
Abstract
Dependency parsing can enhance the performance of Named Entity Recognition (NER) models and can be leveraged to boost information extraction. NER tasks are essential to deal with clinical narratives, but models for Brazilian Portuguese dependency parsing are scarce, even less for clinical texts and its specificities. This paper reports on the development of a treebank of clinical narratives in Brazilian Portuguese and the drafting of guidelines. Based on a corpus of 1,000 clinical narratives manually annotated with semantic information, split into 12,711 sentences, we identified some characteristics of these texts that differ from traditional domains and have a deep impact on the annotation process, such as extensive use of acronyms and abbreviations, words not recognized by POS taggers, misspelling, special use of some symbols, different uses for numerals, heterogeneity of sentence sizes, and coordinated phrases without any punctuation. We developed a document to describe the annotation types and to explain how difficult cases should be treated to ensure consistency, including examples that could be found in this kind of texts. We created a Tag versus Frequency relation to justify some of the characteristics and challenges of the corpus. The corpus when completely annotated will be made available to the entire scientific community that performs research with clinical texts.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
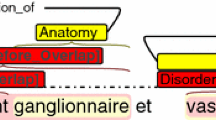


Notes
- 1.
The use of SemClinBr texts was approved by the Ethics Committee in Research (CEP) of PUCPR, under register no. 1,354,675.
- 2.
- 3.
- 4.
References
Bretonnel Cohen, K., Demner-Fushman, D.: Biomedical Natural Language Processing. John Benjamins (2014). https://www.jbe-platform.com/content/books/9789027271068
Dalianis, H.: Basic building blocks for clinical text processing. In: Clinical Text Mining, pp. 55–82. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-78503-5_7
Dalianis, H., Hassel, M., Henriksson, A., Skeppstedt, M.: Stockholm EPR corpus: a clinical database used to improve health care. In: Swedish Language Technology Conference, pp. 17–18 (2012)
Hao, T., Rusanov, A., Boland, M.R., Weng, C.: Clustering clinical trials with similar eligibility criteria features. J. Biomed. Inf. 52, 112–120 (2014)
Jiang, Z., Zhao, F., Guan, Y.: Developing a linguistically annotated corpus of Chinese electronic medical record. In: 2014 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pp. 307–310. IEEE (2014)
Lopes, F., Teixeira, C.A., Oliveira, H.G.: Contributions to clinical named entity recognition in Portuguese. In: BioNLP@ACL (2019)
Meystre, S.M., Savova, G.K., Kipper-Schuler, K.C., Hurdle, J.F.: Extracting information from textual documents in the electronic health record: a review of recent research. Yearbook of Med. Inf. 17(01), 128–144 (2008)
Névéol, A., Dalianis, H., Velupillai, S., Savova, G., Zweigenbaum, P.: Clinical natural language processing in languages other than english: opportunities and challenges. J. Biomed. Semantics 9(1), 1–13 (2018)
Ogren, P.V., Savova, G.K., Chute, C.G., et al.: Constructing evaluation corpora for automated clinical named entity recognition. In: LREC, vol. 8, pp. 3143–3150 (2008)
Oinam, N., Mishra, D., Patel, P., Choudhary, N., Desai, H.: A treebank for the healthcare domain. In: Proceedings of the Joint Workshop on Linguistic Annotation, Multiword Expressions and Constructions (LAW-MWE-CxG-2018), pp. 144–155 (2018)
Oliveira, L., et al.: Semclinbr-a multi institutional and multi specialty semantically annotated corpus for Portuguese clinical NLP tasks. In: CoRR (2020)
Oliveira, L.E.S., de Souza, A.C., Nohama, P., Moro, C.M.C.: A novel method for identifying continuity of care in hospital discharge summaries. In: Zhang, Y.-T. (ed.) The International Conference on Health Informatics. IP, vol. 42, pp. 284–287. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-03005-0_72
de Oliveira, L.F.A., e Oliveira, L.E.S., Gumiel, Y.B., Carvalho, D.R., Moro, C.M.C.: Defining a state-of-the-art POS-tagging environment for Brazilian Portuguese clinical texts. Res. Biomed. Eng. 36(3), 267–276 (2020). https://doi.org/10.1007/s42600-020-00067-7
Pakhomov, S.V., Coden, A., Chute, C.G.: Developing a corpus of clinical notes manually annotated for part-of-speech. Int. J. Med. Inf. 75(6), 418–429 (2006)
Percha, B.: Modern clinical text mining: a guide and review. Ann. Rev. Biomed. Data Sci. 4(1), 165–187 (2021). https://doi.org/10.1146/annurev-biodatasci-030421-030931, pMID: 34465177
Qi, P., Zhang, Y., Zhang, Y., Bolton, J., Manning, C.D.: Stanza: a Python natural language processing toolkit for many human languages. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations (2020). https://nlp.stanford.edu/pubs/qi2020stanza.pdf
Schneider, E.T.R., et al.: BioBERTpt - a Portuguese neural language model for clinical named entity recognition. In: Proceedings of the 3rd Clinical Natural Language Processing Workshop, pp. 65–72. Association for Computational Linguistics, November 2020. https://doi.org/10.18653/v1/2020.clinicalnlp-1.7, https://aclanthology.org/2020.clinicalnlp-1.7
Tateisi, Y., Tsujii, J.: Part-of-speech annotation of biology research abstracts. In: LREC (2004)
Wu, S.T., Liu, H., Li, D., Tao, C., Musen, M.A., Chute, C.G., Shah, N.H.: Unified medical language system term occurrences in clinical notes: a large-scale corpus analysis. J. Am. Med. Inf. Assoc. 19(e1), e149–e156 (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 Springer Nature Switzerland AG
About this paper

Cite this paper
de Oliveira, L.F.A., Pagano, A., e Oliveira, L.E.S., Moro, C. (2022). Challenges in Annotating a Treebank of Clinical Narratives in Brazilian Portuguese. In: Pinheiro, V., et al. Computational Processing of the Portuguese Language. PROPOR 2022. Lecture Notes in Computer Science(), vol 13208. Springer, Cham. https://doi.org/10.1007/978-3-030-98305-5_9
Download citation
DOI: https://doi.org/10.1007/978-3-030-98305-5_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-98304-8
Online ISBN: 978-3-030-98305-5
eBook Packages: Computer ScienceComputer Science (R0)