
Abstract
Neural Radiance Fields (NeRF) methods show impressive performance for novel view synthesis by representing a scene via a neural network. However, most existing NeRF based methods, including its variants, treat each sample point individually as input, while ignoring the inherent relationships between adjacent sample points from the corresponding rays, thus hindering the reconstruction performance. To address this issue, we explore a brand new scheme, namely NeXT, introducing a multi-skip transformer to capture the rich relationships between various sample points in a ray-level query. Specifically, ray tokenization is proposed to represent each ray as a sequence of point embeddings which is taken as input of our proposed NeXT. In this way, relationships between sample points are captured via the built-in self-attention mechanism to promote the reconstruction. Besides, our proposed NeXT can be easily combined with other NeRF based methods to improve their rendering quality. Extensive experiments conducted on three datasets demonstrate that NeXT significantly outperforms all previous state-of-the-art work by a large margin. In particular, the proposed NeXT surpasses the strong NeRF baseline by 2.74 dB of PSNR on Blender dataset. The code is available at https://github.com/Crishawy/NeXT.
Y Wang and Y Li—Equal contribution.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

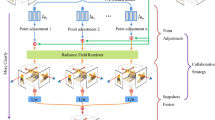

Notes
References
Arandjelović, R., Zisserman, A.: Nerf in detail: learning to sample for view synthesis. arXiv preprint arXiv:2106.05264 (2021)
Barron, J.T., Mildenhall, B., Tancik, M., Hedman, P., Martin-Brualla, R., Srinivasan, P.P.: Mip-NeRF: a multiscale representation for anti-aliasing neural radiance fields. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5855–5864 (2021)
Bi, S., et al.: Neural reflectance fields for appearance acquisition. arXiv preprint arXiv:2008.03824 (2020)
Boss, M., Braun, R., Jampani, V., Barron, J.T., Liu, C., Lensch, H.: Nerd: neural reflectance decomposition from image collections. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 12684–12694 (2021)
Bradbury, J., et al.: Jax: composable transformations of python+ numpy programs 2018. http://github.com/google/jax 4, 16 (2020)
Buehler, C., Bosse, M., McMillan, L., Gortler, S., Cohen, M.: Unstructured lumigraph rendering. In: Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, pp. 425–432 (2001)
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12346, pp. 213–229. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58452-8_13
Chan, E.R., Monteiro, M., Kellnhofer, P., Wu, J., Wetzstein, G.: Pi-GAN: periodic implicit generative adversarial networks for 3d-aware image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5799–5809 (2021)
Dai, Z., Cai, B., Lin, Y., Chen, J.: UP-DETR: unsupervised pre-training for object detection with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1601–1610 (2021)
Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q.V., Salakhutdinov, R.: Transformer-xl: attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860 (2019)
Davis, A., Levoy, M., Durand, F.: Unstructured light fields. In: Computer Graphics Forum, vol. 31, pp. 305–314. Wiley Online Library (2012)
Debevec, P.E., Taylor, C.J., Malik, J.: Modeling and rendering architecture from photographs: a hybrid geometry-and image-based approach. In: Proceedings of the 23rd annual conference on Computer Graphics and Interactive Techniques, pp. 11–20 (1996)
Deng, B., Barron, J.T., Srinivasan, P.P.: JaxNeRF: an efficient JAX implementation of NeRF (2020)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
Dosovitskiy, A., et al.: An image is worth 16 x 16 words: transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
Flynn, J., et al.: DeepView: view synthesis with learned gradient descent. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2367–2376 (2019)
Gafni, G., Thies, J., Zollhofer, M., Nießner, M.: Dynamic neural radiance fields for monocular 4d facial avatar reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8649–8658 (2021)
Gao, C., Shih, Y., Lai, W.S., Liang, C.K., Huang, J.B.: Portrait neural radiance fields from a single image. arXiv preprint arXiv:2012.05903 (2020)
Garbin, S.J., Kowalski, M., Johnson, M., Shotton, J., Valentin, J.: FastNeRF: high-fidelity neural rendering at 200fps. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 14346–14355 (2021)
