
Abstract
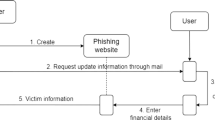
Current anti-phishing studies mainly focus on either detecting phishing pages or on identifying phishing emails sent to victims. In this paper, we propose instead to detect live attacks through the messages sent by the phishing site back to the attacker. Most phishing attacks exfiltrate the information gathered from the victim by sending an email to a “drop”, throwaway email address. We call these messages exfiltrating emails. Detecting and blocking exfiltrating emails is a new tool to protect networks in which a number of largely unmonitored websites are hosted (universities, web hosting companies etc.) and where phishing sites may be created, either directly or by compromising existing legitimate sites. Moreover, unlike most traditional antiphishing techniques which require a delay between the attack and its detection, this method is able to block the attack as soon as it starts collecting data.
It is also useful for email providers who can detect the presence of drop mailbox in their service and prevent access to it. Gmail deployed a simple rule-based detection system and detected over 12 million exfiltrating emails sent to more than 19,000 drop Gmail addresses in one year [52].
In this work, we look at this problem from a new perspective: we use a Recurrent Neural Network to learn the structure of exfiltrating emails instead of their content. We compare our implementation, called DeepPK, against word-based and pattern-based methods, and tested their robustness against evasion techniques. Although all three models are shown to be very effective at detecting unmodified messages, DeepPK is the overall more resistant and remains quite effective even when the messages are altered to avoid detection. With DeepPK, we also introduce a new message encoding technique which facilitates scaling of the classifier and makes detection evasion harder.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
Maybe because these are low-skill attacks, and some higher-skill attacks are evading our detection.
- 2.
Because these files do contain some sensitive data, we cannot publish this database as is. We will however make available the encoded version of the emails on which our deep learning algorithm works upon request and after verification.
- 3.
- 4.
- 5.
- 6.
- 7.
Here, a “positive” classification means that the message is flagged as exfiltrating email.
- 8.
Anecdotally, the more advanced technical steps that we regularly see in phishing kits are techniques to prevent returning visitors from submitting data again, presumably in an attempt to limit the amount of fake data submission.
- 9.
- 10.
- 11.
Our four categories, C, N, L and S, and the 10 digits, 0 to 9.
References
Abu-Nimeh, S., Nappa, D., Wang, X., Nair, S.: A comparison of machine learning techniques for phishing detection. In: Proceedings of the Anti-phishing Working Groups 2nd Annual eCrime Researchers Summit, pp. 60–69. ACM (2007)
Afroz, S., Greenstadt, R.: Phishzoo: detecting phishing websites by looking at them. In: 2011 Fifth IEEE International Conference on Semantic Computing (ICSC), pp. 368–375. IEEE (2011)
Al-Obeidat, F., El-Alfy, E.S.: Hybrid multicriteria fuzzy classification of network traffic patterns, anomalies, and protocols. Personal and Ubiquitous Computing, pp. 1–15 (2017)
Alshammari, R., Zincir-Heywood, A.N.: Machine learning based encrypted traffic classification: identifying SSH and skype. In: 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, pp. 1–8. IEEE (2009)
Anti-Phishing Working Group: Phishing Activity Trends Report 3rd Quarter in 2019. docs.apwg.org/reports/apwg_trends_report_q3_2019.pdf
Anti-Phishing Working Group: Phishing Activity Trends Report 4th Quarter in 2018. https://docs.apwg.org//reports/apwg_trends_report_q4_2018.pdf
Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014)
