
Abstract
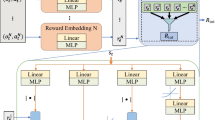
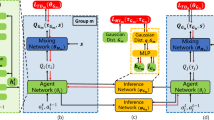
This paper explores value-decomposition methods in cooperative multi-agent reinforcement learning (MARL) under the paradigm of centralized training with decentralized execution. These methods decompose a global shared value into individual ones to guide the learning of decentralized policies. While Q-value decomposition methods such as QMIX show state-of-the-art performance, V-value decomposition methods are proposed to obtain a reasonable trade-off between training efficiency and algorithm performance under the A2C training paradigm. However, existing V-value decomposition methods lack theoretical analysis of the relation between the global V-value and local V-values, and do not explicitly consider the influence of individuals on the total system, which degrades their performance. To address these problems, this paper proposes a novel approach called V-value Attention Actor-Critic (VAAC) for cooperative MARL. We theoretically derive a general decomposing formulation of the global V-value in terms of local V-values of individual agents, and implement it with a multi-head attention formation to model the impact of individuals on the whole system for interpretability of decomposition. Evaluations on the challenging StarCraft II micromanagement task show that VAAC achieves a better trade-off between training efficiency and algorithm performance, and provides interpretability for its decomposition process.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Cao, Y., Yu, W., Ren, W., Chen, G.: An overview of recent progress in the study of distributed multi-agent coordination. IEEE Trans. Industr. Inf. 9(1), 427–438 (2012)
Foerster, J., Farquhar, G., Afouras, T., Nardelli, N., Whiteson, S.: Counterfactual multi-agent policy gradients. In: Proceedings of the AAAI Conference on Artificial Intelligence (2018)
Ha, D., Dai, A., Le, Q.V.: Hypernetworks. arXiv preprint arXiv:1609.09106 (2016)
Kraemer, L., Banerjee, B.: Multi-agent reinforcement learning as a rehearsal for decentralized planning. Neurocomputing 190, 82–94 (2016)
Lowe, R., Wu, Y.I., Tamar, A., Harb, J., Pieter Abbeel, O., Mordatch, I.: Multi-agent actor-critic for mixed cooperative-competitive environments. In: Advances in Neural Information Processing Systems 30 (2017)
Mnih, V., et al.: Asynchronous methods for deep reinforcement learning. In: International Conference on Machine Learning, pp. 1928–1937 (2016)
Qiu, W., et al.: RMIX: learning risk-sensitive policies for cooperative reinforcement learning agents. In: Advances in Neural Information Processing Systems 34 (2021)
Rashid, T., Samvelyan, M., Schroeder, C., Farquhar, G., Foerster, J., Whiteson, S.: QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning. In: International Conference on Machine Learning, pp. 4295–4304 (2018)
Samvelyan, M., et al.: The starcraft multi-agent challenge. In: Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, pp. 2186–2188 (2019)
Son, K., Kim, D., Kang, W.J., Hostallero, D.E., Yi, Y.: QTRAN: learning to factorize with transformation for cooperative multi-agent reinforcement learning. In: International Conference on Machine Learning, pp. 5887–5896 (2019)
Su, J., Adams, S., Beling, P.A.: Value-decomposition multi-agent actor-critics. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 11352–11360 (2021)
Sunehag, P., et al.: Value-decomposition networks for cooperative multi-agent learning based on team reward. In: AAMAS (2018)
Tan, M.: Multi-agent reinforcement learning: independent vs. cooperative agents. In: Proceedings of the Tenth International Conference on Machine Learning, pp. 330–337 (1993)
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems 30 (2017)
Wang, J., Ren, Z., Liu, T., Yu, Y., Zhang, C.: QPLEX: duplex dueling multi-agent Q-learning. In: International Conference on Learning Representations (2020)
Wang, T., Gupta, T., Peng, B., Mahajan, A., Whiteson, S., Zhang, C.: Rode: learning roles to decompose multi-agent tasks. In: Proceedings of the International Conference on Learning Representations (2021)
Wolpert, D.H., Tumer, K.: Optimal payoff functions for members of collectives. In: Modeling Complexity in Economic and Social Systems, pp. 355–369. World Scientific (2002)
Yang, Y., et al.: Qatten: a general framework for cooperative multiagent reinforcement learning. arXiv preprint arXiv:2002.03939 (2020)
Yun, C., Bhojanapalli, S., Rawat, A.S., Reddi, S., Kumar, S.: Are transformers universal approximators of sequence-to-sequence functions? In: International Conference on Learning Representations (2019)
Zhang, C., Lesser, V.: Coordinated multi-agent reinforcement learning in networked distributed POMDPs. In: Twenty-Fifth AAAI Conference on Artificial Intelligence (2011)
Acknowledgement
This work was supported in part to Dr. Liansheng Zhuang by NSFC under contract No.U20B2070 and No.61976199.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Liu, H., Zhuang, L., Huang, Y., Zhao, C. (2023). VAAC: V-value Attention Actor-Critic for Cooperative Multi-agent Reinforcement Learning. In: Tanveer, M., Agarwal, S., Ozawa, S., Ekbal, A., Jatowt, A. (eds) Neural Information Processing. ICONIP 2022. Lecture Notes in Computer Science, vol 13623. Springer, Cham. https://doi.org/10.1007/978-3-031-30105-6_47
Download citation
DOI: https://doi.org/10.1007/978-3-031-30105-6_47
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-30104-9
Online ISBN: 978-3-031-30105-6
eBook Packages: Computer ScienceComputer Science (R0)