right) \), \(k=\varTheta \left( n \right) \) and \(r = \varTheta \left( \sqrt{n} \right) \).
The MinRank Problem. The MinRank problem was first mentioned in [13] where its NP-completeness was also proven. We will consider here the homogeneous version of this problem which corresponds to
Problem 2
(MinRank problem).
Input: an integer \(r \in \mathbb {N}\) and K matrices \(\varvec{M}_1,\dots ,\varvec{M}_K \in \mathbb {F}_{q}^{m \times n}\).
Output: field elements \(x_1,x_2,\dots ,x_K \in \mathbb {F}_{q}\) that are not all zero such that
It plays a central role in public key cryptography. Many multivariate schemes are either directly based on the hardness of this problem [15] or strongly related to it as in [35,36,37] and the NIST post-quantum competition candidates Gui [17], GeMSS [14] or Rainbow [18]. It first appeared in this context as part of Kipnis-Shamir’s attack [29] against the HFE cryptosystem [35]. It is also central in rank metric code-based cryptography, because the RD problem reduces to MinRank as explained in [19] and actually the best algorithms for solving this problem are really MinRank solvers taking advantage of the \(\mathbb {F}_{q^m}\) underlying structure as in [11]. However the parameter region generally differs. When the RD problem arising from rank metric schemes is treated as a MinRank problem we generally have \(K=\varTheta \left( n^2 \right) \) and r is rather small \(r = \varTheta \left( \sqrt{n} \right) \)) whereas for the multivariate cryptosystems \(K = \varTheta \left( n \right) \) but r is much bigger.
The current best known algorithms for solving the MinRank problem have exponential complexity. Many of them are obtained by an algebraic approach too consisting in modeling the MinRank problem by an algebraic system and solving it with Gröbner basis techniques. The main modelings are the Kipnis-Shamir modeling [29] and the minors modeling [20]. The complexity of solving MinRank using these modelings has been investigated in [19, 20, 38]. In particular [38] shows that the bilinear Kipnis-Shamir modeling behaves much better than generic bilinear systems with respect to Gröbner basis techniques.
Our Contribution. Here we follow on from the approach in [11] and propose a slightly different modeling to solve the RD problem. Roughly speaking the algebraic approach in [11] is to set up a bilinear system satisfied by the error we are looking for. This system is formed by two kinds of variables, the “coefficient” variables and the “support” variables. It is implicitly the modeling considered in [33]. The breakthrough obtained in [11] was to realize that
-
the coefficient variables have to satisfy “maximal minor” equations: the maximal minors of a certain \(r \times (n-k-1)\) matrix (i.e. the \(r \times r\) minors) with entries being linear forms in the coefficient variables have to be equal to 0.
-
these maximal minors are themselves linear combinations of maximal minors \(c_T\) of an \(r \times n\) matrix \(\varvec{C}\) whose entries are the coefficient variables.
This gives a linear system in the \(c_T\)’s provided there are enough linear equations. Moreover the original bilinear system has many solutions and there is some freedom in choosing the coefficient variables and the support variables. With the choice made in [11] the information we obtain about the \(c_T\)’s is not enough to recover the coefficient variables directly. In this case the last step of the algebraic attack still has to compute a Gröbner basis for the algebraic system consisting of the original system plus the information we have on the \(c_T\)’s.
Our new approach starts by noticing that there is a better way to use the freedom on the coefficient variables and the support variables: we can actually specify so many coefficient variables that all those that remain unknown are essentially equal to some maximal minor \(c_T\) of \(\varvec{C}\). With this we avoid the Gröbner basis computation: we obtain from the knowledge of the \(c_T\)’s the coefficient variables and plugging in theses values in the original bilinear system we are left with solving a linear system in the support variables. This new approach gives a substantial speed-up in the computations for solving the system. It results in the best practical efficiency and complexity bounds that are currently known for the decoding problem; in particular, it significantly improves upon [11]. We present attacks for ROLLO-I-128, ROLLO-I-192, and ROLLO-I-256 with bit complexity respectively in 70, 86, and 158, to be compared to 117, 144, and 197 obtained in [11]. The difference with [11] is significant since as there is no real quantum speed-up for solving linear systems, the best quantum attacks for ROLLO-I-192 remained the quantum attack based on combinatorial attacks, when our new attacks show that ROLLO parameters are broken and need to be changed.
Our analysis is divided into two categories: the “overdetermined” and the “underdetermined” case. An (m, n, k, r)-decoding instance is overdetermined if
This really corresponds to the case where we have enough linear equations by our approach to find all the \(c_T\)’s (and hence all the coefficient variables). In that case we obtain a complexity in
operations in the field \(\mathbb {F}_{q}\), where \(\omega \) is the constant of linear algebra and \(p = \max \{i : i\in \{1..n\}, m\left( {\begin{array}{c}n-i-k-1\\ r\end{array}}\right) \ge \left( {\begin{array}{c}n-i\\ r\end{array}}\right) -1\}\) represents, in case the overdetermined condition (1) is comfortably fulfilled, the use of punctured codes. This complexity clearly supersedes the previous results of [11] in terms of complexity and also by the fact that it does not require generic Gröbner Basis algorithms. In a rough way for \(r = \mathcal {O}\left( \sqrt{n}\right) \) (the type of parameters used for ROLLO and RQC), the recent improvements on algebraic attacks can be seen as this: before [11] the complexity for solving RD involved a term in \(\mathcal {O}(n^2)\) in the upper part of a binomial coefficient, the modeling in [11] replaced it by a term in \(\mathcal {O}\left( n^{\frac{3}{2}}\right) \) whereas our new modeling involves a term in \(\mathcal {O}(n)\) at a similar position. This leads to a gain in the exponential coefficient of order 30% compared to [11] and of order 50% compared to approaches before [11]. Notice that for ROLLO and RQC only parameters with announced complexities 128 and 192 bits satisfied condition (1) but not parameters with announced complexities 256 bits.
When condition (1) is not fulfilled, the instance can either be underdetermined or be brought back to the overdetermined area by an hybrid approach using exhaustive search with exponential complexity to guess few variables in the system. In the underdetermined case, our approach is different from [11]. Here we propose an approach using reduction to the MinRank problem and a new way to solve it. Roughly speaking we start with a quadratic modeling of MinRank that we call “support minors modeling” which is bilinear in the aforementioned coefficient and support variables and linear in the so called “linear variables”. The last ones are precisely the \(x_i\)’s that appear in the MinRank problem. Recall that the coefficient variables are the entries of a \(r \times n\) matrix \(\varvec{C}\). The crucial observation is now that for all positive integer b all maximal minors of any \((r+b)\times n\) matrix obtained by adding to \(\varvec{C}\) any b rows of \(\sum _i x_i \varvec{M}_i\) are equal to 0. These minors are themselves linear combinations of terms of the form \(m c_T\) where \(c_T\) is a maximal minor of \(\varvec{C}\) and m a monomial of degree b in the \(x_i\)’s. We can predict the number of independent linear equations in the \(m c_T\)’s we obtain this way and when the number of such equations is bigger than the number of \(m c_T\)’s we can recover their values and solve the MinRank problem by linearization. This new approach is not only effective in the underdetermined case of the RD problem it can also be quite effective for some multivariate proposals made to the NIST competition. In the case of the RD problem, it improves the attacks on [7] made in [11] for the parameter sets with the largest values of r (corresponding to parameters claiming 256 bits of security). The multivariate schemes that are affected by this new attack are for instance GeMSS and Rainbow. On GeMSS it shows MinRank attacks together with this new way of solving MinRank come close to the best known attacks against this scheme. On Rainbow it outperforms slightly the best known attacks for certain high security parameter sets.
At last, not only do these two new ways of solving algebraically the RD or MinRank problem outperform previous algebraic approaches in certain parameter regimes, they are also much better understood: we do not rely on heuristics based on the first degree fall as in [11, 38] to analyze its complexity, but it really amounts to solve a linear system and understand the number of independent linear equations that we obtain which is something for which we have been able to give accurate formulas predicting the behavior we obtain experimentally.
2 Notation
In what follows, we use the following notation and definitions:
-
Matrices and vectors are written in boldface font \(\varvec{M}\).
-
The transpose of a matrix \(\varvec{M}\) is denoted by \(\varvec{M}^\intercal \).
-
For a given ring \(\mathcal {R}\), the set of matrices with n rows, m columns and coefficients in \(\mathcal {R}\) is denoted by \(\mathcal {R}^{n\times m}\).
-
\(\{1..n\}\) stands for the set of integers from 1 to n.
-
For a subset \(I \subset \{1..n\}\), \(\#{I}\) stands for the number of elements in I.
-
For two subsets \(I\subset \{1..n\}\) and \(J\subset \{1..m\}\), we write \(\varvec{M}_{I,J}\) for the submatrix of \(\varvec{M}\) formed by its rows (resp. columns) with index in I (resp. J).
-
For an \(m \times n\) matrix \(\varvec{M}\) we use the shorthand notation \(\varvec{M}_{*,J} = \varvec{M}_{\{1..m\},J}\) and \(\varvec{M}_{i,j}\) for the entry in row i and column j.
-
\(\left| \varvec{M} \right| _{}\) is the determinant of a matrix \(\varvec{M}\), \(\left| \varvec{M} \right| _{I,J}\) is the determinant of the submatrix \(\varvec{M}_{I,J}\) and \(\left| \varvec{M} \right| _{*,J}\) is the determinant of \(\varvec{M}_{*,J}\).
