
Abstract
The Arabic scripts raise numerous issues in text recognition and layout analysis. To overcome these, several datasets and methods have been proposed in recent years. Although the latter are focused on common scripts and layout, many Arabic writings and written traditions remain under-resourced. We therefore propose a new dataset comprising 300 images representative of the handwritten production of the Arabic Maghrebi scripts. This dataset is the achievement of a collaborative work undertaken in the first quarter of 2021, and it offers several levels of annotation and transcription. The article intends to shed light on the specificities of these writing and manuscripts, as well as highlight the challenges of the recognition. The collaborative tools used for the creation of the dataset are assessed and the dataset itself is evaluated with state of the art methods in layout analysis. The word-based text recognition method used and experimented on for these writings achieves CER of 4.8% on average. The pipeline described constitutes an experience feedback for the quick creation of data and the training of effective HTR systems for Arabic scripts and non-Latin scripts in general.
This work was carried out with the financial support of the French Ministry of Higher Education, Research and Innovation. It is in line with the scientific focus on digital humanities defined by the Research Consortium Middle-East and Muslim Worlds (GIS MOMM). We would also like to thank all the transcribers and people who took part in the hackathon and ensured its successful completion.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
The history and the origins of these scripts have been an important scientific open debate [3, 4]. The most recent works, in particular those of U. Bongianino, have foregrounded the different itineraries (from books to qurans, from al-Andalus to the Maghreb) followed by these writings between the 10th and the 13th century [4].
- 2.
- 3.
- 4.
The BULAC holds the second biggest fund of Arabic manuscripts in France (2.458 identified documentary units). BULAC collections contains a substantial proportion of the manuscripts copied in Maghrebi script. 150 Arabic manuscripts are available online on the website of the BINA Digital library.
- 5.
 – MS.ARA.1977, Collections patrimoniales numérisées de la BULAC.
– MS.ARA.1977, Collections patrimoniales numérisées de la BULAC. - 6.
Muḥammad b. Mubārak al-Barāšī is also the copyist of the second text. There is no mention for the third text: the paleographical characteristics of the pages lead us to assume that it is the work of another hand.
- 7.
 – MS.ARA.609, Collections patrimoniales numérisées de la BULAC.
– MS.ARA.609, Collections patrimoniales numérisées de la BULAC. - 8.
See bibliographic record on CALAMES.
- 9.
- 10.
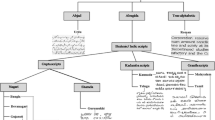
Numbering class is not kept in the v1.1 of the dataset, for which we notice a 9% gain in average for identification of catchword and table classes.
- 11.
With better polygons (dataset v1.1), the CER decreases more quickly (16.6 for batch 1, then 15.87, 13.67, 11.52, and finally 6.67 for the last batch).
 –
–  –
– References
Abdelhaleem, A., Droby, A., Asi, A., Kassis, M., Asam, R.A., El-sanaa, J.: WAHD: a database for writer identification of Arabic historical documents. In: 2017 1st International Workshop on Arabic Script Analysis and Recognition, pp. 64–68 (2017)
Adam, K., Baig, A., Al-Maadeed, S., Bouridane, A., El-Menshawy, S.: KERTAS: dataset for automatic dating of ancient Arabic manuscripts. Int. J. Doc. Anal. Recogn. (IJDAR) 21(4), 283–290 (2018). https://doi.org/10.1007/s10032-018-0312-3
Ben Azzouza, N.: Les corans de l’occident musulman médiéval : état des recherches et nouvelles perspectives. Perspectives 2, 104–130 (2017)
Bongianino, U.: The origins and developments of Maghribī rounds scripts, Arabic Paleography in the Islamic West (4th/10th-6th/12th centuries). Ph.D. thesis, University of Oxford (2017)
Camps, J.B., Vidal-Gorène, C., Vernet, M.: Handling heavily abbreviated manuscripts: HTR engines vs text normalisation approaches (2021). Accepted for IWCP workshop of ICDAR 2021
Clausner, C., Antonacopoulos, A., Mcgregor, N., Wilson-Nunn, D.: ICFHR 2018 competition on recognition of historical Arabic scientific manuscripts - RASM2018. In: 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), pp. 471–476 (2018)
Clérice, T.: Evaluating deep learning methods for word segmentation of Scripta Continua texts in old French and Latin. J. Data Min. Digit. Humanit. 2020 (2020). https://jdmdh.episciences.org/6264
Diem, M., Kleber, F., Sablatnig, R., Gatos, B.: cBAD: ICDAR2019 competition on baseline detection. In: 2019 International Conference on Document Analysis and Recognition (ICDAR), pp. 1494–1498 (2019)
Kassis, M., Abdalhaleem, A., Droby, A., Alaasam, R., El-Sana, J.: VML-HD: the historical Arabic documents dataset for recognition systems. In: 2017 1st International Workshop on Arabic Script Analysis and Recognition, pp. 11–14 (2017)
Kiessling, B., Ezra, D.S.B., Miller, M.T.: BADAM: a public dataset for baseline detection in Arabic-script manuscripts. In: Proceedings of the 5th International Workshop on Historical Document Imaging and Processing. HIP 2019, pp. 13–18. Association for Computing Machinery (2019)
Milo, T., Martínez, A.G.: A new strategy for Arabic OCR: archigraphemes, letter blocks, script grammar, and shape synthesis. In: Proceedings of the 3rd International Conference on Digital Access to Textual Cultural Heritage. DATeCH2019, pp. 93–96. Association for Computing Machinery, New York (2019)
Pantke, W., Dennhardt, M., Fecker, D., Märgner, V., Fingscheidt, T.: An historical handwritten Arabic dataset for segmentation-free word spotting - HADARA80P. In: 2014 14th International Conference on Frontiers in Handwriting Recognition, pp. 15–20 (2014)
Van Den Boogert, N.: Some notes on Maghribi script. Manuscripts Middle East 4, 30–43 (1989)
Vidal-Gorène, C., Dupin, B., Decours-Perez, A., Riccioli, T.: A modular and automated annotation platform for handwritings: evaluation on under-resourced languages (2021). Accepted for ICDAR 2021 Main Conference
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Vidal-Gorène, C., Lucas, N., Salah, C., Decours-Perez, A., Dupin, B. (2021). RASAM – A Dataset for the Recognition and Analysis of Scripts in Arabic Maghrebi. In: Barney Smith, E.H., Pal, U. (eds) Document Analysis and Recognition – ICDAR 2021 Workshops. ICDAR 2021. Lecture Notes in Computer Science(), vol 12916. Springer, Cham. https://doi.org/10.1007/978-3-030-86198-8_19
Download citation
DOI: https://doi.org/10.1007/978-3-030-86198-8_19
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-86197-1
Online ISBN: 978-3-030-86198-8
eBook Packages: Computer ScienceComputer Science (R0)
