
Abstract
Binary Neural Networks (BNNs) use 1-bit weights and activations to efficiently execute deep convolutional neural networks on edge devices. Nevertheless, the binarization of the first layer is conventionally excluded, as it leads to a large accuracy loss. The few works addressing the first layer binarization, typically increase the number of input channels to enhance data representation; such data expansion raises the amount of operations needed and it is feasible only on systems with enough computational resources. In this work, we present a new method to binarize the first layer using directly the 8-bit representation of input data; we exploit the standard bit-planes encoding to extract features bit-wise (using depth-wise convolutions); after a re-weighting stage, features are fused again. The resulting model is fully binarized and our first layer binarization approach is model independent. The concept is evaluated on three classification datasets (CIFAR10, SVHN and CIFAR100) for different model architectures (VGG and ResNet) and, the proposed technique outperforms state of the art methods both in accuracy and BMACs reduction.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

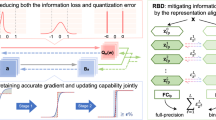

Notes
- 1.
Before the addition of our depth-wise convolutions.
- 2.
\(m \times \left( n-CK \right) \) stands for m consecutive convolutional layers, each one with n output channels and K kernel size. MP2 is the max pooling layer with subsample 2 while FCx is a fully-connected layer having x neurons. Softmax represents the last dense classification layer using softmax as activation.
- 3.
Refer to the following https://github.com/liuzechun/Bi-Real-net repository for all the details.
- 4.
Refer to the following https://github.com/liuzechun/ReActNet repository for all the details.
- 5.
For DBID, thermometer and baseline methods, we reduced to 32 the number of output channels of layer F1; for BIL and ours, we skipped the layer F1 because the convolution operation is already exploited within the input layer binarization process. For DBID, BIL and ours we used only the 4 most significant bits of input data. For thermometer we applied also a reduced expansion factor of \(K=16\).
- 6.
References
Choi, J., et al.: PACT: parameterized clipping activation for quantized neural networks. In: arXiv preprint arXiv:1805.06085 (2018)
Hubara, I., et al.: Binarized neural networks. In: Advances in Neural Information Processing Systems, vol. 29 (2016)
Lin, X., Zhao, C., Pan, W.: Towards accurate binary convolutional neural network. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Rastegari, M., Ordonez, V., Redmon, J., Farhadi, A.: XNOR-Net: ImageNet classification using binary convolutional neural networks. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 525–542. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_32
Zhou, S., et al.: DoRefa-Net: training low bitwidth convolutional neural networks with low bitwidth gradients. In: arXiv preprint arXiv:1606.06160 (2016)
Han, S., Mao, H., Dally, W.J.: Deep compression: compressing deep neural networks with pruning, trained quantization and Huffman coding. In: arXiv preprint arXiv:1510.00149 (2015)
Wen, W., et al.: Learning structured sparsity in deep neural networks. In: Advances in Neural Information Processing Systems, vol. 29 (2016)
Howard, A.G., et al.: MobileNets: efficient convolutional neural networks for mobile vision applications. In: arXiv preprint arXiv:1704.04861 (2017)
Ma, N., Zhang, X., Zheng, H.-T., Sun, J.: ShuffleNet V2: practical guidelines for efficient CNN architecture design. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) Computer Vision – ECCV 2018. LNCS, vol. 11218, pp. 122–138. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01264-9_8
Tan, M., Le, Q.: EfficientNet: rethinking model scaling for convolutional neural networks. In: International Conference on Machine Learning. PMLR, pp. 6105–6114 (2019)
Tan, M., Le, Q.: EfficientNetV2: smaller models and faster training. In: International Conference on Machine Learning. PMLR, pp. 10096–10106 (2021)
Hou, Q., Zhou, D., Feng, J.: Coordinate attention for efficient mobile network design. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13713–13722 (2021)
