
Abstract
Class activation mapping (CAM) methods have achieved great model explainability performance for CNNs. However, these methods do not perform so well for Transformers, whose architectures are fundamentally different from CNNs. Instead, gradient-weighted attention visualization methods, with effective consideration for the self-attention and skip-connection, achieve very promising explainability for Transformers. These methods compute gradients by back-propagation to achieve class-specific and accurate explainability. In this work, to further increase the accuracy and efficiency in Transformer explainability, we propose a novel method which is both class-specific and gradient-free. The token importance is calculated using Shapley value method, which has a solid base on game theory but is conventionally very computational expensive to use in practice. To calculate the Shapley value accurately and efficiently for each token, we decouple the self-attention from the information flow in Transformers and freeze other unrelated values. In this way, we construct a linear version of Transformer so that the Shapley values can be calculated conveniently. Using Shapley values for explainability, our method not only improves the explainability further but also becomes class-specific without using gradients, surpassing other gradient-based methods in both accuracy and efficiency. Furthermore, we show that explainability methods for CNNs and Transformers can be bridged under the 1st-order Taylor expansion of our method, resulting in (1) a significant explainability improvement for a modified GradCAM method in Transformers and (2) new insights into understanding the existing gradient-based attention visualization methods. Extensive experiments show that our method is superior compared to state-of-the-arts methods. Our code will be made available.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
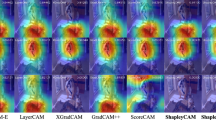
Similar content being viewed by others


Notes
- 1.
Only computes SHAP values for the last layer.
References
Abnar, S., Zuidema, W.H.: Quantifying attention flow in transformers. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020, pp. 4190–4197. Association for Computational Linguistics (2020)
Bach, S., Binder, A., Montavon, G., Klauschen, F., M ̈uller, K.R., Samek, W.: On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PloS one 10(7), e0130140 (2015)
Binder, A., Montavon, G., Lapuschkin, S.: Layer-wise relevance propagation for neural networks with local renormalization layers. In: Villa, A.E.P., Masulli. P. (eds.) ICANN 2016. LNCS, vol. 9887, pp. 63–71. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-44781-0_8
Chattopadhyay, A., Sarkar, A., Howlader, P., Balasubramanian, V.N.: Grad- cam++: generalized gradient-based visual explanations for deep convolutional networks. In: 2018 IEEE Winter Conference on Applications of Computer Vision, WACV 2018, Lake Tahoe, NV, USA, 12–15 March 2018, pp. 839–847. IEEE Computer Society (2018)
Chefer, H., Gur, S., Wolf, L.: Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers. In: 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10- 17 October 2021, pp. 387–396. IEEE (2021)
Chefer, H., Gur, S., Wolf, L.: Transformer interpretability beyond attention visualization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 782–791 (2021)
Devlin, J., Chang, M., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: Burstein, J., Doran, C., Solorio, T. (eds.) Proceedings of the 2019 Conference of the North American Chapter ofthe Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019, Volume 1 (Long and Short Papers), pp. 4171–4186. Association for Computational Linguistics (2019)
Dosovitskiy, A., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. OpenReview.net (2021)
Fu, R., Hu, Q., Dong, X., Guo, Y., Gao, Y., Li, B.: Axiom-based grad-cam: Towards accurate visualization and explanation of cnns. In: 31st British Machine Vision Conference 2020, BMVC 2020, Virtual Event, UK, 7–10 September 2020. BMVA Press (2020)
Guillaumin, M., K ̈uttel, D., Ferrari, V.: Imagenet auto-annotation with segmentation propagation. Int. J. Comput. Vis. 110(3), 328–348 (2014)
Lundberg, S.M., Lee, S.: A unified approach to interpreting model predictions. In: Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R. (eds.) Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, 4–9 December 2017, Long Beach, CA, USA, pp. 4765–4774 (2017)
Montavon, G., Lapuschkin, S., Binder, A., Samek, W., M ̈uller, K.R.: Explaining nonlinear classification decisions with deep, taylor, decomposition. Pattern Recogn. 65, 211–222 (2017)
Radford, A., et al.: Learning transferable visual models from natural language supervision. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18–24 July 2021, Virtual Event. Proceedings of Machine Learning Research, vol. 139, pp. 8748–8763. PMLR (2021)
Russakovsky, O., et al.: Imagenet large scale visual recognition challenge. Int. J. Comput. Vis.Comput. Vis. 115(3), 211–252 (2015)
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad- cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 618–626 (2017)
Sundararajan, M., Taly, A., Yan, Q.: Axiomatic attribution for deep networks. In: International Conference on Machine Learning, pp. 3319–3328. PMLR (2017)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems, pp. 5998–6008 (2017)
Voita, E., Talbot, D., Moiseev, F., Sennrich, R., Titov, I.: Analyzing multi-headself-attention: Specialized heads do the heavy lifting, the rest can be pruned. In: Korhonen, A., Traum, D.R., M`arquez, L. (eds.) Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July- 2 August, 2019, Volume 1: Long Papers, pp. 5797–5808. Association for Computational Linguistics (2019)
Yuan, T., Li, X., Xiong, H., Cao, H., Dou, D.: Explaining information flow inside vision transformers using markov chain. In: Explainable AI Approaches Fordebugging And Diagnosis (2021)
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Learning deep features for discriminative localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2921–2929 (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Sun, T., Chen, H., Qiu, Y., Zhao, C. (2023). Efficient Shapley Values Calculation for Transformer Explainability. In: Lu, H., Blumenstein, M., Cho, SB., Liu, CL., Yagi, Y., Kamiya, T. (eds) Pattern Recognition. ACPR 2023. Lecture Notes in Computer Science, vol 14406. Springer, Cham. https://doi.org/10.1007/978-3-031-47634-1_5
Download citation
DOI: https://doi.org/10.1007/978-3-031-47634-1_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-47633-4
Online ISBN: 978-3-031-47634-1
eBook Packages: Computer ScienceComputer Science (R0)