
Abstract
Recent achievements of AlphaZero using self-play has shown remarkable performance on several board games. It is plausible to think that self-play, starting from zero knowledge, can gradually approximate a winning strategy for certain two-player games after an amount of training. In this paper, we present a proof-of-concept to solve small instances of Quantified Boolean Formula Satisfaction (QSAT) problems by leveraging the computational power from neural Monte Carlo Tree Search (neural MCTS). QSAT is a PSPACE-complete problem with many practical applications. We propose a way to encode Quantified Boolean Formulas (QBFs) as graphs and apply a graph neural network (GNN) to embed the QBFs into the neural MCTS. After training, an off-the-shelf QSAT solver is used to evaluate the performance of the algorithm. Our result shows that, for problems within a limited size, the algorithm learns to solve the problem correctly merely from self-play. It is impressive that neural MCTS is succeeding on small QSAT problems but research is needed to better understand the algorithm and its parameters.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
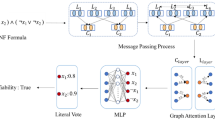

Notes
- 1.
There are two ways to interpret this acronym: 1) the Polynomial Upper Confidence Tree [2], as the exploration term under the square root is polynomial. (it usually was a logarithmic function in other UCB formulas); 2) the Predictor Upper Confidence Tree [15] because the probability prediction from the neural network is used to penalize the exploration term.
- 2.
Theoretically, the exploratory term should be \(\sqrt{\frac{\sum _{a'}N(s_{i-1},a')}{N(s_{i-1},a)+1}}\), however, AlphaZero used the variant \(\frac{\sqrt{\sum _{a'} N(s_{i-1},a')}}{N(s_{i-1},a)+1}\) without any explanation. We tried both in our implementation, and it turns out that the AlphaZero one performs much better.
- 3.
The reason why we treat the two players asymmetrically is that our graph encoding of the QBF based on the CNF of the matrix. Therefore, a negation of the matrix will result in a different CNF, which will change the encoding.
References
Anthony, T., Tian, Z., Barber, D.: Thinking fast and slow with deep learning and tree search. In: Advances in Neural Information Processing Systems, pp. 5360–5370 (2017)
Auger, D., Couëtoux, A., Teytaud, O.: Continuous upper confidence trees with polynomial exploration – consistency. In: Blockeel, H., Kersting, K., Nijssen, S., Železný, F. (eds.) ECML PKDD 2013. LNCS (LNAI), vol. 8188, pp. 194–209. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-40988-2_13
Battaglia, P.W., et al.: Relational inductive biases, deep learning, and graph networks (2018). arXiv preprint arXiv:1806.01261
Bjornsson, Y., Finnsson, H.: Cadiaplayer: a simulation-based general game player. IEEE Trans. Comput. Intell. AI Games 1(1), 4–15 (2009)
Browne, C., et al.: A survey of monte carlo tree search methods. IEEE Trans. Comput. Intell. AI Games 4(1), 1–43 (2012)
Genesereth, M., Love, N., Pell, B.: General game playing: overview of the AAAI competition. AI Mag. 26(2), 62–62 (2005)
Gilmer, J., Schoenholz, S.S., Riley, P.F., Vinyals, O., Dahl, G.E.: Neural message passing for quantum chemistry. In: Proceedings of the 34th International Conference on Machine Learning, vol. 70, pp. 1263–1272 (2017), JMLR. org
Janota, M.: Towards generalization in QBF solving via machine learning. In: Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, AAAI 2018, pp. 6607–6614 (2018)
Janota, M., Klieber, W., Marques-Silva, J., Clarke, E.: Solving QBF with counterexample guided refinement. In: Cimatti, A., Sebastiani, R. (eds.) SAT 2012. LNCS, vol. 7317, pp. 114–128. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-31612-8_10
Kauers, M., Seidl, M.: Symmetries of quantified boolean formulas (2018). arXiv, abs/1802.03993,
Kleinberg, J., Tardos, E.: Algorithm Design. Addison-Wesley Longman Publishing Co. Inc., Boston (2005)
Klieber, W., Sapra, S., Gao, S., Clarke, E.: A non-prenex, non-clausal QBF solver with game-state learning. In: Strichman, O., Szeider, S. (eds.) SAT 2010. LNCS, vol. 6175, pp. 128–142. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-14186-7_12
Li, Y., Tarlow,D., Brockschmidt, M., Zemel, R.S.: Gated graph sequence neural networks. In: 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016, Conference Track Proceedings (2016)
Rezende, M., Chaimowicz, L.: A methodology for creating generic game playing agents for board games. In: 2017 16th Brazilian Symposium on Computer Games and Digital Entertainment, SBGames, pp. 19–28. IEEE (2017)
Rosin, C.D.: Multi-armed bandits with episode context. Ann. Math. Artif. Intell. 61(3), 203–230 (2011)
Selsam, D., Lamm, M., Bunz, B., Liang, P., de Moura, L., Dill, D.L.: Learning a sat solver from single-bit supervision (2018). arXiv preprint, arXiv:1802.03685
Silver, D., et al.: Mastering the game of Go with deep neural networks and tree search. Nature 529, 484 (2016)
Silver, D., et al.: A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science 362(6419), 1140–1144 (2018)
Silver, D.: Mastering chess and shogi by self-play with a general reinforcement learning algorithm (2017). CoRR, abs/1712.01815
Silver, D., et al.: Mastering the game of Go without human knowledge. Nature 550, 354 (2017)
Xu, R., Lieberherr, K.: Learning self-game-play agents for combinatorial optimization problems. In: Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS 2019, pp. 2276–2278. IFAAMS (2019)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Xu, R., Lieberherr, K. (2022). Towards Tackling QSAT Problems with Deep Learning and Monte Carlo Tree Search. In: Arai, K. (eds) Intelligent Computing. SAI 2022. Lecture Notes in Networks and Systems, vol 507. Springer, Cham. https://doi.org/10.1007/978-3-031-10464-0_4
Download citation
DOI: https://doi.org/10.1007/978-3-031-10464-0_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-10463-3
Online ISBN: 978-3-031-10464-0
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)