Gortler, S.J., Grzeszczuk, R., Szeliski, R., Cohen, M.F.: The lumigraph. In: Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, pp. 43–54 (1996)
Hedman, P., Srinivasan, P.P., Mildenhall, B., Barron, J.T., Debevec, P.: Baking neural radiance fields for real-time view synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5875–5884 (2021)
Jain, A., Tancik, M., Abbeel, P.: Putting nerf on a diet: semantically consistent few-shot view synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5885–5894 (2021)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Levoy, M., Hanrahan, P.: Light field rendering. In: Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, pp. 31–42 (1996)
Li, Y., et al.: TokenPose: learning keypoint tokens for human pose estimation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 11313–11322 (2021)
Li, Z., Niklaus, S., Snavely, N., Wang, O.: Neural scene flow fields for space-time view synthesis of dynamic scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6498–6508 (2021)
Lindell, D.B., Martel, J.N., Wetzstein, G.: AutoInt: automatic integration for fast neural volume rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14556–14565 (2021)
Liu, L., Gu, J., Zaw Lin, K., Chua, T.S., Theobalt, C.: Neural sparse voxel fields. Adv. Neural Inf. Process. Syst. 33, 15651–15663 (2020)
Lombardi, S., Simon, T., Saragih, J., Schwartz, G., Lehrmann, A., Sheikh, Y.: Neural volumes: learning dynamic renderable volumes from images. arXiv preprint arXiv:1906.07751 (2019)
Mildenhall, B., et al.: Local light field fusion: practical view synthesis with prescriptive sampling guidelines. ACM Trans. Graph. (TOG) 38(4), 1–14 (2019)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: NeRF: representing scenes as neural radiance fields for view synthesis. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12346, pp. 405–421. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58452-8_24
Neff, T., et al.: Donerf: towards real-time rendering of neural radiance fields using depth oracle networks. arXiv e-prints pp. arXiv-2103 (2021)
Niemeyer, M., Geiger, A.: Giraffe: representing scenes as compositional generative neural feature fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11453–11464 (2021)
Niemeyer, M., Mescheder, L., Oechsle, M., Geiger, A.: Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3504–3515 (2020)
Ost, J., Mannan, F., Thuerey, N., Knodt, J., Heide, F.: Neural scene graphs for dynamic scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2856–2865 (2021)
Park, K., et al.: Nerfies: Deformable neural radiance fields. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5865–5874 (2021)
Pumarola, A., Corona, E., Pons-Moll, G., Moreno-Noguer, F.: D-nerf: neural radiance fields for dynamic scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10318–10327 (2021)
Raj, A., et al.: Pva: pixel-aligned volumetric avatars. arXiv preprint arXiv:2101.02697 (2021)
Rebain, D., Jiang, W., Yazdani, S., Li, K., Yi, K.M., Tagliasacchi, A.: Derf: decomposed radiance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14153–14161 (2021)
Reiser, C., Peng, S., Liao, Y., Geiger, A.: KiloNeRF: speeding up neural radiance fields with thousands of tiny MLPs. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 14335–14345 (2021)
Rematas, K., Martin-Brualla, R., Ferrari, V.: ShaRF: shape-conditioned radiance fields from a single view. arXiv preprint arXiv:2102.08860 (2021)
Riegler, G., Koltun, V.: Free view synthesis. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12364, pp. 623–640. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58529-7_37
Riegler, G., Koltun, V.: Stable view synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12216–12225 (2021)
Schwarz, K., Liao, Y., Niemeyer, M., Geiger, A.: Graf: Generative radiance fields for 3d-aware image synthesis. Adv. Neural Inf. Process. Syst. 33, 20154–20166 (2020)
Seitz, S.M., Dyer, C.R.: Photorealistic scene reconstruction by voxel coloring. Int. J. Comput. Vision 35(2), 151–173 (1999)
Sitzmann, V., Thies, J., Heide, F., Nießner, M., Wetzstein, G., Zollhofer, M.: DeepVoxels: learning persistent 3d feature embeddings. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2437–2446 (2019)
