
Abstract
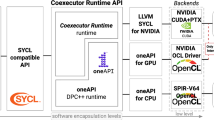
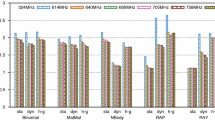
Programming efficiently heterogeneous systems is a major challenge, due to the complexity of their architectures. Intel oneAPI, a new and powerful standards-based unified programming model, built on top of SYCL, addresses these issues. In this paper, oneAPI is provided with co-execution strategies to run the same kernel between different devices, enabling the exploitation of static and dynamic policies. On top of that, static and dynamic load-balancing algorithms are integrated and analyzed. This work evaluates the performance and energy efficiency for a well-known set of regular and irregular HPC benchmarks, using an integrated GPU and CPU. Experimental results show that co-execution is worthwhile when using dynamic algorithms, improving efficiency even more when using unified shared memory.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Aktemur, B., Metzger, M., Saiapova, N., Strasuns, M.: Debugging sycl programs on heterogeneous architectures. In: International Workshop on OpenCL, IWOCL. ACM (2020)
Ashbaugh, B., et al.: Data parallel c++: Enhancing sycl through extensions for productivity and performance. In International Workshop on OpenCL, IWOCL. ACM (2020)
Beri, T., Bansal, S., Kumar, S.: The unicorn runtime: efficient distributed shared memory programming for hybrid cpu-gpu clusters. IEEE Trans. Parallel Distrib. Syst. 28(5), 1518–1534 (2017)
Castillo, E., Camarero, C., Borrego, A., Bosque, J.L.: Financial applications on multi-cpu and multi-gpu architectures. J. Supercomput. 71(2), 729–739 (2015)
Christgau, S., Steinke, T.: Porting a legacy cuda stencil code to oneapi. In: Proceedings of IPDPSW, pp. 359–367 (2020)
Constantinescu, D.A., Navarro, A.G., Corbera, F., Fernández-Madrigal, J.A., Asenjo, R.: Efficiency and productivity for decision making on low-power heterogeneous cpu+gpu socs. J. Supercomput. (2020)
Intel Corporation. Intel\(\textregistered \) oneAPI programming guide (2020)
Costero, L., Igual, F.D., Olcoz, K., Tirado, F.: Leveraging knowledge-as-a-service (kaas) for qos-aware resource management in multi-user video transcoding. J. Supercomput. 76(12), 9388–9403 (2020)
Farber, R.: Parallel Programming with OpenACC, 1st edn. Morgan Kaufmann Publishers, San Francisco (2016)
Gaster, B.R., Howes, L.W., Kaeli, D.R., Mistry, P., Schaa, D.: Heterogeneous Computing with OpenCL - Revised OpenCL 1.2 Edition. Morgan Kaufmann, San Francisco (2013)
Khronos\(\textregistered \) SYCL\(^{{\rm TM}}\) Working Group. SYCL\(^{{\rm TM}}\) specification: Generic heterogeneous computing for modern c++ (2020)
Jin, Z.: The rodinia benchmark suite in SYCL. Technical report, Argonne National Lab. (ANL), IL (United States) (2020)
Jin, Z., Morozov, V., Finkel, H.: A case study on the haccmk routine in sycl on integrated graphics. In: Proceedings of IPDPSW, pp. 368–374 (2020)
Lin, F.-C., Ngo, H.-H., Dow, C.-R.: A cloud-based face video retrieval system with deep learning. J. Supercomput. 76(11), 8473–8493 (2020). https://doi.org/10.1007/s11227-019-03123-x
Nozal, R., Bosque, J.L., Beivide, R.: Towards co-execution on commodity heterogeneous systems: Optimizations for time-constrained scenarios. In: 2019 International Conference on High Performance Computing & Simulation (HPCS), pp. 628–635. IEEE (2019)
Nozal, R., Bosque, J.L., Beivide, R.: Enginecl: usability and performance in heterogeneous computing. Fut. Gener. Comput. Syst. 107(C), 522–537 (2020)
Nozal, R., Perez, B., Bosque, J.L., Beivide, R.: Load balancing in a heterogeneous world: Cpu-xeon phi co-execution of data-parallel kernels. J. Supercomput. 75(3), 1123–1136 (2019)
Pérez, B., Bosque, J.L., Beivide, R.: Simplifying programming and load balancing of data parallel applications on heterogeneous systems. In: Proceedings of the 9th Workshop on General Purpose Processing using GPU, pp. 42–51 (2016)
Pérez, B., Stafford, E., Bosque, J.L., Beivide, R.: Energy efficiency of load balancing for data-parallel applications in heterogeneous systems. J. Supercomput. 73(1), 330–342 (2016). https://doi.org/10.1007/s11227-016-1864-y
Shen, J., Varbanescu, A.L., Lu, Y., Zou, P., Sips, H.: Workload partitioning for accelerating applications on heterogeneous platforms. IEEE Trans. Parallel Distrib. Syst. 27(9), 2766–2780 (2016)
Shin, W., Yoo, K.H., Baek, N.: Large-scale data computing performance comparisons on sycl heterogeneous parallel processing layer implementations. Appl. Sci. 10, 1656 (2020)
Toharia, P., Robles, O.D., Suárez, R., Bosque, J.L., Pastor, L.: Shot boundary detection using zernike moments in multi-gpu multi-cpu architectures. J. Parallel Distrib. Comput. 72(9), 1127–1133 (2012)
Vitali, E., Gadioli, D., Palermo, G., Beccari, A., Cavazzoni, C., Silvano, C.: Exploiting openmp and openacc to accelerate a geometric approach to molecular docking in heterogeneous HPC nodes. J. Supercomput. 75(7), 3374–3396 (2019)
Zahran, M.: Heterogeneous computing: here to stay. Commun. ACM 60(3), 42–45 (2017)
Zhang, F., Zhai, J., He, B., Zhang, S., Chen, W.: Understanding co-running behaviors on integrated cpu/gpu architectures. IEEE Trans. Parallel Distrib. Syst. 28(3), 905–918 (2017)
Acknowledgment
This work has been supported by the Spanish Ministry of Education (FPU16/ 03299 grant), the Spanish Science and Technology Commission under contract PID2019-105660RB-C22 and the European HiPEAC Network of Excellence.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Nozal, R., Bosque, J.L. (2021). Exploiting Co-execution with OneAPI: Heterogeneity from a Modern Perspective. In: Sousa, L., Roma, N., Tomás, P. (eds) Euro-Par 2021: Parallel Processing. Euro-Par 2021. Lecture Notes in Computer Science(), vol 12820. Springer, Cham. https://doi.org/10.1007/978-3-030-85665-6_31
Download citation
DOI: https://doi.org/10.1007/978-3-030-85665-6_31
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-85664-9
Online ISBN: 978-3-030-85665-6
eBook Packages: Computer ScienceComputer Science (R0)