Behdad, M., Barone, L., Bennamoun, M., French, T.: Nature-inspired techniques in the context of fraud detection. IEEE Trans. Syst. Man Cybernet. Part C (Applications and Reviews) 42(6), 1273–1290 (2012)
Bengio, Y., Ducharme, R., Vincent, P., Jauvin, C.: A neural probabilistic language model. J. Mach. Learn. Res. 3, 1137–1155 (2003)
Blanzieri, E., Bryl, A.: A survey of learning-based techniques of email spam filtering. Artif. Intell. Rev. 29(1), 63–92 (2008)
Chandrasekaran, M., Narayanan, K., Upadhyaya, S.: Phishing email detection based on structural properties. In: NYS Cyber Security Conference, vol. 3. Albany, New York (2006)
Chang, E.H., Chiew, K.L., Sze, S.N., Tiong, W.K.: Phishing detection via identification of website identity. In: 2013 International Conference on IT Convergence and Security, ICITCS 2013, pp. 1–4. IEEE (2013)
Chen, T.C., Dick, S., Miller, J.: Detecting visually similar web pages: application to phishing detection. ACM Trans. Internet Technol. 10(2), 5:1–5:38 (2010)
Cho, K., et al.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078 (2014)
ClearSky Cyber Security: The Economy Behind the Phishing Websites Creation. https://www.clearskysec.com/wp-content/uploads/2017/08/The_Economy_behind_the_phishing_websites_-_White.pdf (2017)
Corona, I., et al.: DeltaPhish: detecting phishing webpages in compromised websites. In: Foley, S.N., Gollmann, D., Snekkenes, E. (eds.) ESORICS 2017. LNCS, vol. 10492, pp. 370–388. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-66402-6_22
Cui, Q.: Detection and Analysis of PhishingAttacks. Ph.D. thesis, University of Ottawa (2019)
Cui, Q., Jourdan, G.V., Bochmann, G.V., Couturier, R., Onut, I.V.: Tracking phishing attacks over time. In: Proceedings of the 26th International Conference on World Wide Web, pp. 667–676. International World Wide Web Conferences Steering Committee (2017)
Cui, Q., Jourdan, G.-V., Bochmann, G.V., Onut, I.-V., Flood, J.: Phishing attacks modifications and evolutions. In: Lopez, J., Zhou, J., Soriano, M. (eds.) ESORICS 2018. LNCS, vol. 11098, pp. 243–262. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-99073-6_12
EC-Council: How Strong is your Anti-Phishing Strategy? (2018). https://blog.eccouncil.org/how-strong-is-your-anti-phishing-strategy/
Elssied, N.O.F., Ibrahim, O., Abu-Ulbeh, W.: An improved of spam e-mail classification mechanism using k-means clustering. J. Theoret. Appl. Inf. Technol 60(3), 568–580 (2014)
Fette, I., Sadeh, N., Tomasic, A.: Learning to detect phishing emails. In: Proceedings of the 16th international conference on World Wide Web, pp. 649–656. ACM (2007)
Geng, G.G., Lee, X.D., Wang, W., Tseng, S.S.: Favicon - a clue to phishing sites detection. In: eCrime Researchers Summit (eCRS), pp. 1–10, September 2013
Gowtham, R., Krishnamurthi, I.: A comprehensive and efficacious architecture for detecting phishing webpages. Comput. Secur 40, 23–37 (2014)
Group, A.P.W.: Global Phishing Report 2H 2014 (2014). http://docs.apwg.org/reports/APWG_Global_Phishing_Report_2H_2014.pdf
A. Hamid, I.R., Abawajy, J.: Hybrid feature selection for phishing email detection. In: Xiang, Y., Cuzzocrea, A., Hobbs, M., Zhou, W. (eds.) ICA3PP 2011. LNCS, vol. 7017, pp. 266–275. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-24669-2_26
Han, X., Kheir, N., Balzarotti, D.: Phisheye: Live monitoring of sandboxed phishing kits. In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pp. 1402–1413. ACM (2016)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Hu, H., Wang, G.: End-to-end measurements of email spoofing attacks. In: 27th \(\{\)USENIX\(\}\) Security Symposium (\(\{\)USENIX\(\}\) Security 2018), pp. 1095–1112 (2018)
Husák, M., Čermák, M., Jirsík, T., Čeleda, P.: Https traffic analysis and client identification using passive SSL/TLS fingerprinting. EURASIP J. Inf. Secur. 2016(1), 6 (2016)
Imperva: Our Analysis of 1,019 Phishing Kits (2018). https://www.imperva.com/blog/our-analysis-of-1019-phishing-kits/
Liu, W., Liu, G., Qiu, B., Quan, X.: Antiphishing through phishing target discovery. IEEE Internet Comput. 16(2), 52–61 (2012)
