
Abstract
A code smell is a surface indicator of an inherent problem in the system, most often due to deviation from standard coding practices on the developer’s part during the development phase. Studies observe that code smells made the code more susceptible to call for modifications and corrections than code that did not contain code smells. Restructuring the code at the early stage of development saves the exponentially increasing amount of effort it would require to address the issues stemming from the presence of these code smells. Instead of using traditional features to detect code smells, we use user comments (given on the packages’ repositories) to manually construct features to predict code smells. We use three Extreme learning machine kernels over 629 packages to identify eight code smells by leveraging feature engineering aspects and using sampling techniques. Our findings indicate that the radial basis functional kernel performs best out of the three kernel methods with a mean accuracy of 98.52.
H. Gupta and A. A. Gulanikar—The research associated to this paper was completed during author’s undergraduate study at BITS Pilani, Hyderabad Campus.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
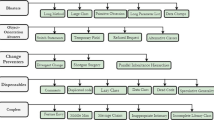


References
Van Emden, E., Moonen, L.: Java quality assurance by detecting code smells. In: 2002 Proceedings of the Ninth Working Conference on Reverse Engineering, pp. 97–106. IEEE (2002)
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P.: Smote: synthetic minority over-sampling technique. J. Artif. Intell. Res. 16, 321–357 (2002)
Han, H., Wang, W.-Y., Mao, B.-H.: Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. In: Huang, D.-S., Zhang, X.-P., Huang, G.-B. (eds.) ICIC 2005. LNCS, vol. 3644, pp. 878–887. Springer, Heidelberg (2005). https://doi.org/10.1007/11538059_91
Mathew, J., Luo, M., Pang, C.K., Chan, H.L.: Kernel-based smote for SVM classification of imbalanced datasets. In: IECON 2015–41st Annual Conference of the IEEE Industrial Electronics Society, pp. 001127–001132. IEEE (2015)
Ma, L., Zhang, Y.: Using Word2Vec to process big text data. In: 2015 IEEE International Conference on Big Data (Big Data), pp. 2895–2897. IEEE (2015)
Huang, G.-B., Zhu, Q.-Y., Siew, C.-K.: Extreme learning machine: theory and applications. Neurocomputing 70(1–3), 489–501 (2006)
Fernández-Navarro, F., Hervás-Martínez, C., Sanchez-Monedero, J., Gutiérrez, P.A.: MELM-GRBF: a modified version of the extreme learning machine for generalized radial basis function neural networks. Neurocomputing 74(16), 2502–2510 (2011)
Wang, Q., Luo, Z., Huang, J., Feng, Y., Liu, Z.: A novel ensemble method for imbalanced data learning: bagging of extrapolation-SMOTE SVM. Comput. Intell. Neurosci. 2017 (2017)
Wang, Q., Xu, J., Chen, H., He, B.: Two improved continuous bag-of-word models. In: 2017 International Joint Conference on Neural Networks (IJCNN), pp. 2851–2856. IEEE (2017)
Guthrie, D., Allison, B., Liu, W., Guthrie, L., Wilks, Y.: A closer look at skip-gram modelling. In: LREC, vol. 6, pp. 1222–1225. Citeseer (2006)
Micchelli, C.A., Pontil, M., Bartlett, P.: Learning the kernel function via regularization. J. Mach. Learn. Res. 6(7) (2005)
Prajapati, G.L., Patle, A.: On performing classification using SVM with radial basis and polynomial kernel functions. In: 2010 3rd International Conference on Emerging Trends in Engineering and Technology, pp. 512–515. IEEE (2010)
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Gupta, H., Gulanikar, A.A., Kumar, L., Neti, L.B.M. (2021). Empirical Analysis on Effectiveness of NLP Methods for Predicting Code Smell. In: Gervasi, O., et al. Computational Science and Its Applications – ICCSA 2021. ICCSA 2021. Lecture Notes in Computer Science(), vol 12957. Springer, Cham. https://doi.org/10.1007/978-3-030-87013-3_4
Download citation
DOI: https://doi.org/10.1007/978-3-030-87013-3_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-87012-6
Online ISBN: 978-3-030-87013-3
eBook Packages: Computer ScienceComputer Science (R0)