
Abstract
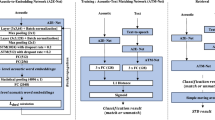
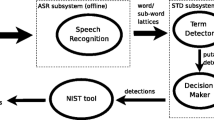
The paper presents a method for spoken term detection based on the Transformer architecture. We propose the encoder-encoder architecture employing two BERT-like encoders with additional modifications, including attention masking, convolutional and upsampling layers. The encoders project a recognized hypothesis and a searched term into a shared embedding space, where the score of the putative hit is computed using the calibrated dot product. In the experiments, we used the Wav2Vec 2.0 speech recognizer. The proposed system outperformed a baseline method based on deep LSTMs on the English and Czech STD datasets based on USC Shoah Foundation Visual History Archive (MALACH).
This research was supported by the Ministry of the Interior of the Czech Republic, project No. VJ01010108 and by the Czech Science Foundation (GA CR), project No. GA22-27800S.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Baevski, A., Zhou, H., Mohamed, A., Auli, M.: Wav2Vec 2.0: a framework for self-supervised learning of speech representations. In: Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS 2020. Curran Associates Inc., Red Hook, NY, USA (2020)
Berg, A., O’Connor, M., Cruz, M.T.: Keyword transformer: a self-attention model for keyword spotting. In: Proceedings of Interspeech 2021, pp. 4249–4253 (2021). https://doi.org/10.21437/Interspeech.2021-1286
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
Ding, K., Zong, M., Li, J., Li, B.: LETR: a lightweight and efficient transformer for keyword spotting. In: ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7987–7991 (2022). https://doi.org/10.1109/ICASSP43922.2022.9747295
Gillioz, A., Casas, J., Mugellini, E., Khaled, O.A.: Overview of the transformer-based models for NLP tasks. In: 2020 15th Conference on Computer Science and Information Systems (FedCSIS), pp. 179–183 (2020). https://doi.org/10.15439/2020F20
Google Research: TensorFlow code and pre-trained models for BERT, March 2020. https://github.com/google-research/bert
Hendrycks, D., Gimpel, K.: Gaussian Error Linear Units (GELUs). arXiv preprint arXiv:1606.08415 (2016)
Karita, S., et al.: A comparative study on transformer vs RNN in speech applications. In: 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 449–456 (2019). https://doi.org/10.1109/ASRU46091.2019.9003750
Lehečka, J., Švec, J., Prazak, A., Psutka, J.: Exploring capabilities of monolingual audio transformers using large datasets in automatic speech recognition of Czech. In: Proceedings of Interspeech 2022, pp. 1831–1835 (2022). https://doi.org/10.21437/Interspeech.2022-10439
Liu, Y., et al.: RoBERTa: a robustly optimized BERT pretraining approach. arXiv (1), July 2019. http://arxiv.org/abs/1907.11692
Luo, Z., et al.: DecBERT: enhancing the language understanding of BERT with causal attention masks. In: Findings of the Association for Computational Linguistics: NAACL 2022, pp. 1185–1197. Association for Computational Linguistics, Seattle, United States, July 2022. https://doi.org/10.18653/v1/2022.findings-naacl.89, https://aclanthology.org/2022.findings-naacl.89
Meta Research: Wav2Vec 2.0, April 2022. https://github.com/facebookresearch/fairseq/blob/main/examples/wav2vec/README.md
Ott, M., et al.: fairseq: a fast, extensible toolkit for sequence modeling. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), pp. 48–53. Association for Computational Linguistics, Minneapolis, Minnesota, June 2019. https://doi.org/10.18653/v1/N19-4009, https://aclanthology.org/N19-4009
Psutka, J., Radová, V., Ircing, P., Matoušek, J., Müller, L.: USC-SFI MALACH Interviews and Transcripts Czech LDC2014S04. Linguistic Data Consortium, Philadelphia (2014). https://catalog.ldc.upenn.edu/LDC2014S04
Ramabhadran, B., et al.: USC-SFI MALACH Interviews and Transcripts English LDC2012S05. Linguistic Data Consortium, Philadelphia (2012). https://catalog.ldc.upenn.edu/LDC2012s05 (2012)
Settle, S., Livescu, K.: Discriminative acoustic word embeddings: recurrent neural network-based approaches. In: 2016 IEEE Spoken Language Technology Workshop (SLT), pp. 503–510 (2016). https://doi.org/10.1109/SLT.2016.7846310
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems, pp. 5999–6009 (2017)
Wang, Y., Lv, H., Povey, D., Xie, L., Khudanpur, S.: Wake word detection with streaming transformers. In: ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5864–5868 (2021). https://doi.org/10.1109/ICASSP39728.2021.9414777
Wegmann, S., Faria, A., Janin, A., Riedhammer, K., Morgan, N.: The TAO of ATWV: probing the mysteries of keyword search performance. In: 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, ASRU 2013 - Proceedings, pp. 192–197 (2013). https://doi.org/10.1109/ASRU.2013.6707728
Yang, D., et al.: CaTT-KWS: a multi-stage customized keyword spotting framework based on cascaded transducer-transformer. In: Proceedings of Interspeech 2022, pp. 1681–1685 (2022). https://doi.org/10.21437/Interspeech.2022-10258
Yuan, Y., Xie, L., Leung, C.C., Chen, H., Ma, B.: Fast query-by-example speech search using attention-based deep binary embeddings. IEEE/ACM Trans. Audio Speech Lang. Process. 28, 1988–2000 (2020). https://doi.org/10.1109/TASLP.2020.2998277
Švec, J., Lehečka, J., Šmídl, L.: Deep LSTM spoken term detection using Wav2Vec 2.0 recognizer. In: Proceedings of Interspeech 2022, pp. 1886–1890 (2022). https://doi.org/10.21437/Interspeech.2022-10409
Švec, J., Psutka, J.V., Šmídl, L., Trmal, J.: A relevance score estimation for spoken term detection based on RNN-generated pronunciation embeddings. In: Proceedings of Interspeech 2017, pp. 2934–2938 (2017). https://doi.org/10.21437/Interspeech.2017-1087
Švec, J., Šmídl, L., Psutka, J.V., Pražák, A.: Spoken term detection and relevance score estimation using dot-product of pronunciation embeddings. In: Proceedings of Interspeech 2021, pp. 4398–4402 (2021). https://doi.org/10.21437/Interspeech.2021-1704
Acknowledgement
Computational resources were supplied by the project “e-Infrastruktura CZ” (e-INFRA CZ LM2018140) supported by the Ministry of Education, Youth, and Sports of the Czech Republic.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Švec, J., Šmídl, L., Lehečka, J. (2023). Transformer-Based Encoder-Encoder Architecture for Spoken Term Detection. In: Lu, H., Blumenstein, M., Cho, SB., Liu, CL., Yagi, Y., Kamiya, T. (eds) Pattern Recognition. ACPR 2023. Lecture Notes in Computer Science, vol 14408. Springer, Cham. https://doi.org/10.1007/978-3-031-47665-5_28
Download citation
DOI: https://doi.org/10.1007/978-3-031-47665-5_28
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-47664-8
Online ISBN: 978-3-031-47665-5
eBook Packages: Computer ScienceComputer Science (R0)