-
\(\alpha \in \mathbb {F}_{q^m}\) is a primitive element, that is to say that \((1,\alpha ,\dots ,\alpha ^{m-1})\) is a basis of \(\mathbb {F}_{q^m}\) seen as an \(\mathbb {F}_{q}\)-vector space.
-
For \(\mathbf {v}=(v_1,\ldots ,v_n) \in \mathbb {F}_{q^m}^n\), the support of \(\mathbf {v}\) is the \(\mathbb {F}_{q}\)-vector subspace of \(\mathbb {F}_{q^m}\) spanned by the vectors \(v_1,\ldots ,v_n\). Thus this support is the column space of the matrix \(Mat(\mathbf {v})\) associated to \(\mathbf {v}\) (for any choice of basis), and its dimension is precisely \(\text {Rank}\mathchoice{\left( Mat(\mathbf {v})\right) }{(Mat(\mathbf {v}))}{(Mat(\mathbf {v}))}{(Mat(\mathbf {v}))}\).
-
An [n, k] \(\mathbb {F}_{q^m}\)-linear code is an \(\mathbb {F}_{q^m}\)-linear subspace of \(\mathbb {F}_{q^m}^n\) of dimension k.
3 Algebraic Modeling of the MinRank and the Decoding Problem
3.1 Modeling of MinRank
The modeling for MinRank we consider here is related to the modeling used for decoding in the rank metric in [11]. The starting point is that, in order to solve Problem 2, we look for a nonzero solution \((\varvec{S},\varvec{C},\varvec{x}) \in \mathbb {F}_{q}^{m\times r}\times \mathbb {F}_{q}^{r\times n}\times \mathbb {F}_{q}^{K}\) of
\(\varvec{S}\) is an unknown matrix whose columns give a basis for the column space of the matrix \(\sum _{i=1}^{K} x_i \varvec{M}_i\) of rank \(\le r\) we are looking for. The j-th column of \(\varvec{C}\) represents the coordinates of the j-th column of the aforementioned matrix in this basis. We call the entries of \(\varvec{S}\) the support variables, and the entries of \(\varvec{C}\) the coefficient variables. Note that in the above equation, the variables \(x_i\) only occur linearly. As such, we will dub them the linear variables.
Let \(\varvec{r}_j\) be the j-th row of \(\sum _{i=1}^{K} x_i \varvec{M}_i\). (3) implies that each row \(\varvec{r}_j\) is in the rowspace of \(\varvec{C}\) (or in coding theoretic terms \(\varvec{r}_j\) should belong to the code \({\mathcal {C}}:=\{\varvec{u}\varvec{C}, \varvec{u}\in \mathbb {F}_{q}^r\}\). The following \((r+1)\times n\) matrix \(\varvec{C}'_j\) is therefore of rank \(\le r\):
Therefore, all the maximal minors of this matrix are equal to 0. These maximal minors can be expressed via cofactor expansion with respect to their first row. In this way, they can be seen as bilinear forms in the \(x_i\)’s and the \(r\times r\) minors of \(\varvec{C}\). These minors play a fundamental role in the whole paper and we use the following notation for them.
Notation 1
Let \(T \subset \{1..n\}\) with \(\#{T}=r\). Let \(c_T\) be the maximal minor of \(\varvec{C}\) corresponding to the columns of \(\varvec{C}\) that belong to T, i.e.
These considerations lead to the following algebraic modeling.
Modelling 1
(Support Minors modeling). We consider the system of bilinear equations, given by canceling the maximal minors of the m matrices \(\varvec{C}_j'\):
This system contains:
-
\(m \left( {\begin{array}{c}n\\ r+1\end{array}}\right) \) bilinear equations with coefficients in \(\mathbb {F}_{q}\),
-
\(K+\left( {\begin{array}{c}n\\ r\end{array}}\right) \) unknowns: \(\varvec{x}=(x_1,\cdots ,x_{K})\) and the \(c_T\)’s, \(T \subset \{1..n\}\) with \(\#{T}=r\).
We search for the solutions \(x_i, c_T\)’s in \(\mathbb {F}_{q}\).
Remark 1
-
1.
One of the point of having the \(c_T\) as unknowns instead of the coefficients \(C_{ij}\) of \(\varvec{C}\) is that, if we solve (4) in the \(x_i\) and the \(C_{ij}\) variables, then there are many solutions to (4) since when \((\varvec{x},\varvec{C})\) is a solution for it, then \((\varvec{x},\varvec{A}\varvec{C})\) is also a solution for any invertible matrix \(\varvec{A}\) in \(\mathbb {F}_{q}^{r \times r}\). With the \(c_T\) variables we only expect a space of dimension 1 for the \(c_T\) corresponding to the transformation \(c_T \mapsto \left| \varvec{A} \right| _{} c_T\) that maps a given solution of (4) to a new one.
-
2.
Another benefit brought by replacing the \(C_{ij}\) variables by the \(c_T\)’s is that it decreases significantly the number of possible monomials for writing the algebraic system (4) (about r! times less). This allows for solving this system by linearization when the number of equations of the previous modeling exceeds the number of different \(x_ic_T\) monomials minus 1, namely when
$$\begin{aligned} m\left( {\begin{array}{c}n\\ r+1\end{array}}\right) \ge K\left( {\begin{array}{c}n\\ r\end{array}}\right) -1. \end{aligned}$$(5)This turns out to be “almost” the case for several multivariate cryptosystem proposals based on the MinRank problem where K is generally of the same order as m and n.
3.2 The Approach Followed in [11] to Solve the Decoding Problem
In what follows, we consider the (m, n, k, r)-decoding problem for a code \({\mathcal {C}}\) of length n, dimension k over \(\mathbb {F}_{q^m}\) with a \(\varvec{y}\in \mathbb {F}_{q^m}^n\) at distance r from \({\mathcal {C}}\) and look for \(\varvec{c}\in {\mathcal {C}}\) and \(\varvec{e}\) such that \(\varvec{y}= \varvec{c}+ \varvec{e}\) and \(|\varvec{e}|=r\). We assume that there is a unique solution to this problem (which is relevant for our cryptographic schemes). The starting point is the Ourivksi-Johansson approach, consisting in considering the linear code \(\widetilde{C}= \mathcal {C} + \langle \varvec{y}\rangle \). From now on, let \(\widetilde{G}=(\varvec{I}_{k+1} \ \varvec{R})\) (respectively \(\widetilde{H}=(-\varvec{R}^\intercal \ \varvec{I}_{n-k-1})\)) be the generator matrix in systematic form (respectively a parity-check matrix) of the extended code \(\widetilde{C}\). By construction, \(\varvec{e}\) belongs to \(\widetilde{C}\) as well as all its multiples \(\lambda \varvec{e}\), \(\lambda \in \mathbb {F}_{q^m}\). Looking for non-zero codewords in \(\widetilde{C}\) of rank weight r has at least \(q^m-1\) different solutions, namely all the \(\lambda \varvec{e}\) for \(\lambda \in \mathbb {F}_{q^m}^\times \).
It is readily seen that finding such codewords can be done by solving the (homogeneous) MinRank problem with \(\varvec{M}_{ij} :=Mat(\alpha ^{i-1} \varvec{c}_j)\) (we adopt a bivariate indexing of the \(\varvec{M}_i\)’s which is more convenient here), for \((ij) \in \{1..m\}\times \{1..k+1\}\) and where \(\varvec{c}_1,\cdots ,\varvec{c}_{k+1}\) is an \(\mathbb {F}_{q^m}\)-basis of \(\widetilde{C}\). This is because the \(\alpha ^{i-1} \varvec{c}_j\)’s form an \(\mathbb {F}_{q}\)-basis of \(\widetilde{C}\). However, the problem with this approach is that \(K=(k+1)m=\varTheta \left( n^2 \right) \) for the parameters relevant to cryptography. This is much more than for the multivariate cryptosystems based on MinRank and (5) is far from being satisfied here. However, as observed in [11], it turns out in this particular case, it is possible because of the \(\mathbb {F}_{q^m}\) linear structure of the code, to give an algebraic modeling that only involves the entries of \(\varvec{C}\). It is obtained by introducing a parity-check matrix for \(\widetilde{C}\), that is a matrix \(\varvec{H}\) whose kernel is \(\widetilde{C}\):
In our \(\mathbb {F}_{q^m}\) linear setting the solution \(\varvec{e}\) we are looking for can be written as
where \(\varvec{S}\in \mathbb {F}_{q}^{m \times r}\) and \(\varvec{C}\in \mathbb {F}_{q}^{r \times n}\) play the same role as in the previous subsection: \(\varvec{S}\) represents a basis of the support of \(\varvec{e}\) in \(\left( \mathbb {F}_{q}^m\right) ^r\) and \(\varvec{C}\) the coordinates of \(\varvec{e}\) in this basis. By writing that \(\varvec{e}\) should belong to \(\widetilde{C}\) we obtain that
This gives an algebraic system using only the coefficient variables as shown by
Proposition 1
([11], Theorem 2). The maximal minors of the \(r \times (n-k-1)\) matrix \(\varvec{C}\varvec{H}^\intercal \) are all equal to 0.
