
Abstract
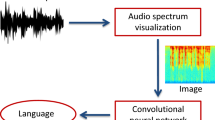
Native langauge identification involves identifying the mother tongue of a person from an audio recording of their speech in second language. Improving native language identification holds potential in advancing the development of more sophisticated human-computer interfaces that rely on audio inputs. Automatic speech recognition systems show a downgrade in performance when used on non-native speech, this can be mitigated by using L1 identification. Presently, the majority of research efforts in L1 identification have concentrated on employing Convolutional Neural Networks (CNNs) on audio spectrograms to predict the native language. With the emergence of Vision Transformers, which have demonstrated exceptional performance in object identification, we have adopted a modified version of the Vision Transformer model to analyze audio spectrograms for L1 identification. This approach has yielded promising outcomes on the NISP dataset which contains audio recordings of English speech of 5 regional lannguages(Hindi, Tamil, Telugu, Kannada, Malayalam) of 345 speakers. The proposed model was able to achieve an overall accuracy of 97.87% on the test dataset.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Dosovitskiy, A., et al.: An image is worth 16x16 words: transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
Gong, Y., Chung, Y.A., Glass, J.: AST: audio spectrogram transformer. arXiv preprint arXiv:2104.01778 (2021)
Gong, Y., Lai, C.I., Chung, Y.A., Glass, J.: SSAST: self-supervised audio spectrogram transformer. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 10699–10709 (2022)
Graham, C.: L1 identification from L2 speech using neural spectrogram analysis. In: Interspeech, vol. 2021, pp. 3959–3963 (2021)
Guntur, R.K., Ramakrishnan, K., Vinay Kumar, M.: An automated classification system based on regional accent. Circuits Syst. Signal Process 41(6), 3487–3507 (2022)
Humayun, M.A., Yassin, H., Abas, P.E.: Native language identification for Indian-speakers by an ensemble of phoneme-specific, and text-independent convolutions. Speech Commun. 139, 92–101 (2022)
Jiao, Y., Tu, M., Berisha, V., Liss, J.M.: Accent identification by combining deep neural networks and recurrent neural networks trained on long and short term features. In: Interspeech, pp. 2388–2392 (2016)
Kürzinger, L., Winkelbauer, D., Li, L., Watzel, T., Rigoll, G.: CTC-Segmentation of large corpora for German end-to-end speech recognition. In: Karpov, A., Potapova, R. (eds.) SPECOM 2020. LNCS (LNAI), vol. 12335, pp. 267–278. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-60276-5_27
Rajpal, A., Patel, T.B., Sailor, H.B., Madhavi, M.C., Patil, H.A., Fujisaki, H.: Native language identification using spectral and source-based features. In: Interspeech, pp. 2383–2387 (2016)
Schuller, B., et al.: The interspeech 2016 computational paralinguistics challenge: Deception, sincerity & native language. In: 17TH Annual Conference of the International Speech Communication Association (Interspeech 2016), Vols. 1–5, vol. 8, pp. 2001–2005. ISCA (2016)
Ubale, R., Qian, Y., Evanini, K.: Exploring end-to-end attention-based neural networks for native language identification. In: 2018 IEEE Spoken Language Technology Workshop (SLT), pp. 84–91. IEEE (2018)
Ubale, R., Ramanarayanan, V., Qian, Y., Evanini, K., Leong, C.W., Lee, C.M.: Native language identification from raw waveforms using deep convolutional neural networks with attentive pooling. In: 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 403–410. IEEE (2019)
Watzel, T., Kürzinger, L., Li, L., Rigoll, G.: Synchronized forward-backward transformer for end-to-end speech recognition. In: Karpov, A., Potapova, R. (eds.) SPECOM 2020. LNCS (LNAI), vol. 12335, pp. 646–656. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-60276-5_62
Watzel, T., Kürzinger, L., Li, L., Rigoll, G.: Induced local attention for transformer models in speech recognition. In: Karpov, A., Potapova, R. (eds.) SPECOM 2021. LNCS (LNAI), vol. 12997, pp. 795–806. Springer, Cham (2021). https://doi.org/10.1007/978-3-030-87802-3_71
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Pipariya, K., Pramanik, D., Bharati, P., Chandra, S., Mandal, S.K.D. (2023). End-to-End Native Language Identification Using a Modified Vision Transformer(ViT) from L2 English Speech. In: Karpov, A., Samudravijaya, K., Deepak, K.T., Hegde, R.M., Agrawal, S.S., Prasanna, S.R.M. (eds) Speech and Computer. SPECOM 2023. Lecture Notes in Computer Science(), vol 14339. Springer, Cham. https://doi.org/10.1007/978-3-031-48312-7_42
Download citation
DOI: https://doi.org/10.1007/978-3-031-48312-7_42
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-48311-0
Online ISBN: 978-3-031-48312-7
eBook Packages: Computer ScienceComputer Science (R0)