
Abstract
Various research initiatives have been reported regarding highly effective results for the text detection problem, which consists of detecting textual elements, such as words and phrases, in digital images. Text localization is an important step on very widely used mobile applications, for instance, on-the-go translations and recognition of text for the visually impaired. At the same time, edge computing is revolutionizing the way embedded systems are architected by moving complex processing and analysis to end devices (e.g., mobile and wearable devices). In this context, the development of lightweight networks that can be run in devices with restricted computing power and with a minimum latency as possible is essential to make plenty of mobile-oriented solutions feasible in practice. In this work, we investigate the use of efficient object detection networks to address this task, proposing the fusion of two lightweight neural network architectures, MobileNetV2 and Single Shot Detector (SSD), into our approach named MobText. As experimental results in the ICDAR’11 and ICDAR’13 datasets demonstrates that our solution yields the best trade-off between effectiveness and efficiency in terms of processing time, achieving the state-of-the-art results on the ICDAR’11 dataset with an F-measure of \(96.09\%\) and an average processing time of 464 ms on a smartphone device, over experiments executed on both dataset images and with images captured in real time from the portable device.
Part of the results presented in this work were obtained through the “Algoritmos para Detecção e Reconhecimento de Texto Multilíngue” project, funded by Samsung Eletrônica da Amazônia Ltda., under the Brazilian Informatics Law 8.248/91.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
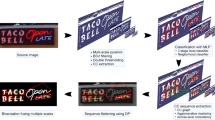


References
Abadi, M., et al.: Tensorflow: large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv:1603.04467 (2016)
Bengio, Y.: RMSprop and equilibrated adaptive learning rates for nonconvex optimization. Corr Abs/1502.04390 (2015)
Busta, M., Neumann, L., Matas, J.: FASText: efficient unconstrained scene text detector. In: IEEE International Conference on Computer Vision, pp. 1206–1214 (2015)
Córdova, M., et al.: Pelee-text: a tiny convolutional neural network for multi-oriented scene text detection. In: 18th IEEE International Conference on Machine Learning and Applications, Florida, FL, USA (2019)
Decker, L.G.L., et al.: MobText: a compact method for scene text localization. In: 15th International Joint Conference on Computer Vision. Imaging and Computer Graphics Theory and Applications, vol. 5, pp. 343–350. SciTePress, INSTICC (2020)
Deng, L., Yu, D.: Deep learning: methods and applications. Found. Trends® Signal Process. 7(3–4), 197–387 (2014)
Everingham, M., Eslami, S.M.A., Van Gool, L., Williams, C.K.I., Winn, J., Zisserman, A.: The pascal visual object classes challenge: a retrospective. Int. J. Comput. Vision 111(1), 98–136 (2015). https://doi.org/10.1007/s11263-014-0733-5
Everingham, M., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The pascal visual object classes (VOC) challenge. Int. J. Comput. Vision 88(2), 303–338 (2010). https://doi.org/10.1007/s11263-009-0275-4
Felzenszwalb, P.F., Huttenlocher, D.P.: Pictorial structures for object recognition. Int. J. Comput. Vision 61(1), 55–79 (2005). https://doi.org/10.1023/B:VISI.0000042934.15159.49
Flores Campana, J.L., Pinto, A., Alberto Córdova Neira, M., Gustavo Lorgus Decker, L., Santos, A., Conceição, J.S., da Silva Torres, R.: On the fusion of text detection results: a genetic programming approach. IEEE Access 8(1), 81257–81270 (2020)
Géron, A.: Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. O’Reilly Media, Sebastopol (2019)
Goodfellow, I., Bengio, Y., Courville, A.: Deep Learning. MIT Press, Cambridge (2016)