Proof
Consider the following vector in \(\mathbb {F}_{q}^r\): \(\varvec{e}' :=\begin{pmatrix} 1&\alpha&\dots&\alpha ^{m-1} \end{pmatrix} \varvec{S}\) whose entries generate (over \(\mathbb {F}_{q}\)) the subspace generated by the entries of \(\varvec{e}\) (i.e. its support). Substituting \(\begin{pmatrix} 1&\alpha&\dots&\alpha ^{m-1}\end{pmatrix} \varvec{S}\) for \(\varvec{e}'\) in (7) yields \( \varvec{e}' \varvec{C}\varvec{H}^\intercal =\varvec{0}_{n-k-1}. \) This shows that the \(r \times n\) matrix \(\varvec{C}\varvec{H}^\intercal \) is of rank \(\le r-1\). \(\square \)
These minors \(\varvec{C}\varvec{H}^\intercal \) are polynomials in the entries of \(\varvec{C}\) with coefficients in \(\mathbb {F}_{q^m}\). Since these entries belong to \(\mathbb {F}_{q}\), the nullity of each minor gives m algebraic equations corresponding to polynomials with coefficients in \(\mathbb {F}_{q}\). This involves the following operation.
Notation 2
Let \({\mathcal {S}} :=\{\sum _{j} a_{ij} m_{ij}=0,1 \le i \le N\}\) be a set of polynomial equations where the \(m_{ij}\)’s are the monomials in the unknowns that are assumed to belong to \(\mathbb {F}_{q}\), whereas the \(a_{ij}\)’s are known coefficients that belong to \(\mathbb {F}_{q^m}\). We define the \(a_{ijk}\)’s as \(a_{ij} =\sum _{k=0}^{m-1} a_{ijk} \alpha ^k\), where the \(a_{ijk}\)’s belong to \(\mathbb {F}_{q}\). From this we can define the system “unfolding” over \(\mathbb {F}_{q}\) as
The important point is that the solutions of \(\mathcal {S}\) over \(\mathbb {F}_{q}\) are exactly the solutions of \(\mathbf{UnFold}{(\mathcal {S})}\) over \(\mathbb {F}_{q}\), so that in that sense the two systems are equivalent.
By using the Cauchy-Binet formula, it is proved [11, Prop. 1] that the maximal minors of \(\varvec{C}\varvec{H}^\intercal \), which are polynomials of degree \(\le r\) in the coefficient variables \(C_{ij}\), can actually be expressed as linear combinations of the \(c_T\)’s. In other words we obtain \(m \left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \) linear equations over \(\mathbb {F}_{q}\) by “unfolding” the \(\left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \) maximal minors of \(\varvec{C}\varvec{H}^\intercal \). We denote such a system by
It is straightforward to check that some variables in \(\varvec{C}\) and \(\varvec{S}\) can be specialized. The choice which is made in [11] is to specialize \(\varvec{S}\) with its r first rows equal to the identity (\(\varvec{S}_{\{1..r\},*}=\varvec{I}_r\)), its first column to \(\mathbf {1}^\intercal = (1,0,\dots ,0)^\intercal \) and \(\varvec{C}\) has its first column equal to \(\mathbf {1}^\intercal \). It is proved in [11, Section 3.3] that if the first coordinate of \(\varvec{e}\) is nonzero and the top \(r\times r\) block of \(\varvec{S}\) is invertible, then the previous specialized system has a unique solution. Moreover, this will always be the case up to a permutation of the coordinates of the codewords or a change of \(\mathbb {F}_{q^m}\)-basis.
It is proved in [11, Prop. 2] that a degree-r Gröbner basis of the unfolded polynomials \(\mathbf{MaxMinors}\) is obtained by solving the corresponding linear system in the \(c_T\)’s. However, this strategy of specialization does not reveal the entries of \(\varvec{C}\) (it only reveals the values of the \(c_T\)’s). To finish the calculation it still remains to compute a Gröbner basis of the whole algebraic system as done in [11, Step 5, §6.1]). There is a simple way to avoid this computation by specializing the variables of \(\varvec{C}\) in a different way. This is the new approach we explain now.
3.3 The New Approach : Specializing the Identity in C
As in the previous approach we note that if \((\varvec{S},\varvec{C})\) is a solution of (7) then \((\varvec{S}\varvec{A}^{-1},\varvec{A}\varvec{C})\) is also a solution of it for any invertible matrix \(\varvec{A}\) in \(\mathbb {F}_{q}^{r \times r}\). Now, when the first r columns of a solution \(\varvec{C}\) form a invertible matrix, we will still have a solution with the specialization
We can also specialize the first column of \(\varvec{S}\) to \(\mathbf {1}^\intercal = \begin{pmatrix} 1&0&\dots&0 \end{pmatrix} ^\intercal \). If the first r columns of \(\varvec{C}\) are not independent, it suffices as in [11, Algo. 1] to make several different attempts of choosing r columns. The point of this specialization is that
-
the corresponding \(c_T\)’s are equal to the entries \(C_{ij}\) of \(\varvec{C}\) up to an unessential factor \((-1)^{r+i}\) whenever \(T=\{1..r\} \backslash \{i\}\cup \{j\}\) for any \(i\in \{1..r\}\) and \(j\in \{r+1..n\}\). This follows on the spot by writing the cofactor expansion of the minor \(c_T = \left| \varvec{C} \right| _{*,\{1..r\}\backslash \{i\}\cup \{j\}}\). Solving the linear system in the \(c_T\)’s corresponding to (8) yields now directly the coefficient variables \(C_{ij}\). This avoids the subsequent Gröbner basis computation, since once we have \(\varvec{C}\) we obtain \(\varvec{S}\) directly by solving (7) which has become a linear system.
-
it is readily shown that any solution of (8) is actually a projection on the \(C_{ij}\) variables of a solution \((\varvec{S},\varvec{C})\) of the whole system (see Proposition 3). This justifies the whole approach.
In other words we are interested here in the following modeling
Modelling 2
We consider the system of linear equations, given by unfolding all maximal minors of \( \begin{pmatrix} \varvec{I}_r&\varvec{C}' \end{pmatrix}\varvec{H}^\intercal \):
This system contains:
-
\(m\left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \) linear equations with coefficients in \(\mathbb {F}_{q}\),
-
\(\left( {\begin{array}{c}n\\ r\end{array}}\right) -1\) unknowns: the \(c_T\)’s, \(T \subset \{1..n\}\) with \(\#{T}=r\), \(T \ne \{1..r\}\).
We search for the solutions \(c_T\)’s in \(\mathbb {F}_{q}\).
Note that from the specialization, \(c_{\{1..r\}}=1\) is not an unknown. For the reader’s convenience, let us recall the specific form of these equations which is obtained by unfolding the following polynomials (see [11, Prop. 2] and its proof).
Proposition 2
\(\mathbf{MaxMinors}(\varvec{C}\varvec{H}^\intercal )\) contains \(\left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \) polynomials of degree r over \(\mathbb {F}_{q^m}\), indexed by the subsets \(J\subset \{1..n-k-1\}\) of size r, that are the
where the sum is over all subsets \(T_1\subset \{1..k+1\}\) and \(T_2\) subset of J, with \(\#{T_1}+\#{T_2} = r\), and \(\sigma _{J}{(T_2)}\) is an integer depending on \(T_2\) and J. We denote by \({T_2}+k+1\) the set \(\{i+k+1 : i \in T_2\}\).
Let us show now that the solutions of this linear system are projections of the solutions of the original system. For this purpose, let us bring in
-
The original system (7) over \(\mathbb {F}_{q^m}\) obtained with the aforementioned specialization
$$\begin{aligned} \mathcal {F}_C= & {} \left\{ \begin{pmatrix} 1&\alpha&\cdots&\alpha ^{m-1} \end{pmatrix} \begin{pmatrix} \mathbf {1}^\intercal&\varvec{S}' \end{pmatrix} \begin{pmatrix} \varvec{I}_r&\varvec{C}' \end{pmatrix}\varvec{H}^\intercal =\varvec{0}_{n-k-1} \right\} , \end{aligned}$$(11)where \(\mathbf {1}^\intercal = \begin{pmatrix} 1&0&\dots&0 \end{pmatrix} ^\intercal \), \(\varvec{S}= \begin{pmatrix} \mathbf {1}^\intercal&\varvec{S}' \end{pmatrix}\) and \(\varvec{C}= \begin{pmatrix} \varvec{I}_r&\varvec{C}' \end{pmatrix}\).
-
The system in the coefficient variables we are interested in \( \mathcal {F}_M = \left\{ f = 0 \Big | f \in \mathbf{MaxMinors}\left( \begin{pmatrix} \varvec{I}_r&\varvec{C}' \end{pmatrix}\varvec{H}^\intercal \right) \right\} . \)
-
Let \(V_{\mathbb {F}_{q}}({\mathcal {F}_C})\) be the set of solutions of (11) with all variables in \(\mathbb {F}_{q}\), that is \(V_{\mathbb {F}_{q}}(\mathcal {F}_C) = \) \( \Big \{(\varvec{S}^*,\varvec{C}^*)\in {\mathbb {F}_{q}}^{m(r-1) + r(n-r)} : (1 \, \alpha \, \cdots \, \alpha ^{m-1}) (\mathbf {1}^\intercal \, \varvec{S}^*) (\varvec{I}_r \, \varvec{C}^*)\)\( \varvec{H}^\intercal = \mathbf {\varvec{0}}\Big \}.\)
-
Let \(V_{\mathbb {F}_{q}}(\mathcal {F}_M)\) be the set of solutions of \(\mathcal {F}_M\) with all variables in \(\mathbb {F}_{q}\), i.e. \( V_{\mathbb {F}_{q}}(\mathcal {F}_M) = \left\{ \varvec{C}^*\in {\mathbb {F}_{q}}^{r(n-r)} : \mathtt {Rank}_{\mathbb {F}_{q^m}}\left( \begin{pmatrix} \varvec{I}_r&\varvec{C}^* \end{pmatrix}\varvec{H}^\intercal \right) < r\right\} .\)
With these notations at hand, we now show that solving the decoding problem is left to solve the \(\mathbf{MaxMinors}\) system depending only on the \(\varvec{C}\) variables.
