
Abstract
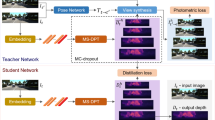
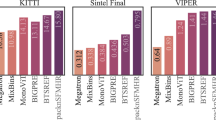
Unsupervised depth estimation using photometric losses suffers from local minimum and training instability. We address this issue by proposing an adaptive co-teaching framework to distill the learned knowledge from unsupervised teacher networks to a student network. We design an ensemble architecture for our teacher networks, integrating a depth basis decoder with multiple depth coefficient decoders. Depth prediction can then be formulated as a combination of the predicted depth bases weighted by coefficients. By further constraining their correlations, multiple coefficient decoders can yield a diversity of depth predictions, serving as the ensemble teachers. During the co-teaching step, our method allows different supervision sources from not only ensemble teachers but also photometric losses to constantly compete with each other, and adaptively select the optimal ones to teach the student, which effectively improves the ability of the student to jump out of the local minimum. Our method is shown to significantly benefit unsupervised depth estimation and sets new state of the art on both KITTI and Nuscenes datasets.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Bian, J., et al.: Unsupervised scale-consistent depth and ego-motion learning from monocular video. Adv. Neural. Inf. Process. Syst. 32, 35–45 (2019)
Bloesch, M., Czarnowski, J., Clark, R., Leutenegger, S., Davison, A.J.: Codeslam-learning a compact, optimisable representation for dense visual slam. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2560–2568 (2018)
Bucila, C., Caruana, R., Niculescu-Mizil, A.: Model compression. In: ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2006) (2006)
Caesar, H., et al.: nuscenes: a multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11621–11631 (2020)
Casser, V., Pirk, S., Mahjourian, R., Angelova, A.: Depth prediction without the sensors: leveraging structure for unsupervised learning from monocular videos. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 8001–8008 (2019)
Chen, G., Choi, W., Yu, X., Han, T., Chandraker, M.: Learning efficient object detection models with knowledge distillation. Adv. Neural Inf. Process. Syst. 30 (2017)
Choi, J., Jung, D., Lee, D., Kim, C.: Safenet: self-supervised monocular depth estimation with semantic-aware feature extraction. In: Thirty-Fourth Conference on Neural Information Processing Systems, NIPS 2020. NeurIPS (2020)
Eigen, D., Fergus, R.: Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2650–2658 (2015)
Eigen, D., Puhrsch, C., Fergus, R.: Depth map prediction from a single image using a multi-scale deep network. In: 28th Annual Conference on Neural Information Processing Systems 2014, NIPS 2014, pp. 2366–2374. Neural information processing systems foundation (2014)
Fan, H., Hao, S., Guibas, L.: A point set generation network for 3D object reconstruction from a single image. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Fang, J., Liu, G.: Self-supervised learning of depth and ego-motion from video by alternative training and geometric constraints from 3D to 2D. arXiv preprint arXiv:2108.01980 (2021)
Garg, R., B.G., V.K., Carneiro, G., Reid, I.: Unsupervised CNN for single view depth estimation: geometry to the rescue. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 740–756. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_45
Geiger, A., Lenz, P., Urtasun, R.: Are we ready for autonomous driving? the kitti vision benchmark suite. In: 2012 IEEE Conference on Computer Vision and Pattern Recognition, pp. 3354–3361. IEEE (2012)
Godard, C., Mac Aodha, O., Brostow, G.J.: Unsupervised monocular depth estimation with left-right consistency. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 270–279 (2017)
Godard, C., Mac Aodha, O., Firman, M., Brostow, G.J.: Digging into self-supervised monocular depth estimation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3828–3838 (2019)
Guizilini, V., Ambrus, R., Pillai, S., Raventos, A., Gaidon, A.: 3D packing for self-supervised monocular depth estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2485–2494 (2020)
Guizilini, V., Hou, R., Li, J., Ambrus, R., Gaidon, A.: Semantically-guided representation learning for self-supervised monocular depth. In: International Conference on Learning Representations (2019)
Gupta, S., Hoffman, J., Malik, J.: Cross modal distillation for supervision transfer. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2827–2836 (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015)
Janai, J., Guney, F., Ranjan, A., Black, M., Geiger, A.: Unsupervised learning of multi-frame optical flow with occlusions. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 690–706 (2018)
