
Abstract
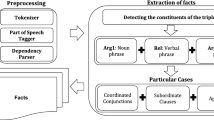
Recently, many Open IE systems have been developed based on using deep linguistic features such as dependency-parse features to overcome the limitations presented in older Open IE systems which use only shallow information like part-of-speech or chunking. Even though these newer systems have some clear advantages in their extractions, they also possess several issues which do not exist in old systems. In this paper, we analyze the outputs from several popular Open IE systems to find out their strength and weaknesses. Then we introduce ReLink, a novel Open IE system for extracting binary relations from open-domain text. Its working model is based on identifying correct phrases and linking them in the most proper way to reflect their relationship in a sentence. After establishing connections, it can easily extract relations by using several pre-defined patterns. Despite using only shallow linguistic features for extraction, it does not have the same weakness that existed in older systems, and it can also avoid many similar issues arising in recent Open IE systems. Our experiments show that ReLink achieves larger Area Under Precision-Recall Curve compared with ReVerb and Ollie, two well-known Open IE systems.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Banko, M., Cafarella, M.J., Soderland, S., Broadhead, M., Etzioni, O.: Open information extraction from the web. In: IJCAI, vol. 7, pp. 2670–2676 (2007)
Berant, J., Dagan, I., Goldberger, J.: Global learning of typed entailment rules. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, vol. 1, pp. 610–619. Association for Computational Linguistics (2011)
Christensen, J., Mausam, S.S., Soderland, S., Etzioni, O.: Towards coherent multi-document summarization. In: HLT-NAACL, pp. 1163–1173. Citeseer (2013)
Del Corro, L., Gemulla, R.: Clausie: Clause-based open information extraction. In: Proceedings of the 22nd International Conference on World Wide Web, pp. 355–366. ACM (2013)
Etzioni, O., et al.: Unsupervised named-entity extraction from the web: an experimental study. Artif. Intell. 165(1), 91–134 (2005)
Fader, A., Soderland, S., Etzioni, O.: Identifying relations for open information extraction. In: Proceedings of the Conference of Empirical Methods in Natural Language Processing (EMNLP 2011), Edinburgh, Scotland, UK, 27–31 July 2011 (2011)
Fader, A., Zettlemoyer, L., Etzioni, O.: Open question answering over curated and extracted knowledge bases. In: Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1156–1165. ACM (2014)
Gabor Angeli, M.J.P., Manning, C.D.: Leveraging linguistic structure for open domain information extraction. In: Proceedings of the Association of Computational Linguistics (ACL) (2015)
Gamallo, P., Garcia, M., Fernández-Lanza, S.: Dependency-based open information extraction. In: Proceedings of the Joint Workshop on Unsupervised and Semi-Supervised Learning in NLP, pp. 10–18. Association for Computational Linguistics (2012)
Kim, J.T., Moldovan, D.I.: Acquisition of semantic patterns for information extraction from corpora. In: Proceedings of Ninth Conference on Artificial Intelligence for Applications, pp. 171–176. IEEE (1993)
Li, P., Cai, W., Huang, H.: Weakly supervised natural language processing framework for abstractive multi-document summarization: weakly supervised abstractive multi-document summarization. In: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, pp. 1401–1410. ACM (2015)
Li, X., Roth, D.: Exploring evidence for shallow parsing. In: Proceedings of the 2001 Workshop on Computational Natural Language Learning, vol. 7, p. 6. Association for Computational Linguistics (2001)
Manning, C.D., Surdeanu, M., Bauer, J., Finkel, J., Bethard, S.J., McClosky, D.: The Stanford CoreNLP natural language processing toolkit. In: Association for Computational Linguistics (ACL) System Demonstrations, pp. 55–60 (2014). http://www.aclweb.org/anthology/P/P14/P14-5010
Mausam, Schmitz, M., Bart, R., Soderland, S., Etzioni, O.: Open language learning for information extraction. In: Proceedings of Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CONLL) (2012)
Reddy, S., Lapata, M., Steedman, M.: Large-scale semantic parsing without question-answer pairs. Trans. Assoc. Comput. Linguist. 2, 377–392 (2014)
Ruppert, E.: Unsupervised conceptualization and semantic text indexing for information extraction. In: Sack, H., Blomqvist, E., d’Aquin, M., Ghidini, C., Ponzetto, S.P., Lange, C. (eds.) ESWC 2016. LNCS, vol. 9678, pp. 853–862. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-34129-3_54
Schoenmackers, S., Etzioni, O., Weld, D.S., Davis, J.: Learning first-order horn clauses from web text. In: Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, pp. 1088–1098. Association for Computational Linguistics (2010)
Soderland, J.C.S., Mausam, G.B.: Hierarchical summarization: scaling up multi-document summarization. In: Proceedings of the 52nd Annual Meeting of the Association for Computlational Linguistics, pp. 902–912 (2014)
Stanovsky, G., Mausam, I.D.: Open IE as an intermediate structure for semantic tasks (2015)
Surdeanu, M.: Overview of the TAC2013 knowledge base population evaluation: English slot filling and temporal slot filling. In: Sixth Text Analysis Conference (2013)
Vo, D.T., Bagheri, E.: Open information extraction. arXiv preprint arXiv:1607.02784 (2016)
Wu, F., Weld, D.S.: Open information extraction using Wikipedia. In: Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pp. 118–127. Association for Computational Linguistics (2010)
Acknowledgments
This work was supported by JST CREST Grant Number JPMJCR1513 and in part by the Asian Office of Aerospace R&D (AOARD), Air Force Office of Scientific Research (Grant no. FA2386-19-1-4041).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Tran, XC., Nguyen, LM. (2021). ReLink: Open Information Extraction by Linking Phrases and Its Applications. In: Goswami, D., Hoang, T.A. (eds) Distributed Computing and Internet Technology. ICDCIT 2021. Lecture Notes in Computer Science(), vol 12582. Springer, Cham. https://doi.org/10.1007/978-3-030-65621-8_3
Download citation
DOI: https://doi.org/10.1007/978-3-030-65621-8_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-65620-1
Online ISBN: 978-3-030-65621-8
eBook Packages: Computer ScienceComputer Science (R0)