
Abstract
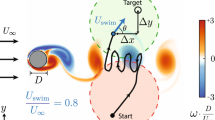
We present theoretical and numerical results concerning the problem to find the path that minimizes the time to navigate between two given points in a complex fluid under realistic navigation constraints. We contrast deterministic Optimal Navigation (ON) control with stochastic policies obtained by Reinforcement Learning (RL) algorithms. We show that Actor-Critic RL algorithms are able to find quasi-optimal solutions in the presence of either time-independent or chaotically evolving flow configurations. For our application, ON solutions develop unstable behavior within the typical duration of the navigation process, and are therefore not useful in practice. We first explore navigation of turbulent flow using a constant propulsion speed. Based on a discretized phase-space, the propulsion direction is adjusted with the aim to minimize the time spent to reach the target. Further, we explore a case where additional control is obtained by allowing the engine to power off. Exploiting advection of the underlying flow, allows the target to be reached with less energy consumption. In this case, we optimize a linear combination between the total navigation time and the total time the engine is switched off. Our approach can be generalized to other setups, for example, navigation under imperfect environmental forecast or with different models for the moving vessel.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Alexakis, A., Biferale, L.: Cascades and transitions in turbulent flows. Phys. Rep. 767–769, 1–101 (2018)
Andrew, Y.N., Harada, D., Russelt, S.: Policy invariance under reward transformations: theory and application to reward shaping. ICML 99, 278 (1999)
Bechinger, C., Di Leonardo, R., Löwen, H., Reichhardt, C., Volpe, G., Volpe, G.: Active particles in complex and crowded environments. Rev. Mod. Phys. 88(4), 045006 (2016)
Biferale, L., Bonaccorso, F., Buzzicotti, M., Clark Di Leoni, P., Gustavsson, K.: Zermelo’s problem: optimal point-to-point navigation in 2D turbulent flows using reinforcement learning. Chaos: Interdisc. J. Nonlinear Sci. 29(10), 103138 (2019)
Bryson, A.E., Ho, Y.: Applied Optimal Control: Optimization, Estimation and Control. Routledge, New York (1975)
Centurioni, L.R.: Drifter technology and impacts for sea surface temperature, sea-level pressure, and ocean circulation studies. In: Venkatesan, R., Tandon, A., D’Asaro, E., Atmanand, M.A. (eds.) Observing the Oceans in Real Time. SO, pp. 37–57. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-66493-4_3
Colabrese, S., Gustavsson, K., Celani, A., Biferale, L.: Flow navigation by smart microswimmers via reinforcement learning. Phys. Rev. Lett. 118(15), 158004 (2017)
Colabrese, S., Gustavsson, K., Celani, A., Biferale, L.: Smart inertial particles. Phys. Rev. Fluids 3(8), 084301 (2018)
Gustavsson, K., Biferale, L., Celani, A., Colabrese, S.: Finding efficient swimming strategies in a three-dimensional chaotic flow by reinforcement learning. Eur. Phys. J. E 40(12), 1–6 (2017). https://doi.org/10.1140/epje/i2017-11602-9
Kraus, N.D.: Wave glider dynamic modeling, parameter identification and simulation. Ph.D. thesis, University of Hawaii at Manoa, Honolulu, May 2012 (2012)
Lermusiaux, P.F., et al.: A future for intelligent autonomous ocean observing systems. J. Mar. Res. 75(6), 765–813 (2017)
Lerner, J., Wagner, D., Zweig, K.: Algorithmics of Large and Complex Networks: Design, Analysis, and Simulation, vol. 5515. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-02094-0
Lumpkin, R., Pazos, M.: Measuring surface currents with surface velocity program drifters: the instrument, its data, and some recent results. In: Lagrangian Analysis and Prediction of Coastal and Ocean Dynamics, pp. 39–67 (2007)
Mannarini, G., Pinardi, N., Coppini, G., Oddo, P., Iafrati, A.: VISIR-I: small vessels-least-time nautical routes using wave forecasts. Geosci. Model Dev. 9(4), 1597–1625 (2016)
Okubo, A.: Horizontal dispersion of floatable particles in the vicinity of velocity singularities such as convergences. In: Deep Sea Research and Oceanographic Abstracts, vol. 17, pp. 445–454. Elsevier (1970)
Petres, C., Pailhas, Y., Patron, P., Petillot, Y., Evans, J., Lane, D.: Path planning for autonomous underwater vehicles. IEEE Trans. Robot. 23(2), 331–341 (2007)
Pontryagin, L.S.: Mathematical Theory of Optimal Processes. Routledge, London (2018)
Roemmich, D., et al.: The Argo program: observing the global ocean with profiling floats. Oceanography 22(2), 34–43 (2009)
Russell, S., Norvig, P.: Artificial intelligence: a modern approach (2002)
Schneider, E., Stark, H.: Optimal steering of a smart active particle. arXiv preprint arXiv:1909.03243 (2019)
Sutton, R.S., Barto, A.G.: Reinforcement Learning: An Introduction. MIT Press, Cambridge (2018)
Techy, L.: Optimal navigation in planar time-varying flow: Zermelo’s problem revisited. Intell. Serv. Robot. 4(4), 271–283 (2011). https://doi.org/10.1007/s11370-011-0092-9
Weiss, J.: The dynamics of enstrophy transfer in two-dimensional hydrodynamics. Phys. D: Nonlinear Phenomena 48(2–3), 273–294 (1991)
Zermelo, E.: Über das navigationsproblem bei ruhender oder veränderlicher windverteilung. ZAMM-J. Appl. Math. Mech./Zeitschrift für Angewandte Mathematik und Mechanik 11(2), 114–124 (1931)
Acknowledgments
This project has received partial funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 882340). K.G. acknowledges funding from the Knut and Alice Wallenberg Foundation, Grant No. KAW 2014.0048, and Vetenskapsrådet, Grant No. 2018-03974. F.B acknowledges funding from the European Research Council under the European Union’s Horizon 2020 Framework Programme (No. FP/2014–2020) ERC Grant Agreement No. 739964 (COPMAT).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Buzzicotti, M., Biferale, L., Bonaccorso, F., Clark di Leoni, P., Gustavsson, K. (2021). Optimal Control of Point-to-Point Navigation in Turbulent Time Dependent Flows Using Reinforcement Learning. In: Baldoni, M., Bandini, S. (eds) AIxIA 2020 – Advances in Artificial Intelligence. AIxIA 2020. Lecture Notes in Computer Science(), vol 12414. Springer, Cham. https://doi.org/10.1007/978-3-030-77091-4_14
Download citation
DOI: https://doi.org/10.1007/978-3-030-77091-4_14
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-77090-7
Online ISBN: 978-3-030-77091-4
eBook Packages: Computer ScienceComputer Science (R0)