
Abstract
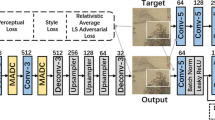
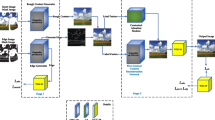
Most existing deep learning image inpainting methods cannot extract the effective information from broken images and reduce interference of masked partial information in broken images. To address this issue, we propose an image inpainting model based on a residual attention fusion block and a gated information distillation block. Our model adopts U-net as the backbone of the generator to realize the encoding and decoding operations of the image. The encoder and decoder employ the residual attention fusion block, which can enhance the utilization of practical information in the broken image and reduce the interference of redundant information. Moreover, we embed the gated information distillation block in the skip-connection of the encoder and decoder, which can further extract useful low-level features from the generator. Experiments on public databases show that our RAIDU-Net architecture achieves promising results and outperforms the existing state-of-the-art methods.
Supported by organization x.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Barnes, C., Shechtman, E., Finkelstein, A., Goldman, D.B.: PatchMatch: a randomized correspondence algorithm for structural image editing. ACM Trans. Graph. 28(3), 24 (2009)
Bertalmio, M., Sapiro, G., Caselles, V., Ballester, C.: Image inpainting. In: Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, pp. 417–424 (2000)
Doersch, C., Singh, S., Gupta, A., Sivic, J., Efros, A.: What makes Paris look like Paris? ACM Trans. Graph. 31(4) (2012)
Iizuka, S., Simo-Serra, E., Ishikawa, H.: Globally and locally consistent image completion. ACM Trans. Graph. (ToG) 36(4), 1–14 (2017)
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of GANs for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196 (2017)
Liu, G., Reda, F.A., Shih, K.J., Wang, T.C., Tao, A., Catanzaro, B.: Image inpainting for irregular holes using partial convolutions. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 85–100 (2018)
Liu, H., Jiang, B., Song, Y., Huang, W., Yang, C.: Rethinking image inpainting via a mutual encoder-decoder with feature equalizations. arXiv preprint arXiv:2007.06929 (2020)
Liu, H., Jiang, B., Xiao, Y., Yang, C.: Coherent semantic attention for image inpainting. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4170–4179 (2019)
Ma, Y., Liu, X., Bai, S., Wang, L., He, D., Liu, A.: Coarse-to-fine image inpainting via region-wise convolutions and non-local correlation. In: IJCAI, pp. 3123–3129 (2019)
Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T., Efros, A.A.: Context encoders: feature learning by inpainting. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2536–2544 (2016)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Yan, Z., Li, X., Li, M., Zuo, W., Shan, S.: Shift-Net: image inpainting via deep feature rearrangement. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 1–17 (2018)
Yang, H., Yu, Y.: Res2U-Net: image inpainting via multi-scale backbone and channel attention. In: Yang, H., Pasupa, K., Leung, A.C.-S., Kwok, J.T., Chan, J.H., King, I. (eds.) ICONIP 2020. LNCS, vol. 12532, pp. 498–508. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-63830-6_42
Yu, J., Lin, Z., Yang, J., Shen, X., Lu, X., Huang, T.S.: Generative image inpainting with contextual attention. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5505–5514 (2018)
Yu, J., Lin, Z., Yang, J., Shen, X., Lu, X., Huang, T.S.: Free-form image inpainting with gated convolution. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4471–4480 (2019)
Zeng, Y., Fu, J., Chao, H., Guo, B.: Learning pyramid-context encoder network for high-quality image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1486–1494 (2019)
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant No. 62166048, Grant No. 61263048 ) and by the Applied Basic Research Project of Yunnan Province (Grant No. 2018FB102).
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
He, P., Yu, Y., Xu, C., Yang, H. (2021). RAIDU-Net: Image Inpainting via Residual Attention Fusion and Gated Information Distillation. In: Mantoro, T., Lee, M., Ayu, M.A., Wong, K.W., Hidayanto, A.N. (eds) Neural Information Processing. ICONIP 2021. Lecture Notes in Computer Science(), vol 13108. Springer, Cham. https://doi.org/10.1007/978-3-030-92185-9_12
Download citation
DOI: https://doi.org/10.1007/978-3-030-92185-9_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-92184-2
Online ISBN: 978-3-030-92185-9
eBook Packages: Computer ScienceComputer Science (R0)