Courbariaux, M., et al.: Binarized neural networks: training deep neural networks with weights and activations constrained to +1 or \(-\)1. In: arXiv preprint arXiv:1602.02830 (2016)
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
Netzer, Y., et al.: Reading digits in natural images with unsupervised feature learning (2011)
Russakovsky, O., et al.: ImageNet large scale visual recognition challenge. Int. J. Comput. Vision 115(3), 211–252 (2015). https://doi.org/10.1007/s11263-015-0816-y
Liu, Z., Wu, B., Luo, W., Yang, X., Liu, W., Cheng, K.-T.: Bi-real net: enhancing the performance of 1-bit CNNs with improved representational capability and advanced training algorithm. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11219, pp. 747–763. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01267-0_44
Gu, J., et al.: Projection convolutional neural networks for 1-bit CNNs via discrete back propagation. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 8344–8351, January 2019
Xu, Y., et al.: A main/subsidiary network framework for simplifying binary neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7154–7162 (2019)
Qin, H., et al.: Forward and backward information retention for accurate binary neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2250–2259 (2020)
Bethge, J., et al.: MeliusNet: can binary neural networks achieve MobileNet-level accuracy? In: arXiv preprint arXiv:2001.05936 (2020)
Bulat, A., Martinez, B., Tzimiropoulos, G.: High-capacity expert binary networks. In: arXiv preprint arXiv:2010.03558 (2020)
Martinez, B., et al.: Training binary neural networks with real-to-binary convolutions. In: arXiv preprint arXiv:2003.11535 (2020)
Liu, Z., Shen, Z., Savvides, M., Cheng, K.-T.: ReActNet: towards precise binary neural network with generalized activation functions. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12359, pp. 143–159. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58568-6_9
Shi, X., et al.: RepBNN: towards a precise binary neural network with enhanced feature map via repeating. In: arXiv preprint arXiv:2207.09049 (2022)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: arXiv preprint arXiv:1409.1556 (2014)
He, K., et al.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Anderson, A.G., Berg, C.P.: The high-dimensional geometry of binary neural networks. In: arXiv preprint arXiv:1705.07199 (2017)
Dürichen, R., et al.: Binary Input Layer: training of CNN models with binary input data. In: arXiv preprint arXiv:1812.03410 (2018)
Zhang, Y., et al.: FracBNN: accurate and FPGA-efficient binary neural networks with fractional activations. In: The 2021 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, pp. 171–182 (2021)
Ioffe, S., Szegedy, C.: Batch normalization: accelerating deep network training by reducing internal covariate shift. In: International Conference on Machine Learning. PMLR, pp. 448–456 (2015)
Vorabbi, L., Maltoni, D., Santi, S.: Optimizing dataflow in Binary Neural Networks. In: arXiv preprint arXiv:2304.00952 (2023)
Bannink, T., et al.: Larq compute engine: design, benchmark and deploy state-of-the-art binarized neural networks. Proc. Mach. Learn. Syst. 3, 680–695 (2021)
Bengio, Y., Léonard, N., Courville, A.: Estimating or propagating gradients through stochastic neurons for conditional computation. In: arXiv preprint arXiv:1308.3432 (2013)
Zhang, D., Yang, J., Ye, D., Hua, G.: LQ-nets: learned quantization for highly accurate and compact deep neural networks. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11212, pp. 373–390. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01237-3_23
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Vorabbi, L., Maltoni, D., Santi, S. (2023). Input Layer Binarization with Bit-Plane Encoding. In: Iliadis, L., Papaleonidas, A., Angelov, P., Jayne, C. (eds) Artificial Neural Networks and Machine Learning – ICANN 2023. ICANN 2023. Lecture Notes in Computer Science, vol 14261. Springer, Cham. https://doi.org/10.1007/978-3-031-44198-1_33
Download citation
DOI: https://doi.org/10.1007/978-3-031-44198-1_33
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-44197-4
Online ISBN: 978-3-031-44198-1
eBook Packages: Computer ScienceComputer Science (R0)