Gordo, A.: Supervised mid-level features for word image representation. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 2956–2964 (2015)
Gupta, A., Vedaldi, A., Zisserman, A.: Synthetic data for text localisation in natural images. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 2315–2324 (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
He, P., Huang, W., He, T., Zhu, Q., Qiao, Y., Li, X.: Single shot text detector with regional attention. In: IEEE International Conference on Computer Vision, pp. 3047–3055 (2017)
He, T., Huang, W., Qiao, Y., Yao, J.: Text-attentional convolutional neural network for scene text detection. IEEE Trans. Image Process. 25(6), 2529–2541 (2016)
Howard, A.G., et al.: MobileNets: efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017)
Karatzas, D., et al.: ICDAR 2015 competition on robust reading. In: 13th International Conference on Document Analysis and Recognition (ICDAR), pp. 1156–1160. IEEE (2015)
Karatzas, D., Mestre, S.R., Mas, J., Nourbakhsh, F., Roy, P.P.: ICDAR 2011 robust reading competition-challenge 1: reading text in born-digital images (web and email). In: International Conference on Document Analysis and Recognition, pp. 1485–1490. IEEE (2011)
Karatzas, D., et al.: ICDAR 2013 robust reading competition. In: 12th International Conference on Document Analysis and Recognition, pp. 1484–1493. IEEE (2013)
Koo, H.I., Kim, D.H.: Scene text detection via connected component clustering and nontext filtering. IEEE Trans. Image Process. 22(6), 2296–2305 (2013)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: Advances in Neural Information Processing Systems, pp. 1097–1105 (2012)
Kumuda, T., Basavaraj, L.: Hybrid approach to extract text in natural scene images. Int. J. Comput. Appl. 142(10), 1614–1618 (2016)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
Lee, J.J., Lee, P.H., Lee, S.W., Yuille, A., Koch, C.: AdaBoost for text detection in natural scene. In: International Conference on Document Analysis and Recognition, pp. 429–434. IEEE (2011)
Lee, S., Cho, M.S., Jung, K., Kim, J.H.: Scene text extraction with edge constraint and text collinearity. In: 20th International Conference on Pattern Recognition, pp. 3983–3986. IEEE (2010)
Lee, S., Kim, J.H.: Integrating multiple character proposals for robust scene text extraction. Image Vis. Comput. 31(11), 823–840 (2013)
Liao, M., Shi, B., Bai, X.: Textboxes++: a single-shot oriented scene text detector. IEEE Trans. Image Process. 27(8), 3676–3690 (2018)
Liao, M., Shi, B., Bai, X., Wang, X., Liu, W.: Textboxes: a fast text detector with a single deep neural network. In: Thirty-First AAAI Conference on Artificial Intelligence (2017)
Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 2117–2125 (2017)
Liu, W., et al.: SSD: single shot multibox detector. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9905, pp. 21–37. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_2
Lucas, S.M.: ICDAR 2005 text locating competition results. In: Eighth International Conference on Document Analysis and Recognition, pp. 80–84. IEEE (2005)
Lucas, S.M., Panaretos, A., Sosa, L., Tang, A., Wong, S., Young, R.: ICDAR 2003 robust reading competitions. In: Seventh International Conference on Document Analysis and Recognition, pp. 682–687. Citeseer (2003)
Matas, J., Chum, O., Urban, M., Pajdla, T.: Robust Wide-baseline stereo from maximally stable extremal regions. Image Vis. Comput. 22(10), 761–767 (2004)
McCulloch, W.S., Pitts, W.: A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 5(4), 115–133 (1943). https://doi.org/10.1007/BF02478259
Neubeck, A., Van Gool, L.: Efficient non-maximum suppression. In: 18th International Conference on Pattern Recognition, vol. 3, pp. 850–855. IEEE (2006)
Neumann, L., Matas, J.: On combining multiple segmentations in scene text recognition. In: 12th International Conference on Document Analysis and Recognition, pp. 523–527. IEEE (2013)