Proposition 3
If \(\varvec{e}\) can be uniquely decoded and has rank r, then
that is \(V_{\mathbb {F}_{q}}(\mathcal {F}_M)\) is the projection of \(V_{\mathbb {F}_{q}}(\mathcal {F}_C)\) on the last \(r(n-r)\) coordinates.
Proof
Let \((\varvec{S}^*, \varvec{C}^*)\in V_{\mathbb {F}_{q}}(\mathcal {F}_C)\), then \( \begin{pmatrix} 1&S_2^*&\dots S_r^* \end{pmatrix} = \begin{pmatrix} 1&\alpha&\cdots&\alpha ^{m-1} \end{pmatrix} \begin{pmatrix} \mathbf {1}^\intercal&\varvec{S}^* \end{pmatrix}\) belongs to the left kernel of the matrix \( \begin{pmatrix} \varvec{I}_r&\varvec{C}^* \end{pmatrix}\varvec{H}^\intercal \). Hence this matrix has rank less than r, and \(\varvec{C}^*\in V_{\mathbb {F}_{q}}(\mathcal {F}_M)\). Reciprocally, if \(\varvec{C}^*\in V_{\mathbb {F}_{q}}(\mathcal {F}_M)\), then the matrix \(\begin{pmatrix} \varvec{I}_r&\varvec{C}^* \end{pmatrix}\varvec{H}^\intercal \) has rank less than r, hence its left kernel over \(\mathbb {F}_{q^m}\) contains a non zero element \((S_1^*,\dots ,S_r^*) =(1,\alpha ,\dots ,\alpha ^{m-1})\varvec{S}^*\) with the coefficients of \(\varvec{S}^*\) in \(\mathbb {F}_{q}\). But \(S_1^*\) cannot be zero, as it would mean that \((0,S_2^*,\dots ,S_r^*) \begin{pmatrix} \varvec{I}_r&\varvec{C}^* \end{pmatrix}\) is an error of weight less than r solution of the decoding problem, and we assumed there is only one error of weight exactly r solution of the decoding problem. Then, \(({S_1^*}^{-1}(S_2^*,\dots ,S_r^*),\varvec{C}^*)\in V_{\mathbb {F}_{q}}(\mathcal {F}_C)\). \(\square \)
4 Solving RD: Overdetermined Case
In this section, we show that, when the number of equations is sufficiently large, we can solve the system given in Modeling 2 with only linear algebra computations, by linearization on the \(c_T\)’s.
4.1 The Overdetermined Case
The linear system given in Modeling 2 is described by the following matrix \(\mathbf{MaxMin}\) with rows indexed by \((J,i) : J\subset \{1..n-k-1\}, \#{J}=r, 0\le i \le m-1\) and columns indexed by \(T \subset \{1..n\}\) of size r, with the entry in row (J, i) and column T being the coefficient in \(\alpha ^i\) of the element \(\pm \left| \varvec{R} \right| _{T_1,J\backslash T_2} \in \mathbb {F}_{q^m}\). More precisely, we have

The matrix \(\mathbf{MaxMin}\) can have rank \(\left( {\begin{array}{c}n\\ r\end{array}}\right) -1\) at most; indeed if it had a maximal rank of \(\left( {\begin{array}{c}n\\ r\end{array}}\right) \), this would imply that all \(c_T\)’s are equal to 0, which is in contradiction with the assumption \(c_{\{1..r\}}=1\).
Proposition 4
If \(\mathbf{MaxMin}\) has rank \(\left( {\begin{array}{c}n\\ r\end{array}}\right) - 1\), then the right kernel of \(\mathbf{MaxMin}\) contains only one element \( \begin{pmatrix} \varvec{c}&1 \end{pmatrix}\in \mathbb {F}_{q}^{\left( {\begin{array}{c}n\\ r\end{array}}\right) }\) with value 1 on its component corresponding to \(c_{\{1..r\}}\). The components of this vector contain the values of the \(c_{T}\)’s, \(T\ne \{1..r\}\). This gives the values of all the variables \(C_{i,j} = (-1)^{r+i} c_{\{1..r\}\backslash \{i\}\cup \{j\}}\).
Proof
If \(\mathbf{MaxMin}\) has rank \(\left( {\begin{array}{c}n\\ r\end{array}}\right) -1\), then as there is a solution to the system, a row echelon form of the matrix has the shape
with \(\varvec{c}\) a vector in \(\mathbb {F}_{q}\) of size \(\left( {\begin{array}{c}n\\ r\end{array}}\right) - 1\): we cannot get a jump in the stair of the echelon form as it would imply that \(\mathcal {F}_M\) has no solution. Then \( \begin{pmatrix} \varvec{c}&1 \end{pmatrix}\) is in the right kernel of \(\mathbf{MaxMin}\). \(\square \)
It is then easy to recover the variables \(\varvec{S}\) from (11) by linear algebra. The following algorithm recovers the error if there is one solution to the system (11). It is shown in [11, Algorithm 1] how to deal with the other cases, and this can be easily adapted to the specialization considered in this paper.

Proposition 5
When \(m\left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \ge \left( {\begin{array}{c}n\\ r\end{array}}\right) - 1\) and \(\mathbf{MaxMin}\) has rank \(\left( {\begin{array}{c}n\\ r\end{array}}\right) -1\), then Algorithm 1 recovers the error in complexity
operations in the field \(\mathbb {F}_{q}\), where \(\omega \) is the constant of linear algebra.
Proof
To recover the error, the most consuming part is the computation of the left kernel of the matrix \(\mathbf{MaxMin}\) in \(\mathbb {F}_{q}^{m\left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \times \left( {\begin{array}{c}n\\ r\end{array}}\right) }\), in the case where \(m\left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \ge \left( {\begin{array}{c}n\\ r\end{array}}\right) - 1\).
This complexity is bounded by Eq. (14). \(\square \)
We ran a lot of experiments with random codes \(\mathcal {C}\) such that \(m\left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \ge \left( {\begin{array}{c}n\\ r\end{array}}\right) -1\), and the matrix \(\mathbf{MaxMin}\) was always of rank \(\left( {\begin{array}{c}n\\ r\end{array}}\right) -1\). That is why we propose the following heuristic about the rank of \(\mathbf{MaxMin}\).
Heuristic 1
(Overdetermined case). When \(m\left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \ge \left( {\begin{array}{c}n\\ r\end{array}}\right) -1\), with overwhelming probability, the rank of the matrix \(\mathbf{MaxMin}\) is \(\left( {\begin{array}{c}n\\ r\end{array}}\right) - 1\).
Figure 1 gives the experimental results for \(q=2\), \(r=3, 4, 5\) and different values of n. We choose to keep m prime and close to n/1.18 to have a data set containing the parameters of the ROLLO-I cryptosystem. We choose for k the minimum between \(\frac{n}{2}\) and the largest value leading to an overdetermined case. We have \(k=\frac{n}{2}\) as soon as \(n\ge 22\) for \(r=3\), \(n\ge 36\) for \(r=4\), \(n\ge 58\) for \(r=5\). The figure shows that the estimated complexity is a good upper bound for the computation’s complexity. It also shows that this upper bound is not tight. Note that the experimental values are the complexity of the whole attack, including building the matrix that requires to compute the minors of \(\varvec{R}\). Hence for small values of n, it may happen that this part of the attack takes more time than solving the linear system. This explains why, for \(r=3\) and \(n<28\), the experimental curve is above the theoretical one.

Theoretical vs Experimental value of the complexity of the computation. The computations are done using magma v2.22-2 on a machine with an Intel® Xeon® 2.00 GHz processor (Any mention of commercial products is for information only and does not imply endorsement by NIST). We measure the experimental complexity in terms of clock cycles of the CPU, given by the magma function ClockCycles(). The theoretical value is the binary logarithm of \(m\left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \left( {\begin{array}{c}n\\ r\end{array}}\right) ^{2.81-1}\). m is the largest prime less than n/1.18, k is the minimum of n/2 (right part of the graph) and the largest value for which the system is overdetermined (left part).

Theoretical value of the complexity of the computation in the overdetermined cases, which is the binary logarithm of \(m\left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \left( {\begin{array}{c}n\\ r\end{array}}\right) ^{2.81-1}\). m is the largest prime less than n/1.18, \(n=2k\). The axis “R1, R2, R3” correspond to the values of n for the cryptosystems ROLLO-I-128; ROLLO-I-192 and ROLLO-I-256.

Theoretical value of the complexity of RD in the overdetermined case (using punctured codes or specialization). \(\mathcal {C}\) is the smallest value between (17) and (16). m is the largest prime less than n/1.18, \(n=2k\). The dashed axes correspond to the values of n for the cryptosystems ROLLO-I-128; ROLLO-I-192 and ROLLO-I-256.
Figure 2 shows the theoretical complexity for the same parameter regime as Fig. 1 which fit the overdetermined case. The graph starts from the first value of n where (n/1.18, n, 2k, r) is in the overdetermined case. We can see that theoretically, the cryptosystem ROLLO-I-128 with parameters (79, 94, 47, 5) needs \(2^{73}\) bit operations to decode an error, instead of the announced \(2^{128}\) bits of security. In the same way, ROLLO-I-192 with parameters (89, 106, 53, 6) would have 86 bits of security instead of 192. The parameters (113, 134, 67, 7) for ROLLO-I-256 are not in the overdetermined case.
