
Abstract
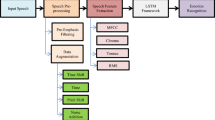
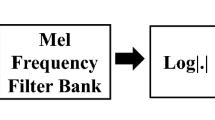
As technology advances, our reliance on machines grows, necessitating the development of effective approaches for Speech Emotion Recognition (SER) to enhance human-machine interaction. This paper introduces a novel feature extraction technique called Linear Frequency Residual Cepstral Coefficients (LFRCC) for the SER task. To the best of our knowledge and belief, this is the first attempt to employ LFRCC for SER. Experimental evaluations were conducted on the widely used EmoDB dataset, focusing on four emotions: anger, happiness, neutrality, and sadness. Results demonstrated that the proposed LFRCC features outperform state-of-the-art Mel Frequency Cepstral Coefficients (MFCC) and Linear Frequency Cepstral Coefficients (LFCC) relatively by a significant margin: 25.64 % and 10.26 %, respectively, when using a residual neural network (ResNet); and 12.37 % and 4.67 %, respectively when combined with the Time-Delay Neural Network (TDNN) as classifier. Furthermore, the proposed LFRCC features exhibit a better Equal Error Rate (EER) than the other two baseline methods. Additionally, classifier-level and score-level fusion techniques were employed, and the combination of MFCC and LFRCC at the score-level achieved the highest accuracy of 94.87 % and the lowest EER of 3.625%. The better performance of the proposed feature set may be due to its capability to capture excitation source information via linearly-spaced subbands in the cepstral domain.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Akçay, M.B., Oğuz, K.: Speech emotion recognition: emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 116, 56–76 (2020)
Anagnostopoulos, C.N., Iliou, T., Giannoukos, I.: Features and classifiers for emotion recognition from speech: a survey from 2000 to 2011. Artif. Intell. Rev. 43, 155–177 (2015)
Bhangale, K., Kothandaraman, M.: Speech emotion recognition based on multiple acoustic features and deep convolutional neural network. Electronics 12(4), 839 (2023)
Burkhardt, F., Paeschke, A., Rolfes, M., Sendlmeier, W.F., Weiss, B., et al.: A database of german emotional speech. In: Interspeech, Lisbon, Portugal, vol. 5, pp. 1517–1520 (2005)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, pp. 770–778 (2016)
Homma, I., Masaoka, Y.: Breathing rhythms and emotions. Exp. Physiol. 93(9), 1011–1021 (2008)
Jerath, R., Beveridge, C.: Respiratory rhythm, autonomic modulation, and the spectrum of emotions: the future of emotion recognition and modulation. Front. Psychol. 11, 1980 (2020)
Koolagudi, S.G., Reddy, R., Rao, K.S.: Emotion recognition from speech signal using epoch parameters. In: International Conference on Signal Processing and Communications (SPCOM), pp. 1–5. IISc Bangalore, India (2010)
Krothapalli, S.R., Koolagudi, S.G.: Characterization and recognition of emotions from speech using excitation source information. Int. J. Speech Technol. 16, 181–201 (2013)
Makhoul, J.: Linear prediction: a tutorial review. Proc. IEEE 63(4), 561–580 (1975)
Okabe, K., Koshinaka, T., Shinoda, K.: Attentive statistics pooling for deep speaker embedding. In: Interspeech, Hyderabad, India, pp. 2252–2256 (2018)
Peddinti, V., Povey, D., Khudanpur, S.: A time delay neural network architecture for efficient modeling of long temporal contexts. In: Interspeech, Dresden, Germany, pp. 3214–3218 (2015)
Sadok, S., Leglaive, S., Séguier, R.: A vector quantized masked autoencoder for speech emotion recognition. In: 2023 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), pp. 1–5 (2023)
Scherer, K.R.: Vocal communication of emotion: a review of research paradigms. Speech Commun. 40(1–2), 227–256 (2003)
Swain, M., Routray, A., Kabisatpathy, P.: Databases, features and classifiers for speech emotion recognition: a review. Int. J. Speech Technol. 21(1), 93–120 (2018). https://doi.org/10.1007/s10772-018-9491-z
Tak, H., Patil, H.A.: Novel linear frequency residual cepstral features for replay attack detection. In: Interspeech, Hyderabad, India, pp. 726–730 (2018)
Tripathi, S., Kumar, A., Ramesh, A., Singh, C., Yenigalla, P.: Focal loss based residual convolutional neural network for speech emotion recognition. arXiv preprint arXiv:1906.05682 (2019)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Hora, B.S., Uthiraa, S., Patil, H.A. (2023). Linear Frequency Residual Cepstral Coefficients for Speech Emotion Recognition. In: Karpov, A., Samudravijaya, K., Deepak, K.T., Hegde, R.M., Agrawal, S.S., Prasanna, S.R.M. (eds) Speech and Computer. SPECOM 2023. Lecture Notes in Computer Science(), vol 14338. Springer, Cham. https://doi.org/10.1007/978-3-031-48309-7_10
Download citation
DOI: https://doi.org/10.1007/978-3-031-48309-7_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-48308-0
Online ISBN: 978-3-031-48309-7
eBook Packages: Computer ScienceComputer Science (R0)