Ludl, C., McAllister, S., Kirda, E., Kruegel, C.: On the effectiveness of techniques to detect phishing sites. In: M. Hämmerli, B., Sommer, R. (eds.) DIMVA 2007. LNCS, vol. 4579, pp. 20–39. Springer, Heidelberg (2007). https://doi.org/10.1007/978-3-540-73614-1_2
McCalley, H., Wardman, B., Warner, G.: Analysis of back-doored phishing kits. In: Peterson, G., Shenoi, S. (eds.) DigitalForensics 2011. IAICT, vol. 361, pp. 155–168. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-24212-0_12
Mikolov, T., Karafiát, M., Burget, L., Černockỳ, J., Khudanpur, S.: Recurrent neural network based language model. In: Eleventh Annual Conference of the International Speech Communication Association (2010)
Miyamoto, D., Hazeyama, H., Kadobayashi, Y.: An evaluation of machine learning-based methods for detection of phishing sites. In: Köppen, M., Kasabov, N., Coghill, G. (eds.) ICONIP 2008. LNCS, vol. 5506, pp. 539–546. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-02490-0_66
Mohammad, R.M., Thabtah, F., McCluskey, L.: mohammad2014. Neural Computi. Appl 25(2), 443–458 (2014)
Nadler, A., Aminov, A., Shabtai, A.: Detection of malicious and low throughput data exfiltration over the DNS protocol. Comput. Secur. 80, 36–53 (2019)
Oest, A., Safei, Y., Doupé, A., Ahn, G., Wardman, B., Warner, G.: Inside a phisher’s mind: Understanding the anti-phishing ecosystem through phishing kit analysis. In: 2018 APWG Symposium on Electronic Crime Research (eCrime), pp. 1–12, May 2018. https://doi.org/10.1109/ECRIME.2018.8376206
Pan, Y., Ding, X.: Anomaly based web phishing page detection. In: null. pp. 381–392. IEEE (2006)
Pérez-Díaz, N., Ruano-Ordas, D., Mendez, J.R., Galvez, J.F., Fdez-Riverola, F.: Rough sets for spam filtering: Selecting appropriate decision rules for boundary e-mail classification. Appl. Soft Comput. 12(11), 3671–3682 (2012)
PhishLabs: How to Fight Back against Phishing (2013). https://info.phishlabs.com/hs-fs/hub/326665/file-558105945-pdf/White_Papers/How_to_Fight_Back_Against_Phishing_-_White_Paper.pdf
Pitsillidis, A., et al.: Botnet judo: Fighting spam with itself. In: NDSS (2010)
Ramesh, G., Krishnamurthi, I., Kumar, K.S.S.: An efficacious method for detecting phishing webpages through target domain identification. Decis. Support Syst. 61(1), 12–22 (2014)
Rosiello, A.P.E., Kirda, E., Kruegel, C., Ferrandi, F.: A layout-similarity-based approach for detecting phishing pages. In: Proceedings of the 3rd International Conference on Security and Privacy in Communication Networks, SecureComm, pp. 454–463. Nice (2007)
Schuster, M., Paliwal, K.K.: Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 45(11), 2673–2681 (1997)
Shannon, C.E.: A mathematical theory of communication. Bell Syst. Tech. J. 27(3), 379–423 (1948)
Smadi, S., Aslam, N., Zhang, L., Alasem, R., Hossain, M.: Detection of phishing emails using data mining algorithms. In: 2015 9th International Conference on Software, Knowledge, Information Management and Applications (SKIMA), pp. 1–8. IEEE (2015)
Stringhini, G., Thonnard, O.: That ain’t you: blocking spearphishing through behavioral modelling. In: Almgren, M., Gulisano, V., Maggi, F. (eds.) DIMVA 2015. LNCS, vol. 9148, pp. 78–97. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-20550-2_5
Sundermeyer, M., Schlüter, R., Ney, H.: LSTM neural networks for language modeling. In: Thirteenth Annual Conference of the International Speech Communication Association (2012)
Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. In: Advances in Neural Information Processing Systems, pp. 3104–3112 (2014)
Thomas, K., et al.: Data breaches, phishing, or malware?: understanding the risks of stolen credentials. In: Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, pp. 1421–1434. ACM (2017)
Verma, R., Shashidhar, N., Hossain, N.: Detecting phishing emails the natural language way. In: Foresti, S., Yung, M., Martinelli, F. (eds.) ESORICS 2012. LNCS, vol. 7459, pp. 824–841. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33167-1_47