Sitzmann, V., Zollhöfer, M., Wetzstein, G.: Scene representation networks: continuous 3d-structure-aware neural scene representations. In: Advances in Neural Information Processing Systems, vol. 32 (2019)
Srinivasan, P.P., Deng, B., Zhang, X., Tancik, M., Mildenhall, B., Barron, J.T.: NeRV: neural reflectance and visibility fields for relighting and view synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7495–7504 (2021)
Srinivasan, P.P., Tucker, R., Barron, J.T., Ramamoorthi, R., Ng, R., Snavely, N.: Pushing the boundaries of view extrapolation with multiplane images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 175–184 (2019)
Strudel, R., Garcia, R., Laptev, I., Schmid, C.: Segmenter: transformer for semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7262–7272 (2021)
Tancik, M., et al.: Learned initializations for optimizing coordinate-based neural representations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2846–2855 (2021)
Tolstikhin, I.O., et al.: MLP-Mixer: an all-MLP architecture for vision. In: Advances in Neural Information Processing Systems, vol. 34 (2021)
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.: Training data-efficient image transformers & distillation through attention. In: International Conference on Machine Learning, pp. 10347–10357. PMLR (2021)
Trevithick, A., Yang, B.: GRF: learning a general radiance field for 3d representation and rendering. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 15182–15192 (2021)
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing systems vol. 30 (2017)
Waechter, M., Moehrle, N., Goesele, M.: Let there be color! large-scale texturing of 3d reconstructions. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) Computer Vision - ECCV 2014, ECCV 2014. Lecture Notes in Computer Science, vol. 8693, pp. 836–850. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10602-1_54
Wang, Q., et al.: IBRNet: learning multi-view image-based rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4690–4699 (2021)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
Wood, D.N., et al.: Surface light fields for 3d photography. In: Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, pp. 287–296 (2000)
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P.: SegFormer: simple and efficient design for semantic segmentation with transformers. In: Advances in Neural Information Processing Systems, vol. 34 (2021)
Yang, S., Quan, Z., Nie, M., Yang, W.: Transpose: towards explainable human pose estimation by transformer. arXiv e-prints pp. arXiv-2012 (2020)
Yariv, L., et al.: Multiview neural surface reconstruction by disentangling geometry and appearance. Adv. Neural Inf. Process. Syst. 33, 2492–2502 (2020)
Yu, A., Li, R., Tancik, M., Li, H., Ng, R., Kanazawa, A.: Plenoctrees for real-time rendering of neural radiance fields. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5752–5761 (2021)
Yu, A., Ye, V., Tancik, M., Kanazawa, A.: pixelNeRF: neural radiance fields from one or few images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4578–4587 (2021)
Yuan, L., et al.: Tokens-to-Token ViT: training vision transformers from scratch on ImageNet. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 558–567 (2021)
Yuan, Y., et al.: HRformer: high-resolution transformer for dense prediction. arXiv preprint arXiv:2110.09408 (2021)
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: learning view synthesis using multiplane images. arXiv preprint arXiv:1805.09817 (2018)
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable DETR: deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159 (2020)
Acknowledgements
This work is supported in part by the National Natural Science Foundation of China under Grant 62171248, and the PCNL KEY project (PCL2021A07).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Wang, Y., Li, Y., Liu, P., Dai, T., Xia, ST. (2022). NeXT: Towards High Quality Neural Radiance Fields via Multi-skip Transformer. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds) Computer Vision – ECCV 2022. ECCV 2022. Lecture Notes in Computer Science, vol 13692. Springer, Cham. https://doi.org/10.1007/978-3-031-19824-3_5
Download citation
DOI: https://doi.org/10.1007/978-3-031-19824-3_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-19823-6
Online ISBN: 978-3-031-19824-3
eBook Packages: Computer ScienceComputer Science (R0)