
Abstract
The style and vocabulary of social media communication, such as chats, discussions or comments, differ vastly from standard languages. Specifically in internal business communication, the texts contain large amounts of language mixins, professional jargon and occupational slang, or colloquial expressions. Standard natural language processing tools thus mostly fail to detect basic text processing attributes such as the prevalent language of a message or communication or their sentiment.
In the presented paper, we describe the development and evaluation of new modules specifically designed for language identification and sentiment analysis of informal business communication inside a large international company. Besides the details of the module architectures, we offer a detailed comparison with other state-of-the-art tools for the same purpose and achieve an improvement of 10–13 % in accuracy with selected problematic datasets.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


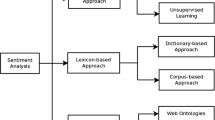
Notes
- 1.
The language used in social media communications.
- 2.
cs, csd, da, de, en, es, fi, fr, hu, it, jp, nl, no, pl, ru, se, sk, skd, sw, and zh.
- 3.
- 4.
- 5.
References
Agarwal, B., Poria, S., Mittal, N., Gelbukh, A., Hussain, A.: Concept-level sentiment analysis with dependency-based semantic parsing: a novel approach. Cogn. Comput. 7(4), 487–499 (2015)
Balducci, B., Marinova, D.: Unstructured data in marketing. J. Acad. Mark. Sci. 46(4), 557–590 (2018)
Bilík, J.: Emotion detection in plain text (in Czech) (2014). https://is.muni.cz/th/ko3aa/
Chan, S.W., Chong, M.W.: Sentiment analysis in financial texts. Decis. Support Syst. 94, 53–64 (2017)
Chen, Y., Skiena, S.: Building sentiment lexicons for all major languages. In: Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Short Papers), pp. 383–389 (2014)
Dashtipour, K., Poria, S., Hussain, A., Cambria, E., Hawalah, A.Y., Gelbukh, A., Zhou, Q.: Multilingual sentiment analysis: state of the art and independent comparison of techniques. Cogn. Comput. 8(4), 757–771 (2016)
Esuli, A., Sebastiani, F.: SentiWordNet: a publicly available lexical resource for opinion mining. In: Proceedings of the Fifth International Con Language Resources and Evaluation (LREC’06) (2006)
Fellbaum, C. (ed.): WordNet: An electronic lexical database. MIT Press (1998)
Greco, F., Polli, A.: Emotional text mining: customer profiling in brand management. Int. J. Inf. Manage. 51, 101934 (2020)
Jakubíček, M., Kilgarriff, A., Kovář, V., Rychlý, P., Suchomel, V.: The tenten corpus family. In: 7th International Corpus Linguistics Conference CL, pp. 125–127. Lancaster University (2013)
Joulin, A., Grave, E., Bojanowski, P., Mikolov, T.: Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759 (2016)
Koublová, A.: Monitoring the use of subjective adjectives in connection with named entities in Czech internet news (in Czech) (2014). https://is.muni.cz/th/jlfc4/
Lison, P., Tiedemann, J., Kouylekov, M.: Opensubtitles 2018: statistical rescoring of sentence alignments in large, noisy parallel corpora. In: Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) (2018)
Lui, M., Baldwin, T.: langid.py: An off-the-shelf language identification tool. In: Proceedings of the ACL 2012 System Demonstrations, pp. 25–30. Association for Computational Linguistics, Jeju Island, Korea, July 2012. https://aclanthology.org/P12-3005
Nielsen, F.Å.: Afinn, March 2011. http://www2.compute.dtu.dk/pubdb/pubs/6010-full.html
Rychlý, P.: CzAccent - simple tool for restoring accents in czech texts. In: Aleš Horák, P.R. (ed.) 6th Workshop on Recent Advances in Slavonic Natural Language Processing, pp. 15–22. Tribun EU, Brno (2012), https://nlp.fi.muni.cz/raslan/2012/paper14.pdf
Stray, V., Moe, N.B., Noroozi, M.: Slack me if you can! using enterprise social networking tools in virtual agile teams. In: 2019 ACM/IEEE 14th International Conference on Global Software Engineering (ICGSE), pp. 111–121. IEEE (2019)
Sundermeyer, M., Schlüter, R., Ney, H.: LSTM neural networks for language modeling. In: Thirteenth Annual Conference of the International Speech Communication Association (2012)
Toftrup, M., Asger Sørensen, S., Ciosici, M.R., Assent, I.: A reproduction of Apple’s bi-directional LSTM models for language identification in short strings. In: Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop, pp. 36–42. Association for Computational Linguistics, April 2021. 10.18653/v1/2021.eacl-srw.6, https://aclanthology.org/2021.eacl-srw.6
Wang, Y., Kung, L., Byrd, T.A.: Big data analytics: understanding its capabilities and potential benefits for healthcare organizations. Technol. Forecast. Soc. Chang. 126, 3–13 (2018)
Acknowledgments
This work has been partly supported by the Ministry of Education of CR within the LINDAT-CLARIAH-CZ project LM2018101. Access to computing and storage facilities owned by parties and projects contributing to the National Grid Infrastructure MetaCentrum provided under the programme “Projects of Large Research, Development, and Innovations Infrastructures” (CESNET LM2015042), is greatly appreciated.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 Springer Nature Switzerland AG
About this paper

Cite this paper
Sabol, R., Horák, A. (2022). New Language Identification and Sentiment Analysis Modules for Social Media Communication. In: Sojka, P., Horák, A., Kopeček, I., Pala, K. (eds) Text, Speech, and Dialogue. TSD 2022. Lecture Notes in Computer Science(), vol 13502. Springer, Cham. https://doi.org/10.1007/978-3-031-16270-1_8
Download citation
DOI: https://doi.org/10.1007/978-3-031-16270-1_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-16269-5
Online ISBN: 978-3-031-16270-1
eBook Packages: Computer ScienceComputer Science (R0)