There are two classical improvements that can be used to lower the complexity of solving an algebraic system. The first one consists in selecting a subset of all equations, when some of them are redundant, see Sect. 4.2. The second one is the hybrid attack that will be explained in Sect. 4.3.
4.2 Improvement in the “Super”-Overdetermined Case by Puncturing
We consider the case when the system is “super”-overdetermined, i.e. when the number of rows in \(\mathbf{MaxMin}\) is really larger than the number of columns. In that case, it is not necessary to consider all equations, we just need the minimum number of them to be able to find the solution.
To select the good equations (i.e. the ones that are likely to be linearly independent), we can take the system \(\mathbf{MaxMinors}\) obtained by considering code \(\widetilde{C}\) punctured on the p last coordinates, instead of the entire code. Puncturing code \(\widetilde{C}\) is equivalent to shortening the dual code, i.e. considering the system
as we take \(\varvec{H}\) to be systematic on the last coordinates. This system is formed by a sub-sequence of polynomials in \(\mathbf{MaxMinors}\) that do not contain the variables \(c_{i,j}\) with \(n-p+1\le j \le n\). This system contains \(m\left( {\begin{array}{c}n-p-k-1\\ r\end{array}}\right) \) equations in \(\left( {\begin{array}{c}n-p\\ r\end{array}}\right) \) variables \(c_{T}\) with \( T \subset \{1..n-p-k-1\}\). If we take the maximal value of p such that \(m\left( {\begin{array}{c}n-p-k-1\\ r\end{array}}\right) \ge \left( {\begin{array}{c}n-p\\ r\end{array}}\right) -1\), we can still apply Algorithm 1 but the complexity is reduced to
operations in the field \(\mathbb {F}_{q}\).
4.3 Reducing to the Overdetermined Case: Hybrid Attack
Another classical improvement consists in using an hybrid approach mixing exhaustive search and linear resolution, like in [12]. This consists in specializing some variables of the system to reduce an underdetermined case to an overdetermined one. For instance, if we specialize a columns of the matrix \(\varvec{C}\), we are left with solving \(q^{ar}\) linear systems \(\mathbf{MaxMin}\) of size \(m\left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \times \left( {\begin{array}{c}n-a\\ r\end{array}}\right) \), and the global cost is
operations in the field \(\mathbb {F}_{q}\). In order to minimize the previous complexity (17), one chooses a to be the smallest integer such that the condition \(m\left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \ge \left( {\begin{array}{c}n-a\\ r\end{array}}\right) -1\) is fulfilled. Figure 3 page 16 gives the best theoretical complexities obtained for \(r=5\dots 9\) with the best values of a and p, for \(n=2k\). Table 1 page 24 gives the complexities of our attack (column “This paper”) for all the parameters in the ROLLO and RQC submissions to the NIST competition; for the sake of clarity, we give the previous complexity from [11].
5 Solving RD and MinRank: Underdetermined Case
This section analyzes the support minors modeling approach (Modeling 1).
5.1 Solving (3) by Direct Linearization
The number of monomials that can appear in Modeling 1 is \(K \left( {\begin{array}{c}n\\ r\end{array}}\right) \) whereas the number of equations is \(m \left( {\begin{array}{c}n\\ r+1\end{array}}\right) \). When the solution space of (3) is of dimension 1, we expect to solve it by direct linearization whenever:
We did a lot of experiments as explained in Sect. 5.6, and they suggest that it is the case.
Remark 2
Note that, in what follows, the Eq. (18) will sometimes be referred as the “\(b=1\) case”.
5.2 Solving Support Minors Modeling at a Higher Degree, \(q>b\)
In the case where Eq. (18) does not hold we may produce a generalized version of Support Minors Modeling, multiplying the Support Minors Modeling equations by homogeneous degree \(b-1\) monomials in the linear variables, resulting in a system of equations that are homogeneous degree 1 in the variables \(c_{T}\) and homogeneous degree b in the variables \(x_i\). The strategy will again be to linearize over monomials. Unlike in the simpler \(b=1\) case, for \(b \ge 2\) we cannot assume that all \(m \left( {\begin{array}{c}n\\ r+1\end{array}}\right) \left( {\begin{array}{c}K+b-2\\ b-1\end{array}}\right) \) equations we produce in this way are linearly independent up to the point where we can solve the system by linearization. In fact, we can construct explicit linear relations between the equations starting at \(b=2.\)
In this section, we will focus on the simpler \(q>b\) case. We will deal with the common \(q=2\) case in Sect. 5.3. There is however an unavoidable complication which occurs whenever we consider \(b\ge q\), \(q\ne 2\).
We can construct linear relations between the equations from determinantal identities involving maximal minors of matrices whose first rows are some of the \(\mathbf {r_j}\)’s concatenated with \(\varvec{C}\). For instance we may write the trivial identity for any subset J of columns of size \(r+2\):
Notice that this gives trivially a relation between certain equations corresponding to \(b=2\) since a cofactor expansion along the first row of \( \left| \begin{array}{c} \mathbf {r_j} \\ \mathbf {r_k}\\ \varvec{C} \end{array} \right| _{*,J}\) shows that this maximal minor is indeed a linear combination of terms which is the multiplication of a linear variable \(x_i\) with a maximal minor of the matrix \(\begin{pmatrix} \mathbf {r_k}\\ \varvec{C}\end{pmatrix}\) (in other words an equation corresponding to \(b=2\)). A similar result holds for \( \left| \begin{array}{c} \mathbf {r_k} \\ \mathbf {r_j}\\ \varvec{C} \end{array} \right| _{*,J}\) where a cofactor expansion along the first row yields terms formed by a linear variable \(x_i\) multiplied by a maximal minor of the matrix \(\begin{pmatrix} \mathbf {r_j}\\ \varvec{C}\end{pmatrix}\). This result can be generalized by considering symmetric tensors \((S_{j_1,\cdots , j_r})_{\begin{array}{c} 1 \le j_1 \le m\\ \cdots \\ 1 \le j_r \le m \end{array}}\) of dimension m of rank \(b \ge 2\) over \(\mathbb {F}_{q}\). Recall that these are tensors that satisfy
for any permutation \(\sigma \) acting on \(\{1..b\}\). This is a vector space that is clearly isomorphic to the space of homogeneous polynomials of degree b in \(y_1,\cdots ,y_m\) over \(\mathbb {F}_{q}\). The dimension of this space is therefore \(\left( {\begin{array}{c}m+b-1\\ b\end{array}}\right) \). We namely have
Proposition 6
For any symmetric tensor \((S_{j_1,\cdots , j_b})_{\begin{array}{c} 1 \le j_1 \le m\\ \cdots \\ 1 \le j_b \le m \end{array}}\) of dimension m of rank \(b\ge 2\) over \(\mathbb {F}_{q}\) and any subset J of \(\{1..n\}\) of size \(r+b\), we have:
Proof
Notice first that the maximal minor \(\left| \begin{array}{c} \mathbf {r_{j_1}} \\ \cdots \\ \mathbf {r_{j_b}}\\ \varvec{C} \end{array} \right| _{*,J}\) is equal to 0 whenever at least two of the \(j_i\)’s are equal. The left-hand sum reduces therefore to a sum of terms of the form \(\sum _{\sigma \in S_b} S_{\sigma (j_1),\cdots ,\sigma (j_b)} \left| \begin{array}{c} \mathbf {r_{\sigma (j_1)}} \\ \cdots \\ \mathbf {r_{\sigma (j_b)}}\\ \varvec{C} \end{array} \right| _{*,J}\) where all the \(j_i\)’s are different. Notice now that from the fact that S is a symmetric tensor we have
because the determinant is an alternating form and there as many odd and even permutations in the symmetric group of order b when \(b \ge 2\). \(\square \)
This proposition can be used to understand the dimension \(\mathrm {D}\) of the space of linear equations we obtain after linearizing the equations we obtain for a certain b. For instance for \(b=2\) we obtain \(m \left( {\begin{array}{c}n\\ r+1\end{array}}\right) K\) linear equations (they are obtained by linearizing the equations resulting from multiplying all the equations of the support minors modeling by one of the K linear variables). However as shown by Proposition 6 all of these equations are not independent and we have \(\left( {\begin{array}{c}n\\ r+2\end{array}}\right) \left( {\begin{array}{c}m+1\\ 2\end{array}}\right) \) linear relations coming from all relations of the kind
In our experiments, these relations turnt out to be independent yielding that the dimension \(\mathrm {D}\) of this space should not be greater than \( m \left( {\begin{array}{c}n\\ r+1\end{array}}\right) K - \left( {\begin{array}{c}n\\ r+2\end{array}}\right) \left( {\begin{array}{c}m+1\\ 2\end{array}}\right) \). Experimentally, we observed that we indeed had
For larger values of b things get more complicated but again Proposition 6 plays a key role here. Consider for example the case \(b=3\). We have in this case \(m \left( {\begin{array}{c}n\\ r+1\end{array}}\right) \left( {\begin{array}{c}K+1\\ 2\end{array}}\right) \) equations obtained by multiplying all the equations of the support minors modeling by monomials of degree 2 in the linear variables. Again these equations are not all independent, there are \(\left( {\begin{array}{c}m+1\\ 2\end{array}}\right) \left( {\begin{array}{c}n\\ r+2\end{array}}\right) K\) equations obtained by mutiplying all the linear relations between the \(b=2\) equations derived from (19) by a linear variable, they are of the form
But all these linear relations are themselves not independent as can be checked by using Proposition 6 with \(b=3\), we namely have for any symmetric tensor \(S_{i,j,k}\) of rank 3:
This induces linear relations among the equations (20), as can be verified by a cofactor expansion along the first row of the left-hand term of (21) which yields an equation of the form
where the \(\varvec{S}^i=(S^i_{j,k})_{\begin{array}{c} 1 \le j \le m\\ 1 \le k \le m \end{array}}\) are symmetric tensors of order 2. We would then expect that the dimension of the set of linear equations obtained from (20) is only \(\left( {\begin{array}{c}m+1\\ 2\end{array}}\right) \left( {\begin{array}{c}n\\ r+2\end{array}}\right) K - \left( {\begin{array}{c}n\\ r+3\end{array}}\right) \left( {\begin{array}{c}m+2\\ 3\end{array}}\right) \) yielding an overall dimension \(\mathrm {D}\) of order
which is precisely what we observe experimentally. This argument extends also to higher values of b, so that, if linear relations of the form considered above are the only relevant linear relations, then the number of linearly independent equations available for linearization at a given value of b is:
Heuristic 2
Experimentally, we found this to be the case with overwhelming probability (see Sect. 5.6) with the only general exceptions being:
-
1.