Whittaker, C., Ryner, B., Nazif, M.: Large-scale automatic classification of phishing pages. In: In Proceedings of the Network & Distributed System Security Symposium (NDSS 2010), San Diego, CA, pp. 1–14 (2010)
Xiang, G., Hong, J., Rose, C.P., Cranor, L.: Cantina+: a feature-rich machine learning framework for detecting phishing web sites. ACM Trans. Inf. Syst. Secur. 14(2), 21:1–21:28 (2011)
Xie, Y., Yu, F., Achan, K., Panigrahy, R., Hulten, G., Osipkov, I.: Spamming botnets: signatures and characteristics. ACM SIGCOMM Comput. Commun. Rev. 38(4), 171–182 (2008)
Zawoad, S., Dutta, A.K., Sprague, A., Hasan, R., Britt, J., Warner, G.: Phish-net: investigating phish clusters using drop email addresses. In: 2013 APWG eCrime Researchers Summit, pp. 1–13, September 2013. https://doi.org/10.1109/eCRS.2013.6805777
Zhang, H., Li, D.: Naïve Bayes text classifier. In: 2007 IEEE International Conference on Granular Computing (GRC 2007), p. 708. IEEE (2007)
Zhang, Y., Hong, J., Lorrie, C.: Cantina: a content-based approach to detecting phishing web sites. In: Proceedings of the 16th International Conference on World Wide Web, Banff, AB, pp. 639–648 (2007)
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Appendices
A Details About DeepPK
1.1 A.1 Structure Tokens
In order to compare the “structure” of the body of emails, we introduce what we call the structure token, which is a symbolic representation of that email structure. Formally, we encode the text of the message using four categories: letters ([a-zA-Z]), encoded as C, digits ([0–9]), encoded as N, line breaks ([\({\backslash }\)n\({\backslash }\)r]), encoded as L, and finally any character that does not belong to the previous categories, encoded as S. In addition, we count consecutive occurrences of characters in the same category and append the number of occurrences to the category symbol. For compactness, we do not append that number if it is 1. For instance, the text “Hi Yvonne\({\backslash }\)n This is John, please call me back.” is represented as the structure token “C2SC6LSC4SC2SC4S2C6SC4SC2SC4S” (where single instances of a category where the number 1 is omitted are underlined).
There are several advantages to using such a structure token. First, it does not capture the actual text (the words) used in the message, and instead captures the structure of the content. For instance, in the example above, if some words are changed (e.g., greetings or names are modified), we still get a similar structure token. The number of consecutive occurrences of a particular category might change a little bit when a word is changed, but the sequence of categories will remain relatively stable. This adds significant value in our context because in exfiltrating emails, what will change between messages is the part containing the victim’s data. The remaining content is the template, which doesn’t change across messages sent by the same phishing attack. Figure 2 shows two instances of the same template. The “template” part (separators, fields name, line breaks) remains identical in both messages, and the corresponding structure tokens will match. In addition, it is often the case that the structure token will still be quite similar across messages in the parts containing victim’s data. For instance, all IP addresses end up with the structure token “NXSNXSNXSNX” where X \(\in \) [‘’, 2, 3]. It is also true that using a structure token makes is more difficult for the attacker to evade detection, since it is not enough to modify the text of the template. A new template needs to be introduced to significantly change the structure token. Finally, last but not least, using a structure token insures that model learns patterns from one-way encoded inputs rather than directly from data containing sensitive information. This protects users data privacy both during training and at run time, since actual email content is never sent to the system.
