
Abstract
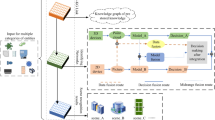
Object-oriented navigation in unknown environments with only vision as input has been a challenging task for autonomous robots. Introducing semantic knowledge into the model has been proved to be an effective means to improve the suboptimal performance and the generalization of existing end-to-end learning methods. In this paper, we improve object-oriented navigation by proposing a knowledge-enhanced scene context embedding method, which consists of a reasonable knowledge graph and a designed novel 6-D context vector. The developed knowledge graph (named MattKG) is derived from large-scale real-world scenes and contains object-level relationships that are expected to assist robots to understand the environment. The designed novel 6-D context vector replaces traditional pixel-level raw features by embedding observations as scene context. The experimental results on the public dataset AI2-THOR indicate that our method improves both the navigation success rate and efficiency compared with other state-of-the-art models. We also deploy the proposed method on a physical robot and apply it to the real-world environment.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Taheri, H., Xia, Z.C.: Slam; definition and evolution. Eng. Appl. Artif. Intell. 97, 104032 (2021)
Thrun, S.: Learning metric-topological maps for indoor mobile robot navigation. Artif. Intell. 99(1), 21–71 (1998)
Zhu, Y., et al.: Target-driven visual navigation in indoor scenes using deep reinforcement learning. In: 2017 IEEE International Conference on Robotics and Automation (ICRA), pp. 3357–3364. IEEE (2017)
Maillot, N.E., Thonnat, M.: Ontology based complex object recognition. Image Vis. Comput. 26(1), 102–113 (2008)
Serrano, S.A., Santiago, E., Martinez-Carranza, J., Morales, E.F., Sucar, L.E.: Knowledge-based hierarchical pomdps for task planning. J. Intell. Rob. Syst. 101(4), 1–30 (2021)
Marino, K., Chen, X., Parikh, D., Gupta, A., Rohrbach, M.: Krisp: integrating implicit and symbolic knowledge for open-domain knowledge-based vqa. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14111–14121 (2021)
Ran, T., Yuan, L., Zhang, J.: Scene perception based visual navigation of mobile robot in indoor environment. ISA Trans. 109, 389–400 (2021)
Wortsman, M., Ehsani, K., Rastegari, M., Farhadi, A., Mottaghi, R.: Learning to learn how to learn: self-adaptive visual navigation using meta-learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6750–6759 (2019)
Zeng, Z., R ̈ofer, A., Jenkins, O.C.: Semantic linking maps for active visual object search. In: 2020 IEEE International Conference on Robotics and Automation (ICRA), pp. 1984–1990. IEEE (2020)
Chaplot, D.S., Gandhi, D.P., Gupta, A., Salakhutdinov, R.R.: Object goal navigation using goal-oriented semantic exploration. Adv. Neural. Inf. Process. Syst. 33, 4247–4258 (2020)
Yang, W., Wang, X., Farhadi, A., Gupta, A., Mottaghi, R.: Visual semantic navigation using scene priors. arXiv preprint arXiv:1810.06543 (2018)
Qiu, Y., Pal, A., Christensen, H.I.: Learning hierarchical relationships for object-goal navigation. arXiv preprint arXiv:2003.06749 (2020)
Chang, A., et al.: Matterport3d: learning from rgb-d data in indoor environments. arXiv preprint arXiv:1709.06158 (2017)
Kolve, E., et al.: Ai2-thor: An interactive 3D environment for visual ai. arXiv preprint arXiv:1712.05474 (2017)
Mnih, V., et al.: Asynchronous methods for deep reinforcement learning. In: International Conference on Machine Learning, pp. 1928–1937. PMLR (2016)
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 28 (2015)
Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016)
Pennington, J., Socher, R., Manning, C.D.: Glove: global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1532–1543 (2014)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, pp. 770–778 (2016)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Acknowledgments
This work was partially supported by the National Natural Science Foundation of China (52172376), the Young Scientists Fund of the National Natural Science Foundation of China (52002013), the China Postdoctoral Science Foundation (BX20200036, 2020M680298) and the Project Fund of the GENERAL ADMINISTRATION OF CUSTOMS.P.R.CHINA (2021HK261).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Li, Y., Xiao, N., Huo, X., Wu, X. (2022). Knowledge-Enhanced Scene Context Embedding for Object-Oriented Navigation of Autonomous Robots. In: Liu, H., et al. Intelligent Robotics and Applications. ICIRA 2022. Lecture Notes in Computer Science(), vol 13455. Springer, Cham. https://doi.org/10.1007/978-3-031-13844-7_1
Download citation
DOI: https://doi.org/10.1007/978-3-031-13844-7_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-13843-0
Online ISBN: 978-3-031-13844-7
eBook Packages: Computer ScienceComputer Science (R0)