When \({\mathrm {D_{exp}}}\) exceeds the number of monomials for a smaller value of b, typically 1, the number of equations is observed to be equal to the number of monomials for all higher values of b as well, even if \({\mathrm {D_{exp}}}\) does not exceed the total number of monomials at these higher values of b.
-
2.
When the MinRank Problem has a nontrivial solution and cannot be solved at \(b=1\), we find the maximum number of linearly independent equations is not the total number of monomials but is less by 1. This is expected, since when the underlying MinRank problem has a nontrivial solution, then the Support Minors Modeling equations have a 1 dimensional solution space.
-
3.
When \(b\ge r+2\), the equations are not any more linearly independent, and we give an explanation in Sect. 5.4.
In summary, in the general case \(q>b\), the number of monomials is \(\left( {\begin{array}{c}n\\ r\end{array}}\right) \left( {\begin{array}{c}K+b-1\\ b\end{array}}\right) \) and we expect to be able to linearize at degree b whenever \(b<r+2\) and
Note that, for \(b=1\), we recover the result (18). As this system is very sparse, with \(K(r+1)\) monomials per equation, one can solve it using Wiedemann algorithm [39]; thus the complexity to solve MinRank problem when \(b<q\), \(b<r+2\) is
where b is the smallest positive integer so that the condition (23) is fulfilled.
5.3 The \(q=2\) Case
The same considerations apply in the \(q=2\) case, but due to the field equations, \(x_i^2=x_i\), for systems with \(b\ge 2\), a number of monomials will collapse to a lower degree. This results in a system which is no longer homogeneous. Thus, in this case it is most profitable to combine the equations obtained at a given value of b with those produced using all smaller values of b. Similar considerations to the general case imply that as long as \(b<r+2\) we will have
equations with which to linearize the \(\sum _{j=1}^b\left( {\begin{array}{c}n\\ r\end{array}}\right) \left( {\begin{array}{c}K\\ j\end{array}}\right) \) monomials that occur at a given value of b. We therefore expect to be able to solve by linearization when \(b < r+2\) and b is large enough that
Similarly to the general case for any q described in the previous section, the complexity to solve MinRank problem when \(q=2\) and \(b<r+2\) is
where b is the smallest positive integer so that the condition (26) is fulfilled.
5.4 Toward the \(b\ge r+2\) Case
We can also construct additional nontrivial linear relations starting at \(b=r+2\). The simplest example of this sort of linear relations occurs when \(m > r+1\). Note that each of the Support Minors modeling equations at \(b=1\) is bilinear in the \(x_i\) variables and a subset consisting of \(r+1\) of the variables \(c_T\). Note also, that there are a total of m equations derived from the same subset (one for each row of \( \sum _{i=0}^{K}{x_iM_i}\).) Therefore, if we consider the Jacobian of the \(b=1\) equations with respect to the variables \(c_T\), the m equations involving only \(r+1\) of the variables \(c_T\) will form a submatrix with m rows and only \(r+1\) nonzero columns. Using a Cramer-like formula, we can therefore construct left kernel vectors for these equations; its coefficients would be degree \(r+1\) polynomials in the \(x_i\) variables. Multiplying the equations by this kernel vector will produce zero, because the \(b=1\) equations are homogeneous, and multiplying equations from a bilinear system by a kernel vector of the Jacobian of that system cancels all the highest degree terms. This suggests that Eq. (22) needs to be modified when we consider values of b that are \(r+2\) or greater. These additional linear relations do not appear to be relevant in the most interesting range of b for attacks on any of the cryptosystems considered, however.
5.5 Improvements for Generic Minrank
The two classical improvements Sect. 4.2 in the “super”-overdetermined cases the hybrid attack and Sect. 4.3 can also apply for Generic Minrank.
We can consider applying the Support Minors Modeling techniques to submatrices \(\sum _{i=1}^K \varvec{M}'_ix_i\) of \(\sum _{i=1}^K \varvec{M}_ix_i\). Note that if \(\sum _{i=1}^K \varvec{M}_ix_i\) has rank \( \le r\), so does \(\sum _{i=1}^K \varvec{M}'_ix_i\), so assuming we have a unique solution \(x_i\) to both systems of equations, it will be the same. Generically, we will keep a unique solution in the smaller system as long as the decoding problem has a unique solution, i.e. as long as the Gilbert-Varshamov bound \(K \le (m-r)(n-r)\) is satisfied.
We generally find that the most beneficial settings use matrices with all m rows, but only \(n' \le n\) of the columns. This corresponds to a puncturing of the corresponding matrix code over \(\mathbb {F}_{q}\). It is always beneficial for the attacker to reduce \(n'\) to the minimum value allowing linearization at a given degree b, however, it can sometimes lead to an even lower complexity to reduce \(n'\) further and solve at a higher degree b.
On the other side, we can run exhaustive search on a variables \(x_i\) in \(\mathbb {F}_{q}\) and solve \(q^a\) systems with a smaller value of b, so that the resulting complexity is smaller than solving directly the system with a higher value of b. This optimization is considered in the attack against ROLLO-I-256 (see Table 1); more details about this example are given in Sect. 6.1.
5.6 Experimental Results for Generic Minrank
We verified experimentally that the value of \({\mathrm {D_{exp}}}\) correctly predicts the number of linearly independent polynomials. We constructed random systems (with and without a solution) for \(q=2,13\), with \(m=7,8\), \(r=2,3\), \(n=r+3,r+4,r+5\), \(K=3,\ldots ,20\). Most of the time, the number of linearly independent polynomials was as expected. For \(q=13\), we had a few number of non-generic systems (usually less than \(1\%\) over 1000 random samples), and only in square cases where the matrices have a predicted rank equal to the number of columns. For \(q=2\) we had a higher probability of linear dependencies, due to the fact that over small fields, random matrices have a non-trivial probability to be non invertible. Anyway, as soon as the field is big enough or the number \({\mathrm {D_{exp}}}\) is large compared to the number of columns, all our experiments succeeded over 1000 samples.
5.7 Using Support Minors Modeling Together with MaxMin for RD
Recall that from MaxMin, we obtain \(m \left( {\begin{array}{c}n-k-1\\ r\end{array}}\right) \) homogeneous linear equations in the \(c_T\)’s. These can be used to produce additional equations over the same monomials as used for Support Minors Modeling with \(K=m(k+1)\). However here, unlike in the overdetermined case, it is not interesting to specialize the matrix \(\varvec{C}\). Indeed, in that case it is sufficient to assume that the first component of \(\varvec{e}\) is nonzero, then we can specialize to \((*,0,\dots ,0)^\intercal \) the first column of \(\varvec{S}\varvec{C}\). Now, Eq. (3) gives \(m-1\) linear equations involving only the \(x_i\)’s, that allows us to eliminate \(m-1\) variables \(x_i\)’s from the system and reduces the number of linear variables to \(K=mk+1\). We still expect a space of dimension 1 for the \(x^\alpha c_T\)’s, and this will be usefull for the last step of the attack described in Sect. 5.8.
When \(q>b\), we multiply the equations from MaxMin by degree b monomials in the \(x_i\)’s. When \(q=2\), this can be done by multiplying the MaxMin equations by monomials of degree b or less. All these considerations lead to a similar heuristic as Heuristic 1, i.e. linearization is possible for \(q>b\), \(0<b<r+2\) when:

and for \(q=2\), \(0<b<r+2\) whenever:
where
For the latter, it leads to a complexity of
where b is the smallest positive integer so that the condition (28) is fulfilled. This complexity formula correspond to solving a linear system with \(A_b\) unknowns and \(B_b+C_b\) equations, recall that \(\omega \) is the constant of linear algebra.
For a large range of parameters, this system is particularly sparse, so one could take advantage of that to use Wiedemann algorithm [39]. More precisely, for values of m, n, r and k of ROLLO or RQC parameters (see Table 3 and Table 4) for which the condition (28) is fulfilled, we typically find that \(b\approx r\).
In this case, \(B_b\) equations consist of \(\left( {\begin{array}{c}k+r+1\\ r\end{array}}\right) \) monomials, \(C_b\) equations consist of \((mk+1)(r+1)\) monomials, and the total space of monomials is of size \(A_b\). The Wiedemann’s algorithm complexity can be written in term of the average number of monomials per equation, in our case it is
Thus the linearized system at degree b is sufficiently sparse that Wiedemann outperforms Strassen for \(b\ge 2\). Therefore the complexity of support minors modeling bootstrapping MaxMin for RD is
where b is still the smallest positive integer so that the condition (28) is fulfilled. A similar formula applies for the case \(q>b\).