But a very important practical consequence of using structure token instead of traditional encoding methods, such as using words as encoding units, is that our method uses a very small corpus containing only 14 symbolsFootnote 11 which allows our tokens to be applied to large datasets. In order to vectorize structure tokens, we apply the so-called “one-hot encoding”, which is a vector of bits of the same size as the encoding corpus, 14 bits in our case. Each bit corresponds to the index of one of the symbols in the corpus, and each character is being encoded with a vector in which only one bit is set to 1. As an example, given a corpus {a,b,c}, ‘a’ could be encoded [1, 0, 0], ‘b’ encoded [0, 1, 0] and ‘c’ encoded [0,0,1]. The one-hot encoding string of the text “aacb” would then be [[1, 0, 0], [1, 0, 0], [0, 0, 1], [0, 1, 0]].
1.2 A.2 Semantic Feature of Email
Our initial intent was to use only structure tokens to identify exfiltrating emails. However, we noticed that this resulted in a handful of false positives in the odd cases where regular emails follow a structure similar to exfiltrating emails. Figure 3 shows one such example.

One example of false positives
In order to correctly classify these messages, we enhance our method by introducing two “semantic” features: the content entropy and the text proportion.
Entropy is a commonly used metric in information theory. It measures the uncertainty of a piece of information produced by a source of data [47]. Formally, given a string S consisting of n characters {\(c_1,c_2,...,c_n\)} that are generated by a corpus of k unique symbols, the entropy of S, \(ent(S)=-\sum _{i=1}^{m}p(s_i)*log(p(s_i))\), where m is the number of symbols used in the string S, and \(p(s_i)\) is the probability of symbol \(s_i\) appearing in S. The higher the value of entropy, the more disordered or uncertain the string generated by the corpus. However, entropy has a tendency to generate greater values for the string that uses a large variety of symbols. In order to alleviate this tendency, we divide the initial number by the logarithm of the number of symbols in the string. Finally, we end up with a normalized entropy in the range [0,1]: \(ent_{normal}(s)=-\sum _{i=1}^{m}\frac{p(s_i)*log(p(s_i))}{log(m)}\).
In our case, we use the above normalized entropy and a corpus of 26 English letters ([a–z]) and 10 digits ([0–9]) to build what call the content entropy. Specifically, we first convert email text into lowercase. We then calculate the normalized entropy for the processed content and get the content entropy. Since a regular email is mainly composed of English words, which has a higher certainty than the content of an exfiltrating email (e.g. username and password), it yields a lower content entropy.
Another difference between exfiltrating emails and regular emails is that exfiltrating emails tend to use a greater proportion of non-numeric and non-letter symbols. In order to quantify this difference, we propose another context feature, the text proportion. Formally, given a string S consisting of n characters \(\{c_1,c_2,...,c_n\}\), the text proportion TP(S) is defined with the following formula:

As an example, the text proportions of the exfiltrating emails in Fig. 2 are 0.7065 (left) and 0.7097 (right), while the text proportion of the regular email in Fig. 3 is 0.7703, higher than Fig. 2.

LSTM cell and its unrolled form
1.3 A.3 Long Short-Term Memory Model
A Recurrent Neural Network (RNN) is a neural network where cells are connected in a round-robin fashion. Long Short-Term Memory (LSTM) is a type if RNN. As shown in Fig. 4, an LSTM cell has three inputs: \(X_{t}\), \(C_{t-1}\) and \(h_{t-1}\). \(X_{t}\) is the \(t^{th}\) character in the input sequence X. \(C_{t-1}\) is the state passed from the previous step, which stores the “memory” of what has been learned from the previous sequence. \(h_{t-1}\) is the output of the LSTM cell in the previous step, representing the latest prediction based on the previous sequence. The LSTM cell uses these values to calculate outputs, which are taken as the input in the next step.
