
Abstract
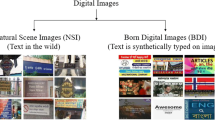
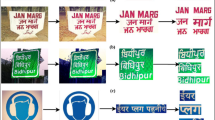
Understanding multi-lingual texts in any digital image calls for identifying the corresponding languages of the localized texts. India houses a multi-lingual ambience which necessitates the pursuit of an efficient model that is robust against various complexities and successfully identifies the language of Indic texts. This paper presents a deep learning based Convolutional Neural Network (CNN) model having an hour-glass like structure, for classifying texts in popular Indic languages like Bangla, English and Hindi. A new dataset, called Indic Texts in Digital Images (ITDI), is also presented which is a collection of text images, both scene and born-digital, written in Bangla, English and Hindi. The performance of the hour-glass CNN is evaluated upon standard Indic dataset like AUTNT giving an accuracy of 90.93% which is higher than most state-of-the-art models. The proposed model is also used to benchmark the performance on ITDI dataset with a reasonable accuracy of 85.18%. Sample instances of the proposed ITDI dataset can be found at: https://github.com/NCJUCSE/ITDI
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Joan, S.F., Valli, S.: A survey on text information extraction from born-digital and scene text images. Proc. Nat. Acad. Sci. India Sec. A Phys. Sci. 89(1), 77–101 (2019)
Kanagarathinam, K., Sekar, K.: Text detection and recognition in raw image dataset of seven segment digital energy meter display. Energy Rep. 5, 842–852 (2019)
Saha, S., Chakraborty, N., Kundu, S., Paul, S., Mollah, A.F., Basu, S., Sarkar, R.: Multi-lingual scene text detection and language identification. Pattern Recogn. Lett. 138, 16–22 (2020)
Chakraborty, N., Chatterjee, A., Singh, P.K., Mollah, A.F., Sarkar, R.: Application of daisy descriptor for language identification in the wild. Multimedia Tools Appl. 80(1), 323–344 (2021)
Long, S., He, X., Yao, C.: Scene text detection and recognition: the deep learning era. Int. J. Comput. Vis. 129(1), 161–184 (2021)
Melekhov, I., Ylioinas, J., Kannala, J., Rahtu, E.: Image-based localization using hourglass networks. In: Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 879–886 (2017)
Liu, S., Shang, Y., Han, J., Wang, X., Gao, H., Liu, D.: Multi-lingual scene text detection based on fully convolutional networks. In: Pacific Rim Conference on Multimedia, pp. 423–432. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-77380-3_40
Khan, T., Mollah, A.F.: AUTNT-A component level dataset for text non-text classification and benchmarking with novel script invariant feature descriptors and D-CNN. Multimedia Tools Appl. 78(22), 32159–32186 (2019)
Khan, T., Mollah, A.F.: Component-level script classification benchmark with CNN on AUTNT Dataset. In: Bhattacharjee, D., Kole, D.K., Dey, N., Basu, S., Plewczynski, D. (eds.) Proceedings of International Conference on Frontiers in Computing and Systems and Computing, vol. 1255, pp. 225–234. Springer, Singapore (2021). https://doi.org/10.1007/978-981-15-7834-2_21
Cheng, C., Huang, Q., Bai, X., Feng, B., Liu, W.: Patch aggregator for scene text script identification. In: 2019 International Conference on Document Analysis and Recognition (ICDAR), pp. 1077–1083. IEEE (2019)
Chakraborty, N., Kundu, S., Paul, S., Mollah, A.F., Basu, S., Sarkar, R.: Language identification from multi-lingual scene text images: a CNN based classifier ensemble approach. J. Ambient Intell. Hum. Comput. 12, 7997–8008 (2020)
Jajoo, M., Chakraborty, N., Mollah, A.F., Basu, S., Sarkar, R.: Script identification from camera-captured multi-script scene text components. In: Kalita, J., Balas, V., Borah, S., Pradhan, R. (eds.) Recent Developments in Machine Learning and Data Analytics. Advances in Intelligent Systems and Computing, vol. 740, pp. 159–166. Springer, Singapore (2019). https://doi.org/10.1007/978-981-13-1280-9_16
Lu, L., Yi, Y., Huang, F., Wang, K., Wang, Q.: Integrating local CNN and global CNN for script identification in natural scene images. IEEE Access 7, 52669–52679 (2019)
Mei, J., Dai, L., Shi, B., Bai, X.: Scene text script identification with convolutional recurrent neural networks. In: 2016 23rd International Conference on Pattern Recognition (ICPR), pp. 4053–4058. IEEE (2016)
Fujii, Y., Driesen, K., Baccash, J., Hurst, A., Popat, A. C.: Sequence-to-label script identification for multilingual ocr. In: 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), vol. 1, pp. 161–168. IEEE (2017)
Chollet, F.: Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1251–1258 (2017)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv:1412.6980 (2014)
Acknowledgements
This work is partially supported by the CMATER research laboratory of the Computer Science and Engineering Department, Jadavpur University, India.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Chakraborty, N., Mollah, A.F., Basu, S., Sarkar, R. (2022). An Hour-Glass CNN for Language Identification of Indic Texts in Digital Images. In: Raman, B., Murala, S., Chowdhury, A., Dhall, A., Goyal, P. (eds) Computer Vision and Image Processing. CVIP 2021. Communications in Computer and Information Science, vol 1568. Springer, Cham. https://doi.org/10.1007/978-3-031-11349-9_3
Download citation
DOI: https://doi.org/10.1007/978-3-031-11349-9_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-11348-2
Online ISBN: 978-3-031-11349-9
eBook Packages: Computer ScienceComputer Science (R0)