5.8 Last Step of the Attack
To end the attack on MinRank using Support Minors modeling or the attack on RD using MaxMinors modeling in conjunction with Support Minors modeling, one needs to find the value of each unknown. When direct linearization at degree b works, we get \(\varvec{v}= (v_{\alpha ,T}^*)_{\alpha ,T}\) one nonzero vector containing one possible value for all \(x^\alpha c_T\), where the \(x^\alpha \)’s are monomials of degree \(b-1\) in the \(x_i\)’s, and all the other solutions are multiples of \(\varvec{v}\) (as the solution space has dimension 1).
In order to extract the values of all the \(x_i\)’s and thus finish the attack, one needs to find one \(i_0\) and one \(T_0\) such that \(x_{i_0}\ne 0\) and \(c_{T_0}\ne 0\). This is easily done by looking for a nonzero entry \(v^*\) of \(\varvec{v}\) corresponding to a monomial \(x_{i_0}^{b-1}c_{T_0}\). At this point, we know that there is a solution of the system with \(x_{i_0}=1\) and \(c_{T_0}=v^*\). Then by computing the quotients of the entries in \(\varvec{v}\) corresponding to the monomials \(x_ix_{i_0}^{b-2}c_{T_0}\) and \(x_{i_0}^{b-1}c_{T_0}\) we get the values of
Doing so, one gets the values of all the \(x_i\)’s. This finishes the attack. This works without any assumption on MinRank, and with the assumption that the first coordinate of \(\varvec{e}\) is nonzero for RD. If it is not the case, one uses another coordinate of \(\varvec{e}\).
6 Complexity of the Attacks for Different Cryptosystems and Comparison with Generic Gröbner Basis Approaches
6.1 Attacks Against the Rank Decoding Problem
Table 1 presents the best complexity of our attacks (see Sects. 4 and 5) against RD and gives the binary logarithm of the complexities (column “This paper”) for all the parameters in the ROLLO and RQC submissions to the NIST competition and Loidreau cryptosystem [30]; for the sake of clarity, we give the previous best known complexity from [11] (last column). The third column gives the original rate for being overdeterminate. The column ‘a’ indicates the number of specialized columns in the hybrid approach (Sect. 4.3), when the system is not overdetermined. Column ‘p’ indicates the number of punctured columns in the “super”-overdetermined cases (Sect. 4.2). Column ‘b’ indicates that we use Support Minors Modeling in conjunction with MaxMin (Sect. 5.7).
Let us give more details on how we compute the best complexity, in Table 1, for ROLLO-I-256 whose parameters are \((m,n,k,r)=(113,134,67,7)\). The attack from Sect. 4 only works with the hybrid approach, thus requiring \(a=8\) and resulting in a complexity of 158 bits (using (17) and \(\omega =2.81\)). On the other hand, the attack from Sect. 5.7 needs \(b=2\) which results in a complexity of 154 (this time using Wiedemann’s algorithm). However, if we specialize \(a=3\) columns in \(\varvec{C}\), we get \(b=1\) and the resulting complexity using Wiedemann’s algorithm is 151.
6.2 Attacks Against the MinRank Problem
Table 2 shows the complexity of our attack against generic MinRank problems for GeMSS and Rainbow, two cryptosystems at the second round of the NIST competition. Our new attack is compared to the previous MinRank attacks, which use minors modeling in the case of GeMSS [14], and a linear algebra search [18] in the case of Rainbow. Concerning Rainbow, the acronyms RBS and DA stand from Rainbow Band Separation and Direct Algebraic respectively; the column “Best/Type” shows the complexity of the previous best attack against Rainbow, which was not based on MinRank before our new attack (except for Ia). All new complexities are computed by finding the number of columns \(n'\) and the degree b that minimize the complexity, as described in Sect. 5.
6.3 Our Approach vs. Using Generic Gröbner Basis Algorithms
Since our approach is an algebraic attack, it relies on solving a polynomial system, thus it looks like a Gröbner basis computation. In fact, we do compute a Gröbner basis of the system, as we compute the unique solution of the system, which represents its Gröbner basis.
Nevertheless, our algorithm is not a generic Gröbner basis algorithm as it only works for the special type of system studied in this paper: the RD and MinRank systems. As it is specifically designed for this purpose and for the reasons detailed below, it is more efficient than a generic algorithm.
There are three main reasons why our approach is more efficient than a generic Gröbner basis algorithm:
-
We compute formally (that is to say at no extra cost except the size of the equations) new equations of degree r (the \(\mathbf{MaxMinors}\) ones) that are already in the ideal, but not in the vector space
$$ \mathcal {F}_r := \langle uf : \text {{ u} monomial of degree r-2, { f} in the set of initial polynomials} \rangle . $$In fact, a careful analysis of a Gröbner basis computation with a standard strategy shows that those equations are in \(\mathcal {F}_{r+1}\), and that the first degree fall for those systems is \(r+1\). Here, we apply linear algebra directly on a small number of polynomials of degree r (see the next two items for more details), whereas a generic Gröbner basis algorithm would compute many polynomials of degree \(r+1\) and then reduce them in order to get those polynomials of degree r.
-
A classical Gröbner basis algorithm using linear algebra and a standard strategy typically constructs Macaulay matrices, where the rows correspond to polynomials in the ideal and the columns to monomials of a certain degree. Here, we introduce variables \(c_T\) that represent maximal minors of \(\varvec{C}\), and thus represent not one monomial of degree r, but r! monomials of degree r. As we compute the Gröbner basis by using only polynomials that can be expressed in terms of those variables (see the last item below), this reduces the number of columns of our matrices by a factor around r! compared to generic Macaulay-like matrices.
-
The solution can be found by applying linear algebra only to some specific equations, namely the MaxMinors ones in the overdetermined case, and in the underdetermined case, equations that have degree 1 in the \(c_T\) variables, and degree \(b-1\) in the \(x_i\) variables (see Sect. 5.2). This enables us to deal with polynomials involving only the \(c_T\) variables and the \(x_i\) variables, whereas a generic Gröbner basis algorithm would consider all monomials up to degree \(r+b\) in the \(x_l\) and the \(c_{i,j}\) variables. This drastically reduces the number of rows and columns in our matrices.
For all of those reasons, in the overdetermined case, only an elimination on our selected MaxMinors equations (with a “compacted” matrix with respect to the columns) is sufficient to get the solution; so we essentially avoid going up to the degree \(r+1\) to produce those equations, we select a small number of rows, and gain a factor r! on the number of columns.
In the underdetermined case, we find linear equations by linearization on some well-chosen subspaces of the vector space \(\mathcal {F}_{r+b}\). We have theoretical reasons to believe that our choice of subspace should lead to the computation of the solution (as usual, this is a “genericity” hypothesis), and it is confirmed by all our experiments.
7 Examples of New Parameters for ROLLO-I and RQC
In light of the attacks presented in this article, it is possible to give a few examples of new parameters for the rank-based cryptosystems, submitted to the NIST competition, ROLLO and RQC. With these new parameters, ROLLO and RQC would be resistant to our attacks, while still remaining attractive, for example with a loss of only about 50% in terms of key size for ROLLO-I.
For cryptographic purpose, parameters have to belong to an area which does not correspond to the overdetermined case and such that the hybrid approach would make the attack worse than in the underdetermined case.
Alongside the algebraic attacks in this paper, the best combinatorial attack against RD is in [4]; its complexity for (m, n, k, r) decoding is
In the following tables, we consider \(\omega =2.81\). We also use the same notation as in ROLLO and RQC submissions’ specifications [1, 7]. In particular, n is the block-length and not the length of the code which can be either 2n or 3n. Moreover, for ROLLO (Table 3):
-
over/hybrid is the cost of the hybrid attack; the value of a is the smallest to reach the overdetermined case, \(a=0\) means that parameters are already in the overdetermined case,
-
under is the case of underdetermined attack.
-
comb is the cost of the best combinatorial attack mentioned above,
-
DFR is the binary logarithm of the Decoding Failure Rate,
and for RQC (Table 4):
-
hyb2n(a): hybrid attack for length 2n, the value of a is the smallest to reach the overdetermined case, \(a=0\) means that parameters are already in the overdetermined case,
-
hyb3n(a): non-homogeneous hybrid attack for length 3n, a is the same as above. This attack corresponds to an adaptation of our attack to a non-homogeneous error of the RQC scheme, more details are given in [1],
-
und2n: underdetermined attack for length 2n,
-
comb3n: combinatorial attack for length 3n.
8 Conclusion
In this paper, we improve on the results by [11] on the Rank Decoding problem by providing a better analysis which permits to avoid the use of generic Gröbner bases algorithms and permits to completely break rank-based cryptosystems parameters proposed to the NIST Standardization Process, when the analysis in [11] only attacked them slightly.
We generalize this approach to the case of the MinRank problem for which we obtain the best known complexity with algebraic attacks.
Overall, the results proposed in this paper give a new and deeper understanding of the connections and the complexity of two problems of great interest in post-quantum cryptography: the Rank Decoding and the MinRank problems.