Formally, \(C_t=f_t*C_{t-1} + i_t * \tilde{C_t}\), where \(f_t=\text {sigmoid}(W_f\cdot [h_{t-1}, x_t]+b_f)\), \(i_t=\text {sigmoid}(W_i\cdot [h_{t-1}, x_t]+b_i)\) and \(\tilde{C_t}=\tanh (W_C\cdot [h_{t-1}, x_t]+b_C)\). It can be seen that the new cell state \(C_t\) is equal to the partial previous status \(C_{t-1}\) plus the scaled update candidate \(\tilde{C_t}\), and controlled by two gating components \(f_t\) and \(i_t\), that are the functions of the current element \(x_t\) and the output in the previous step \(h_{t-1}\). In our context, these two gating components control the memory focus of the model during training: it keeps the memory of the key sequence and ignores the parts that do not contribute meaningful indicators for the model.
The output of the LSTM cell \(h_t\) is a function of the new cell state \(C_t\). Formally, \(h_t=o_t*\tanh (C_t)\), where \(o_t=\text {sigmoid}(W_o\cdot [h_{t-1}, x_t]+b_o)\). The gating component \(o_t\) controls the output scale of the cell status. In our context, \(h_t\) is a vector indicator that identifies whether the currently processed token comes from an exfiltrating email.

System design of DeepPK
Detection Model. In order to construct our detection model, we pass the structure token through the LSTM cell and combine the LSTM output in the final step with the content features to yield the final prediction. A problem with using a single LSTM cell is that the output of the LSTM cell in the final step may not provide complete information of email structure. To overcome this issue, we apply a variant of LSTM: the Bidirectional LSTM, which uses a reversed copy of the input sequence to train an additional LSTM cell. Therefore, the model is able to know the complete information of the input in both directions [46]. We call this detection model DeepPK. The complete overview is shown Fig. 5. Additional information about DeepPK’s parameters are provided Appendix A.4.
-
Preprocessing Model. When an email is classified, the first step is the preprocessing model. In this model, we first parse the text of the email body. If it is a HTML email, we scan all HTML tags and extract the text from each tag. We then generate the structure token and the semantic features based on the text content. Different message bodies yield structure tokens of different lengths. However, LSTM cell requires fixed-length input. By trial and error, we have selected a “reasonable” size as the input length (the details of the selection of the input length is discussed in the Appendix A.5). For the structure tokens that are longer than this input length, we use a tumbling window of the input length to create several non-overlapping token segments for that message. For the structure token that are shorter than the input length (or for the last token segment when several are created), we simply pad them with placeholders. Finally, the token segments are encoded into one-hot vectors and used as the input of our LSTM model.
-
Bidirectional LSTM. A Bidirectional LSTM model consists of two LSTM cells. The output of the forward LSTM cell (LSTM_output) and the backward LSTM cell (LSTM_reversed_output) are joint together with the semantic features to form a new feature vector, which is later used as the input of the sigmoid output layer to yield the final prediction. The output of Sigmoid indicates the probability that the given email is an exfiltrating email.
Training Stage and Testing Stage. As mentioned above, we use a tumbling window of the input length to split each message into multiple non-overlapping token segments, and pad the last one. During training, each token segment is treated as an individual ground-truth sample. In other words, the model only knows if the token segments are from exfiltrating emails and cannot link segments of the same message back together. On the test set, multiple token segments from the same message are treated as a complete identifier. A message is classified as exfiltrating email if and only if one of its token segments is detected as such.
