
Abstract
Automatic résumé matching for the recruitment engines is an important task because of the vast volume and varying types of applicants. We propose a résumé matching method to be used as a recommendation engine for recruiters. Our approach combines cutting-edge transformer-based natural language processing technology with the triplet loss, a training method originally developed for the computer vision domain. By treating the output embeddings of a transformer model similarly to those of a convolutional neural network, we develop a model for the document retrieval task. The paper also investigates a clustering based pretraining method before fine-tuning with the triplet loss. The method is applied on the data extracted from an online recruitment website, where real users actively create their own résumés. Measured by the precision at k score, the method yields an accuracy boost of %12 compared to a base model.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
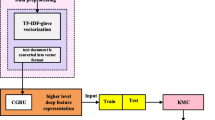
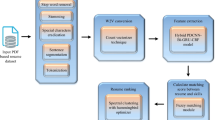

References
Hu, W., Qiu, H., Huang, J., Dumontier, M.: BioSearch: a semantic search engine for Bio2RDF. Database, 2017 (2017)
Wu, H., et al.: SemEHR: a general-purpose semantic search system to surface semantic data from clinical notes for tailored care, trial recruitment, and clinical research. J. Am. Med. Inf. Assoc. 25(5), 530–537 (2018)
Li, Q., Avadhanam, S., Zhang, Q.: An end-to-end tool for news processing and semantic search. In: Companion Proceedings of the Web Conference 2020, pp. 139–142 (2020)
Al-Natsheh, H.T., Martinet, L., Muhlenbach, F., Rico, F., Zighed, D.A.: Semantic search-by-examples for scientific topic corpus expansion in digital libraries. In: 2017 IEEE International Conference on Data Mining Workshops (ICDMW), pp. 747–756. IEEE (2017)
Khan, H.U., Saqlain, S.M., Shoaib, M., Sher, M.: Ontology based semantic search in Holy Quran. Int. J. Future Comput. Commun. 2(6), 570 (2013)
Bhatia, V., Rawat, P., Kumar, A., Shah, R.R.: End-to-End Résumé Parsing and Finding Candidates for a Job Description Using BERT. arXiv preprint arXiv:1910.03089 (2019)
Lavi, D., Medentsiy, V., Graus, D.: conSultantBERT: Fine-Tuned Siamese Sentence-BERT for Matching Jobs and Job Seekers. arXiv preprint arXiv:2109.06501 (2021)
Rafter, R., Bradley, K., Smyth, B.: Personalised retrieval for online recruitment services. In: The BCS/IRSG 22nd Annual Colloquium on Information Retrieval (IRSG 2000), Cambridge, 5–7 April 2000 (2000)
Färber, F., Weitzel, T., Keim, T.: An automated recommendation approach to selection in personnel recruitment (2003)
Reimers, N., Gurevych, I.: Making monolingual sentence embeddings multilingual using knowledge distillation. arXiv preprint arXiv:2004.09813 (2020)
Wolf, T., et al.: Transformers: state-of-the-art natural language processing. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 38–45 (2020)
Gordo, A., Almazán, J., Revaud, J., Larlus, D.: Deep image retrieval: learning global representations for image search. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9910, pp. 241–257. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46466-4_15
Sanakoyeu, A., Tschernezki, V., Buchler, U., Ommer, B.: Divide and conquer the embedding space for metric learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 471–480 (2019)
Cabrera-Diego, L.A., Durette, B., Lafon, M., Torres-Moreno, J.M., El-Bèze, M.: How can we measure the similarity between résumés of selected candidates for a job?. In: Proceedings of the International Conference on Data Science (ICDATA) (p. 99). The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp) (2015)
Herlocker, J.L., Konstan, J.A., Terveen, L.G., Riedl, J.T.: Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. 22(1), 5–53 (2004)
Gururangan, S., et al.: Don’t stop pretraining: adapt language models to domains and tasks. arXiv preprint arXiv:2004.10964 (2020)
Howard, J., Ruder, S.: Universal language model fine-tuning for text classification. arXiv preprint arXiv:1801.06146 (2018)
Liu, Y., et al.: Roberta: a robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019)
Wang, K., Reimers, N., Gurevych, I.: TSDAE: Using Transformer-Based Sequential Denoising Auto-Encoder for Unsupervised Sentence Embedding Learning. arXiv preprint arXiv:2104.06979 (2021)
Lloyd, S.: Least squares quantization in PCM. IEEE Trans. Inf. Theory 28(2), 129–137 (1982)
Kaufman, L., Rousseeuw, P.J.: Partitioning around medoids (program pam). Finding Groups in Data: an Introduction to Cluster Analysis 344, 68–125 (1990)
Ester, M., Kriegel, H.P., Sander, J., Xu, X.: A density-based algorithm for discovering clusters in large spatial databases with noise. KDD 96(34), 226–231 (1996)
Schroff, F., Kalenichenko, D., Philbin, J.: Facenet: a unified embedding for face recognition and clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 815–823 (2015)
Hermans, A., Beyer, L., Leibe, B.: In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737 (2017)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Özlü, Ö.A., Orman, G.K., Daniş, F.S., Turhan, S.N., Kara, K.C., Yücel, T.A. (2023). Similarity-Based Résumé Matching via Triplet Loss with BERT Models. In: Arai, K. (eds) Intelligent Systems and Applications. IntelliSys 2022. Lecture Notes in Networks and Systems, vol 544. Springer, Cham. https://doi.org/10.1007/978-3-031-16075-2_37
Download citation
DOI: https://doi.org/10.1007/978-3-031-16075-2_37
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-16074-5
Online ISBN: 978-3-031-16075-2
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)