References
Aguilar Melchor, C., et al.: Rank quasi cyclic (RQC). Second round submission to the NIST post-quantum cryptography call, April 2020
Aguilar Melchor, C., et al.: First round submission to the NIST post-quantum cryptography call, November 2017
Aguilar Melchor, C., et al.: Rank quasi cyclic (RQC). First round submission to the NIST post-quantum cryptography call, November 2017
Aragon, N., Gaborit, P., Hauteville, A., Tillich, J.P.: A new algorithm for solving the rank syndrome decoding problem. In: Proceedings of the IEEE ISIT (2018)
Aragon, N., et al.: LAKE - Low rAnk parity check codes Key Exchange. First round submission to the NIST post-quantum cryptography call, November 2017
Aragon, N., et al.: LOCKER - LOw rank parity ChecK codes EncRyption. First round submission to the NIST post-quantum cryptography call, November 2017
Aragon, N., et al.: ROLLO (merger of Rank-Ouroboros, LAKE and LOCKER). Second round submission to the NIST post-quantum cryptography call, April 2020
Aragon, N., Blazy, O., Gaborit, P., Hauteville, A., Zémor, G.: Durandal: a rank metric based signature scheme. In: Ishai, Y., Rijmen, V. (eds.) EUROCRYPT 2019. LNCS, vol. 11478, pp. 728–758. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-17659-4_25
Aragon, N., Gaborit, P., Hauteville, A., Ruatta, O., Zémor, G.: RankSign - a signature proposal for the NIST’s call. First round submission to the NIST post-quantum cryptography call, November 2017
Aragon, N., Gaborit, P., Hauteville, A., Tillich, J.P.: A new algorithm for solving the rank syndrome decoding problem. In: 2018 IEEE International Symposium on Information Theory (ISIT), pp. 2421–2425. IEEE (2018)
Bardet, M., et al.: An algebraic attack on rank metric code-based cryptosystems. In: Canteaut, A., Ishai, Y. (eds.) EUROCRYPT 2020. LNCS, vol. 12107, pp. 64–93. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-45727-3_3
Bettale, L., Faugere, J.C., Perret, L.: Hybrid approach for solving multivariate systems over finite fields. J. Math. Cryptol. 3(3), 177–197 (2009)
Buss, J.F., Frandsen, G.S., Shallit, J.O.: The computational complexity of some problems of linear algebra. J. Comput. Syst. Sci. 58(3), 572–596 (1999)
Casanova, A., Faugère, J., Macario-Rat, G., Patarin, J., Perret, L., Ryckeghem, J.: GeMSS: A Great Multivariate Short Signature. Second round submission to the NIST post-quantum cryptography call, April 2019
Courtois, N.T.: Efficient zero-knowledge authentication based on a linear algebra problem MinRank. In: Boyd, C. (ed.) ASIACRYPT 2001. LNCS, vol. 2248, pp. 402–421. Springer, Heidelberg (2001). https://doi.org/10.1007/3-540-45682-1_24
Debris-Alazard, T., Tillich, J.-P.: Two attacks on rank metric code-based schemes: RankSign and an IBE scheme. In: Peyrin, T., Galbraith, S. (eds.) ASIACRYPT 2018. LNCS, vol. 11272, pp. 62–92. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-03326-2_3
Ding, J., Chen, M.S., Petzoldt, A., Schmidt, D., Yang, B.Y.: Gui. First round submission to the NIST post-quantum cryptography call, November 2017
Ding, J., Chen, M.S., Petzoldt, A., Schmidt, D., Yang, B.Y.: Rainbow. Second round submission to the NIST post-quantum cryptography call, April 2019
Faugère, J.-C., Levy-dit-Vehel, F., Perret, L.: Cryptanalysis of MinRank. In: Wagner, D. (ed.) CRYPTO 2008. LNCS, vol. 5157, pp. 280–296. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-85174-5_16
Faugère, J., Safey El Din, M., Spaenlehauer, P.: Computing loci of rank defects of linear matrices using Gröbner bases and applications to cryptology. In: International Symposium on Symbolic and Algebraic Computation, ISSAC 2010, Munich, Germany, 25–28 July 2010, pp. 257–264 (2010)
Gabidulin, E.M.: Theory of codes with maximum rank distance. Problemy Peredachi Informatsii 21(1), 3–16 (1985)
Gabidulin, E.M., Paramonov, A.V., Tretjakov, O.V.: Ideals over a non-commutative ring and their application in cryptology. In: Davies, D.W. (ed.) EUROCRYPT 1991. LNCS, vol. 547, pp. 482–489. Springer, Heidelberg (1991). https://doi.org/10.1007/3-540-46416-6_41
Gaborit, P., Murat, G., Ruatta, O., Zémor, G.: Low rank parity check codes and their application to cryptography. In: Proceedings of the Workshop on Coding and Cryptography WCC 2013, Bergen, Norway (2013)
Gaborit, P., Ruatta, O., Schrek, J.: On the complexity of the rank syndrome decoding problem. IEEE Trans. Inf. Theory 62(2), 1006–1019 (2016)
Gaborit, P., Ruatta, O., Schrek, J., Zémor, G.: New results for rank-based cryptography. In: Pointcheval, D., Vergnaud, D. (eds.) AFRICACRYPT 2014. LNCS, vol. 8469, pp. 1–12. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-06734-6_1
Gaborit, P., Ruatta, O., Schrek, J., Zémor, G.: RankSign: an efficient signature algorithm based on the rank metric. In: Mosca, M. (ed.) PQCrypto 2014. LNCS, vol. 8772, pp. 88–107. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-11659-4_6
Gaborit, P., Zémor, G.: On the hardness of the decoding and the minimum distance problems for rank codes. IEEE Trans. Inf. Theory 62(12), 7245–7252 (2016)
Hoffstein, J., Pipher, J., Silverman, J.H.: NTRU: a ring-based public key cryptosystem. In: Buhler, J.P. (ed.) ANTS 1998. LNCS, vol. 1423, pp. 267–288. Springer, Heidelberg (1998). https://doi.org/10.1007/BFb0054868
Kipnis, A., Shamir, A.: Cryptanalysis of the HFE public key cryptosystem by relinearization. In: Wiener, M. (ed.) CRYPTO 1999. LNCS, vol. 1666, pp. 19–30. Springer, Heidelberg (1999). https://doi.org/10.1007/3-540-48405-1_2
Loidreau, P.: A new rank metric codes based encryption scheme. In: Lange, T., Takagi, T. (eds.) PQCrypto 2017. LNCS, vol. 10346, pp. 3–17. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-59879-6_1
Misoczki, R., Tillich, J.P., Sendrier, N., Barreto, P.S.L.M.: MDPC-McEliece: New McEliece variants from moderate density parity-check codes (2012)
Otmani, A., Kalachi, H.T., Ndjeya, S.: Improved cryptanalysis of rank metric schemes based on Gabidulin codes. Des. Codes Cryptogr. 86(9), 1983–1996 (2017). https://doi.org/10.1007/s10623-017-0434-5
Ourivski, A.V., Johansson, T.: New technique for decoding codes in the rank metric and its cryptography applications. Probl. Inf. Transm. 38(3), 237–246 (2002)
Overbeck, R.: A new structural attack for GPT and variants. In: Dawson, E., Vaudenay, S. (eds.) Mycrypt 2005. LNCS, vol. 3715, pp. 50–63. Springer, Heidelberg (2005). https://doi.org/10.1007/11554868_5
Patarin, J.: Hidden fields equations (HFE) and isomorphisms of polynomials (IP): two new families of asymmetric algorithms. In: Maurer, U. (ed.) EUROCRYPT 1996. LNCS, vol. 1070, pp. 33–48. Springer, Heidelberg (1996). https://doi.org/10.1007/3-540-68339-9_4
Petzoldt, A., Chen, M.-S., Yang, B.-Y., Tao, C., Ding, J.: Design principles for HFEv- based multivariate signature schemes. In: Iwata, T., Cheon, J.H. (eds.) ASIACRYPT 2015. LNCS, vol. 9452, pp. 311–334. Springer, Heidelberg (2015). https://doi.org/10.1007/978-3-662-48797-6_14
Porras, J., Baena, J., Ding, J.: ZHFE, a new multivariate public key encryption scheme. In: Mosca, M. (ed.) PQCrypto 2014. LNCS, vol. 8772, pp. 229–245. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-11659-4_14
Verbel, J., Baena, J., Cabarcas, D., Perlner, R., Smith-Tone, D.: On the Complexity of “Superdetermined" Minrank Instances. In: Ding, J., Steinwandt, R. (eds.) PQCrypto 2019. LNCS, vol. 11505, pp. 167–186. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-25510-7_10
Wiedemann, D.: Solving sparse linear equations over finite fields. IEEE Trans. Inf. Theory 32(1), 54–62 (1986)
Acknowledgements
We would like to warmly thank the reviewers, who did a wonderful job by carefully reading our article and giving us useful feedback.
This work has been supported by the French ANR project CBCRYPT (ANR-17-CE39-0007) and the MOUSTIC project with the support from the European Regional Development Fund and the Regional Council of Normandie.
Javier Verbel was supported for this work by Colciencias scholarship 757 for PhD studies and the University of Louisville facilities.
We would like to thank John B Baena, and Karan Khathuria for useful discussions. We thank the Facultad de Ciencias of the Universidad Nacional de Colombia sede Medellín for granting us access to the Enlace server, where we ran some of the experiments.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 International Association for Cryptologic Research
About this paper

Cite this paper
Bardet, M. et al. (2020). Improvements of Algebraic Attacks for Solving the Rank Decoding and MinRank Problems. In: Moriai, S., Wang, H. (eds) Advances in Cryptology – ASIACRYPT 2020. ASIACRYPT 2020. Lecture Notes in Computer Science(), vol 12491. Springer, Cham. https://doi.org/10.1007/978-3-030-64837-4_17
Download citation
DOI: https://doi.org/10.1007/978-3-030-64837-4_17
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-64836-7
Online ISBN: 978-3-030-64837-4
eBook Packages: Computer ScienceComputer Science (R0)