Injection on Training Set. As discussed in Sect. A.3, the function of the LSTM cell is to extract and learn key structure tokens from exfiltrating emails. However, when the training set is not sufficiently diverse, the model may fail to learn useful token sequences and instead may only remember some sequence or symbols at a specific position. For instance, exfiltrating emails often contain some series of dashes at the beginning. As a consequence, the structure token of these exfiltrating emails starts with the symbol S. In contrast, regular emails normally start with greetings, so the structure token of most regular emails starts with C. If such a training set is used to train the model, it causes the model to only use the first symbol as a strong indicator of exfiltrating emails and ignore the subsequent sequence. It causes the model to be very vulnerable in practice because an attacker can easily fool it, e.g. by embedding the exfiltrating email into a regular email.
In order to solve this issue, we randomly inject structure token fragments of different lengths, that are sampled from regular emails. To prevent learning these injected fragments, we inject the fragments that are sampled from the regular training set.
1.4 A.4 Analysis of DeepPK
In this section, we discuss the impact of various parameters in DeepPK’s performance.
Our results are shown Fig. 6. In general, we can see that the precision increases but the recall decreases with the number of memory cells and the size of the input. The recall is still quite stable and stays above 99% across the board. The input length plays an important role: a shorter input allows the model to recognize more exfiltrating emails (higher recall), but increases the false positive rate. This indicates that the model requires enough structural information to accurately classify the messages.
The model is less sensitive to the number of memory units (the precision remains above 94% across the board). The model with 128 memory units and an input length of 600 yields the highest F1 score.

DeepPK performance with different parameters
1.5 A.5 Analysis of Structure Token Length
As discussed in Sect. A.3, we needed to select a “reasonable” length for the structure token, since the LSTM cell requires fixed-length input. A reasonable length is the length that is able to cover “enough” context for the model to learn the required information from the structure token. To determine that, we first look at the length distribution of the structure token length in the exfiltrating email database, as shown in the Fig. 7.

Distribution of structure token length in the phishing database
We can see that save a few instances that end up with a very long structure token, most exfiltrating tokens have fewer than 600 characters. Through manual inspection, we find that these instances with long structure tokens can be divided into two categories: one category comes from instances produced by a specific template that collects 70 fields, as shown in Fig. 8. It comes from a phishing attack targeting a Brazilian bank https://www.bradescoseguranca.com.br. The other category are instances of exfiltrating emails that are coming from end users that have attacked back the phishing site: in these messages, the fields are populated with extremely long dummy strings. We thus chose 600 as the input length for DeepPK, since this length can cover most exfiltrating emails. In fact, even for the instance that exceeds this length, the cropped part is often a repeat of the previous part.

Email template with long structure tag and its screenshot (In the actual exfiltration email, the data is where the “**” are in the figure.)

Performance comparison on injection attack test sets
B Model Robustness
Set-cover does not fare well at all against replacement attacks, because this attack removes the information that these models have learned.
The apparent success of the model NB and NB-windows against replacement attack is misleading. It is because in these attacks, the model does not recognize anything at all and ends up with a zero vector. Since the model can only provide 2 outputs (exfiltrating email or non exfiltrating emails), this simply indicates that our model happens to defaults to an “exfiltrating email” output when the input is completely unknown. It also indicates that this model would flag as “exfiltrating emails” any message for which it knows none of the word.
It is noted that the replacement attack test we conduct is very strict: each structure token fragment in the attack instance is totally different from the original one, which may rarely occur in practice. Our results show that even under this extreme test, DeepPK can still provide reasonable performances.

Performance comparison on replacement attack test sets
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Cui, Q., Jourdan, GV., Bochmann, G.V., Onut, IV. (2021). Proactive Detection of Phishing Kit Traffic. In: Sako, K., Tippenhauer, N.O. (eds) Applied Cryptography and Network Security. ACNS 2021. Lecture Notes in Computer Science(), vol 12727. Springer, Cham. https://doi.org/10.1007/978-3-030-78375-4_11
Download citation
DOI: https://doi.org/10.1007/978-3-030-78375-4_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-78374-7
Online ISBN: 978-3-030-78375-4
eBook Packages: Computer ScienceComputer Science (R0)