Pérez, P., Gangnet, M., Blake, A.: Poisson image editing. ACM Trans. Graph. 22, 313–318 (2003)
Quy Phan, T., Shivakumara, P., Tian, S., Lim Tan, C.: Recognizing text with perspective distortion in natural scenes. In: IEEE International Conference on Computer Vision, pp. 569–576 (2013)
Redmon, J., Farhadi, A.: Yolov3: an incremental improvement. arXiv preprint arXiv:1804.02767 (2018)
Rodriguez-Serrano, J.A., Perronnin, F., Meylan, F.: Label embedding for text recognition. In: British Machine Vision Conference, pp. 5–1 (2013)
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.: MobileNetV2: inverted residuals and linear bottlenecks. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 4510–4520 (2018)
Shi, C., Wang, C., Xiao, B., Zhang, Y., Gao, S., Zhang, Z.: Scene text recognition using part-based tree-structured character detection. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 2961–2968 (2013)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Tang, Y., Wu, X.: Scene text detection and segmentation based on cascaded convolution neural networks. IEEE Trans. Image Process. 26(3), 1509–1520 (2017)
Wang, K., Babenko, B., Belongie, S.: End-to-end scene text recognition. In: International Conference on Computer Vision, pp. 1457–1464. IEEE (2011)
Wang, L., Wang, Z., Qiao, Y., Van Gool, L.: Transferring deep object and scene representations for event recognition in still images. Int. J. Comput. Vision 126(2–4), 390–409 (2018). https://doi.org/10.1007/s11263-017-1043-5
Wang, R.J., Li, X., Ling, C.X.: Pelee: a real-time object detection system on mobile devices. In: Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R. (eds.) Advances in Neural Information Processing Systems, vol. 31, pp. 1967–1976. Curran Associates, Inc. (2018)
Wu, B., Iandola, F., Jin, P.H., Keutzer, K.: SqueezeDet: unified, small, low power fully convolutional neural networks for real-time object detection for autonomous driving. In: IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 129–137 (2017)
Yan, C., Xie, H., Liu, S., Yin, J., Zhang, Y., Dai, Q.: Effective uyghur language text detection in complex background images for traffic prompt identification. IEEE Trans. Intell. Transp. Syst. 19(1), 220–229 (2017)
Yao, C., Bai, X., Shi, B., Liu, W.: Strokelets: a learned multi-scale representation for scene text recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 4042–4049 (2014)
Ye, Q., Gao, W., Wang, W., Zeng, W.: A robust text detection algorithm in images and video frames. In: Fourth International Conference on Information, Communications and Signal Processing and the Fourth Pacific Rim Conference on Multimedia, vol. 2, pp. 802–806. IEEE (2003)
Yi, C., Tian, Y., Arditi, A.: Portable camera-based assistive text and product label reading from hand-held objects for blind persons. IEEE/ASME Trans. Mechatron. 19(3), 808–817 (2013)
Zhang, Z., Zhang, C., Shen, W., Yao, C., Liu, W., Bai, X.: Multi-oriented text detection with fully convolutional networks. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 4159–4167 (2016)
Zhu, Y., Liao, M., Yang, M., Liu, W.: Cascaded segmentation-detection networks for text-based traffic sign detection. IEEE Trans. Intell. Transp. Syst. 19(1), 209–219 (2017)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 Springer Nature Switzerland AG
About this paper

Cite this paper
Decker, L.G.L. et al. (2022). Scene Text Localization Using Lightweight Convolutional Networks. In: Bouatouch, K., et al. Computer Vision, Imaging and Computer Graphics Theory and Applications. VISIGRAPP 2020. Communications in Computer and Information Science, vol 1474. Springer, Cham. https://doi.org/10.1007/978-3-030-94893-1_13
Download citation
DOI: https://doi.org/10.1007/978-3-030-94893-1_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-94892-4
Online ISBN: 978-3-030-94893-1
eBook Packages: Computer ScienceComputer Science (R0)