
Abstract
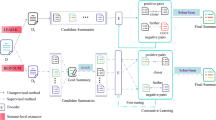
Abstractive summarization models frequently utilize decoding strategies, like beam search, which cause issues, such as a vast search space and exposure bias during decoding. To address this problem, we propose an online ranking model for summarization based on the likelihood probability. Our approach aims to establish a correlation between the output probability of a candidate summary and its quality, assigning higher output probabilities to summaries of better quality. Consequently, the ranking model can assess and select the best summary from several candidate summaries by contrasting their output probabilities during the ranking stage, thereby enhancing the performance of the summary model across various metrics. Simultaneously, our model adopts online sampling at each training step and incorporates information from the inference stage into the training process, which effectively mitigates the exposure bias that arises from the inconsistency between the model training and inference processes. Empirical results show that the proposed model performs impressively on the CNNDM and LCSTS public datasets. Compared with the baseline model, our online summarization ranking model yielded a 3.97, 2.55, and 4.12 increase in ROUGE-1, ROUGE-2, and ROUGE-L, respectively. Overall, experiments reaffirm the relevance of the ranking stage and the impact of the model in optimizing other metrics.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. In: Advances in Neural Information Processing Systems, pp. 27–35 (2014)
Ma, S., Sun, X., Li, W.: Query and output: generating words by querying distributed word representations for paraphrase generation. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp. 196–206 (2018)
Lewis, M., Liu, Y., Goyal, N.: BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 7871–7880 (2020)
Zhang, J., Zhao, Y., Saleh, M., Liu, P.: Pegasus: pre-training with extracted gap-sentences for abstractive summarization. In: International Conference on Machine Learning, pp. 11328–11339 (2020)
Ranzato, M., Chopra, S., Auli, M., Zaremba, W.: Sequence level training with recurrent neural networks. arXiv preprint arXiv:1511.06732 (2015)
Lin, C.Y., Hovy, E.: Automatic evaluation of summaries using n-gram co-occurrence statistics. In: Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, pp. 150–157 (2003)
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q., Artzi, Y.: BERTscore: evaluating text generation with BERT. In: International Conference on Learning Representations, pp. 4781–4788 (2020)
Hadsell, R., Chopra, S., LeCun, Y.: Dimensionality reduction by learning an invariant mapping. In: 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2006), vol. 2, pp. 1735–1742. IEEE (2006)
Vaswani, A., et al.: Attention is all you need. Adv. Neural. Inf. Process. Syst. 30, 30–40 (2017)
Bengio, S., Vinyals, O., Jaitly, N., Shazeer, N.: Scheduled sampling for sequence prediction with recurrent neural networks. Adv. Neural. Inf. Process. Syst. 28, 28–36 (2015)
Li, S., Lei, D., Qin, P., Wang, W.Y.: Deep reinforcement learning with distributional semantic rewards for abstractive summarization. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 6038–6044 (2019)
Wiseman, S., Rush, A.M.: Sequence-to-sequence learning as beam-search optimization. arXiv preprint arXiv:1606.02960 (2016)
Cohen, E., Beck, J.C.: Empirical analysis of beam search performance degradation in neural sequence models. In: International Conference on Machine Learning, pp. 1290–1299 (2019)
Liu, Y., Liu, P.: SimCLS: a simple framework for contrastive learning of abstractive summarization. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pp. 1065–1072 (2021)
Liu, Y., et al.: Roberta: a robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692 (2019)
Ravaut, M., Joty, S., Chen, N.: SummaReranker: a multi-task mixture-of-experts re-ranking framework for abstractive summarization. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 4504–4524 (2022)
Shen, W., et al.: Joint generator-ranker learning for natural language generation. arXiv preprint arXiv:2206.13974 (2022)
Dou, Z.Y., Liu, P., Hayashi, H., Jiang, Z., Neubig, G.: GSum: a general framework for guided neural abstractive summarization. In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 4830–4842 (2021)
Sun, S., Li, W.: Alleviating exposure bias via contrastive learning for abstractive text summarization. arXiv preprint arXiv:2108.11846 (2021)
Xu, S., Zhang, X., Wu, Y., Wei, F.: Sequence level contrastive learning for text summarization. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 11556–11565 (2022)
Cao, S., Wang, L.: CLIFF: Contrastive learning for improving faithfulness and factuality in abstractive summarization. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 6633–6649 (2021)
Holtzman, A., Buys, J., Du, L., Forbes, M., Choi, Y.: The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751 (2019)
Vijayakumar, A.K., Cogswell, M., Selvaraju, R.R., Sun, Q., Lee, S., Crandall, D., Batra, D.: Diverse beam search: Decoding diverse solutions from neural sequence models. arXiv preprint arXiv:1610.02424 (2016)
See, A., Liu, P.J., Manning, C.D.: Get to the point: summarization with pointer-generator networks. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1073–1083 (2017)
Narayan, S., Cohen, S.B., Lapata, M.: Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 1797–1807 (2018)
Hu, B., Chen, Q., Zhu, F.: LCSTS: a large scale Chinese short text summarization dataset. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pp. 1967–1972 (2015)
Liu, Y., Liu, P., Radev, D., Neubig, G.: BRIO: bringing order to abstractive summarization. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 2890–2903 (2022)
Wan, B., Tang, Z., Yang, L.: Lexicon-constrained copying network for Chinese abstractive summarization. arXiv preprint arXiv:2010.08197 (2020)
Wang, L., Yao, J., Tao, Y., Zhong, L., Liu, W., Du, Q.: A reinforced topic-aware convolutional sequence-to-sequence model for abstractive text summarization. In: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-2018), pp. 4453–4460 (2018)
Kryscinski, W., McCann, B., Xiong, C., Socher, R.: Evaluating the factual consistency of abstractive text summarization. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 9332–9346 (2020)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Yue, S., Yu, D., Xie, D. (2023). A Likelihood Probability-Based Online Summarization Ranking Model. In: Yang, X., et al. Advanced Data Mining and Applications. ADMA 2023. Lecture Notes in Computer Science(), vol 14177. Springer, Cham. https://doi.org/10.1007/978-3-031-46664-9_23
Download citation
DOI: https://doi.org/10.1007/978-3-031-46664-9_23
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-46663-2
Online ISBN: 978-3-031-46664-9
eBook Packages: Computer ScienceComputer Science (R0)