Johnston, A., Carneiro, G.: Self-supervised monocular trained depth estimation using self-attention and discrete disparity volume. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4756–4765 (2020)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Lee, S., Im, S., Lin, S., Kweon, I.S.: Learning monocular depth in dynamic scenes via instance-aware projection consistency. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 1863–1872 (2021)
Li, S., Wu, X., Cao, Y., Zha, H.: Generalizing to the open world: deep visual odometry with online adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13184–13193 (2021)
Li, Y., Yang, J., Song, Y., Cao, L., Li, L.J.: Learning from noisy labels with distillation. In: 2017 IEEE International Conference on Computer Vision (ICCV) (2017)
Lyu, X., et al.: Hr-depth: high resolution self-supervised monocular depth estimation. CoRR abs/2012.07356 (2020)
Peng, R., Wang, R., Lai, Y., Tang, L., Cai, Y.: Excavating the potential capacity of self-supervised monocular depth estimation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 15560–15569 (2021)
Pilzer, A., Lathuilière, S., Sebe, N., Ricci, E.: Refine and distill: exploiting cycle-inconsistency and knowledge distillation for unsupervised monocular depth estimation. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
Pilzer, A., Xu, D., Puscas, M., Ricci, E., Sebe, N.: Unsupervised adversarial depth estimation using cycled generative networks. In: 2018 International Conference on 3D Vision (3DV), pp. 587–595. IEEE (2018)
Poggi, M., Aleotti, F., Tosi, F., Mattoccia, S.: On the uncertainty of self-supervised monocular depth estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3227–3237 (2020)
Prucksakorn, T., Jeong, S., Chong, N.Y.: A self-trainable depth perception method from eye pursuit and motion parallax. Robot. Auton. Syst. 109, 27–37 (2018)
Shu, C., Yu, K., Duan, Z., Yang, K.: Feature-metric loss for self-supervised learning of depth and egomotion. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12364, pp. 572–588. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58529-7_34
Teed, Z., Deng, J.: RAFT: recurrent all-pairs field transforms for optical flow. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12347, pp. 402–419. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58536-5_24
Wagstaff, B., Peretroukhin, V., Kelly, J.: Self-supervised structure-from-motion through tightly-coupled depth and egomotion networks. arXiv preprint arXiv:2106.04007 (2021)
Wang, L., Wang, Y., Wang, L., Zhan, Y., Wang, Y., Lu, H.: Can scale-consistent monocular depth be learned in a self-supervised scale-invariant manner? In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 12727–12736 (2021)
Watson, J., Mac Aodha, O., Prisacariu, V., Brostow, G., Firman, M.: The temporal opportunist: self-supervised multi-frame monocular depth. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1164–1174 (2021)
Yang, J., Alvarez, J.M., Liu, M.: Self-supervised learning of depth inference for multi-view stereo. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7526–7534 (2021)
Yang, J., Mao, W., Alvarez, J.M., Liu, M.: Cost volume pyramid based depth inference for multi-view stereo. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4877–4886 (2020)
Yin, Z., Shi, J.: Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1983–1992 (2018)
Zhao, W., Liu, S., Shu, Y., Liu, Y.J.: Towards better generalization: joint depth-pose learning without posenet. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
Zhou, J., Wang, Y., Qin, K., Zeng, W.: Unsupervised high-resolution depth learning from videos with dual networks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6872–6881 (2019)
Zhou, T., Brown, M., Snavely, N., Lowe, D.G.: Unsupervised learning of depth and ego-motion from video. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Acknowledgements
This research is supported by National Natural Science Foundation of China (61906031, 62172070, U1903215, 6182910), and Fundamental Research Funds for Central Universities (DUT21RC(3)025).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Ren, W., Wang, L., Piao, Y., Zhang, M., Lu, H., Liu, T. (2022). Adaptive Co-teaching for Unsupervised Monocular Depth Estimation. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds) Computer Vision – ECCV 2022. ECCV 2022. Lecture Notes in Computer Science, vol 13661. Springer, Cham. https://doi.org/10.1007/978-3-031-19769-7_6
Download citation
DOI: https://doi.org/10.1007/978-3-031-19769-7_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-19768-0
Online ISBN: 978-3-031-19769-7
eBook Packages: Computer ScienceComputer Science (R0)