
Abstract
The work presented in this paper focuses on zero-resource children’s speech recognition task. In such tasks, adults’ speech data is used for learning the acoustic models. However, this leads to severe acoustic mismatch and hence poor recognition rates. One of the main mismatch factor is that the pitch values are higher in the case of children’s speech. In order to mitigate the ill-effects of pitch-induced acoustic mismatch, two front-end speech parameterization techniques are proposed in this study. The proposed approaches employ spectral smoothing based on either pitch-adaptive cepstral truncation or variational mode decomposition. Furthermore, we have used Gamma-tone-filterbank for warping the spectra to the ERB scale. Consequently, the cepstral coefficients exhibit lower variance than those obtained using Mel-filterbank. Therefore, the proposed features are observed to be very effective resulting in a relative reduction in word error rate by nearly \(17\%\) over the baseline.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
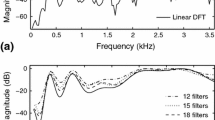
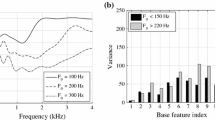

References
Batliner, A., et al.: The PF_STAR children’s speech corpus. In: Proceedings of INTERSPEECH, pp. 2761–2764 (2005)
Damskägg, E.P., Välimäki, V.: Audio time stretching using fuzzy classification of spectral bins. Appl. Sci. 7(12), 1293 (2017). https://doi.org/10.3390/app7121293
D’Arcy, S., Russell, M.: A comparison of human and computer recognition accuracy for children’s speech. In: Proceedings of INTERSPEECH, pp. 2197–2200 (2005)
Dragomiretskiy, K., Zosso, D.: Variational mode decomposition. IEEE Trans. Signal Process. 62(3), 531–544 (2013)
Gerosa, M., Giuliani, D., Narayanan, S., Potamianos, A.: A review of ASR technologies for children’s speech. In: Proceedings of Workshop on Child, Computer and Interaction, pp. 7:1–7:8 (2009). https://doi.org/10.1145/1640377.1640384
Gold, B., Morgan, N., Ellis, D., O’Shaughnessy, D.: Speech and audio signal processing: Processing and perception of speech and music, second edition. J. Acoust. Soc. Am. 132, 1861 (2012). https://doi.org/10.1121/1.4742973
Kumar, V., Kumar, A., Shahnawazuddin, S.: Creating robust children’s ASR system in zero-resource condition through out-of-domain data augmentation. Circ. Syst. Signal Process. 41(4), 2205–2220 (2021). https://doi.org/10.1007/s00034-021-01885-5
Kumar Kathania, H., Reddy Kadiri, S., Alku, P., Kurimo, M.: Study of formant modification for children ASR. In: ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7429–7433 (2020). https://doi.org/10.1109/ICASSP40776.2020.9053334
Lee, S., Potamianos, A., Narayanan, S.S.: Acoustics of children’s speech: developmental changes of temporal and spectral parameters. J. Acoust. Soc. Am. 105(3), 1455–1468 (1999). https://doi.org/10.1121/1.426686
Makhoul, J.: Linear prediction: a tutorial review. Proc. IEEE 63(4), 561–580 (1975). https://doi.org/10.1109/PROC.1975.9792
Patterson, R., Nimmo-Smith, I., Holdsworth, J., Rice, P.: An efficient auditory filterbank based on the gammatone function (1987)
Peddinti, V., Povey, D., Khudanpur, S.: A time delay neural network architecture for efficient modeling of long temporal contexts. In: Proceedings of INTERSPEECH (2015)
Potaminaos, A., Narayanan, S.: Robust recognition of children speech. IEEE Trans. Speech Audio Process. 11(6), 603–616 (2003). https://doi.org/10.1109/TSA.2003.818026
Povey, D., et al.: The Kaldi Speech recognition toolkit. In: Proceedings of ASRU (2011)
Povey, D., et al.: Purely sequence-trained neural networks for ASR based on lattice-free MMI. In: Proceedings of INTERSPEECH, pp. 2751–2755 (2016)
Robinson, T., Fransen, J., Pye, D., Foote, J., Renals, S.: WSJCAM0: a British English speech corpus for large vocabulary continuous speech recognition. In: Proceedings of ICASSP, vol. 1, pp. 81–84 (1995). https://doi.org/10.1109/ICASSP.1995.479278
Russell, M., D’Arcy, S.: Challenges for computer recognition of children’s speech. In: Proceedings of Speech and Language Technologies in Education (SLaTE) (2007)
Serizel, R., Giuliani, D.: Deep-neural network approaches for speech recognition with heterogeneous groups of speakers including children. Nat. Lang. Eng. 23(3), 325–350 (2017). https://doi.org/10.1017/S135132491600005X
Shahnawazuddin, S., Adiga, N., Kathania, H.K., Sai, B.T.: Creating speaker independent ASR system through prosody modification based data augmentation. Pattern Recogn. Lett. 131, 213–218 (2020). https://doi.org/10.1016/j.patrec.2019.12.019
Shahnawazuddin, S., Adiga, N., Kumar, K., Poddar, A., Ahmad, W.: Voice conversion based data augmentation to improve children’s speech recognition in limited data scenario. In: Proceedings of INTERSPEECH, pp. 4382–4386 (2020). https://doi.org/10.21437/Interspeech.2020-1112
Shahnawazuddin, S., Adiga, N., Sai, B.T., Ahmad, W., Kathania, H.K.: Developing speaker independent ASR system using limited data through prosody modification based on fuzzy classification of spectral bins. Digital Signal Process. 93, 34–42 (2019). https://doi.org/10.1016/j.dsp.2019.06.015
Sinha, R., Shahnawazuddin, S.: Assessment of pitch-adaptive front-end signal processing for children’s speech recognition. Comput. Speech Lang. 48, 103–121 (2018). https://doi.org/10.1016/j.csl.2017.10.007
Slaney, M., et al.: An efficient implementation of the Patterson-Holdsworth auditory filter bank. Apple Computer, Perception Group, Technical Report, vol. 35, no. 8 (1993)
Waibel, A., Hanazawa, T., Hinton, G., Shikano, K., Lang, K.: Phoneme recognition using time-delay neural networks. IEEE Trans. Acoust. Speech Signal Process. 37(3), 328–339 (1989). https://doi.org/10.1109/29.21701
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Shahnawazuddin, S., Ankita, Kumar, A., Kathania, H.K. (2023). Gammatone-Filterbank Based Pitch-Normalized Cepstral Coefficients for Zero-Resource Children’s ASR. In: Karpov, A., Samudravijaya, K., Deepak, K.T., Hegde, R.M., Agrawal, S.S., Prasanna, S.R.M. (eds) Speech and Computer. SPECOM 2023. Lecture Notes in Computer Science(), vol 14338. Springer, Cham. https://doi.org/10.1007/978-3-031-48309-7_40
Download citation
DOI: https://doi.org/10.1007/978-3-031-48309-7_40
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-48308-0
Online ISBN: 978-3-031-48309-7
eBook Packages: Computer ScienceComputer Science (R0)