
Abstract
As one of the key problems in computer-aided medical image analysis, learning how to model global relationships and extract local details is crucial to improve the performance of abdominal multi-organ segmentation. While current techniques for Convolutional Neural Networks (CNNs) are quite mature, their limited receptive field makes it difficult to balance the ability to capture global relationships with local details, especially when stacked onto deeper networks. Thus, several recent works have proposed Vision Transformer based on a self-attentive mechanism and used it for abdominal multi-organ segmentation. However, Vision Transformer is computationally expensive by modeling long-range relationships on pairs of patches. To address these issues, we propose a novel multi-organ segmentation framework, named GDTNet, based on the synergy of CNN and Transformer for mining global relationships and local details. To achieve this goal, we innovatively design a Dilated Attention Module (DAM) that can efficiently capture global contextual features and construct global semantic information. Specifically, we employ a three-parallel branching structure to model the global semantic information of multiscale encoded features by Dilated Transformer, combined with global average pooling under the supervision of Gate Attention. In addition, we fuse each DAM with DAMs from all previous layers to further encode features between scales. Extensive experiments on the Synapse dataset show that our method outperforms ten other state-of-the-art segmentation methods, achieving accurate segmentation of multiple organs in the abdomen.
C. Zhang and Z. Wang—These authors contributed equally to this paper.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
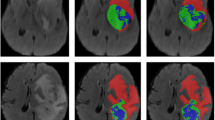

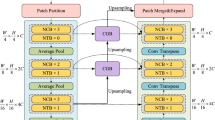
References
Cao, H., et al.: Swin-unet: Unet-like pure transformer for medical image segmentation. In: Karlinsky, L., Michaeli, T., Nishino, K. (eds.) ECCV 2022. LNCS, vol. 13803, pp. 205–218. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-25066-8_9
Chen, J., et al.: Transunet: transformers make strong encoders for medical image segmentation (2021)
DENG, J.: A large-scale hierarchical image database. Proc. IEEE Comput. Vision Pattern Recogn. 2009 (2009)
Dosovitskiy, A., et al.: An image is worth 16x16 words: transformers for image recognition at scale (2021)
Gibson, E., et al.: Automatic multi-organ segmentation on abdominal CT with dense v-networks. IEEE Trans. Med. Imaging 37(8), 1822–1834 (2018)
Heidari, M., et al.: Hiformer: hierarchical multi-scale representations using transformers for medical image segmentation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 6202–6212 (January 2023)
Huang, H., et al.: Scaleformer: revisiting the transformer-based backbones from a scale-wise perspective for medical image segmentation (2022)
Huang, X., Deng, Z., Li, D., Yuan, X.: Missformer: an effective medical image segmentation transformer (2021)
Jin, Q., Meng, Z., Pham, T.D., Chen, Q., Wei, L., Su, R.: Dunet: a deformable network for retinal vessel segmentation. Knowl.-Based Syst. 178, 149–162 (2019)
Lian, S., Luo, Z., Zhong, Z., Lin, X., Su, S., Li, S.: Attention guided u-net for accurate iris segmentation. J. Vis. Commun. Image Represent. 56, 296–304 (2018)
Liu, Z., et al.: Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 10012–10022, October 2021
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015
Ronneberger, O., Fischer, P., Brox, T.: U-net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Srivastava, R.K., Greff, K., Schmidhuber, J.: Highway networks (2015)
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jegou, H.: Training data-efficient image transformers & distillation through attention. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 139, pp. 10347–10357. PMLR, 18–24 July 2021
Vaswani, A., et al.: Attention is all you need. In: Guyon, I., et al. (eds.) Advances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc. (2017)
Wang, H., Cao, P., Wang, J., Zaiane, O.R.: Uctransnet: rethinking the skip connections in u-net from a channel-wise perspective with transformer. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, mo. 3, pp. 2441–2449 (2022)
Wang, H., et al.: Mixed transformer u-net for medical image segmentation. In: ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2390–2394 (2022)
Wang, W., et al.: Pyramid vision transformer: a versatile backbone for dense prediction without convolutions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 568–578, October 2021
Xie, Y., Huang, Y., Zhang, Y., Li, X., Ye, X., Hu, K.: Transwnet: integrating transformers into CNNs via row and column attention for abdominal multi-organ segmentation. In: ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5 (2023)
Xu, G., Wu, X., Zhang, X., He, X.: Levit-unet: make faster encoders with transformer for medical image segmentation (2021)
Yan, X., Tang, H., Sun, S., Ma, H., Kong, D., Xie, X.: After-unet: axial fusion transformer unet for medical image segmentation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 3971–3981 (January 2022)
Zhou, Z., Siddiquee, M.M.R., Tajbakhsh, N., Liang, J.: Unet++: redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 39(6), 1856–1867 (2020)
Zhu, X., Lyu, S., Wang, X., Zhao, Q.: Tph-yolov5: improved yolov5 based on transformer prediction head for object detection on drone-captured scenarios (2021)
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grants 62272404 and 62372170, in part by the Open Project of Key Laboratory of Medical Imaging and Artificial Intelligence of Hunan Province under Grant YXZN2022004, in part by the Natural Science Foundation of Hunan Province of China under Grants 2022JJ30571 and 2023JJ40638, in part by the Research Foundation of Education Department of Hunan Province under Grant 21B0172, in part by the Innovation and Entrepreneurship Training Program for China University Students under Grant 202210530002, and in part by the Baidu Program.
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Zhang, C., Wang, Z., Zhang, Y., Li, X., Hu, K. (2024). GDTNet: A Synergistic Dilated Transformer and CNN by Gate Attention for Abdominal Multi-organ Segmentation. In: Rudinac, S., et al. MultiMedia Modeling. MMM 2024. Lecture Notes in Computer Science, vol 14557. Springer, Cham. https://doi.org/10.1007/978-3-031-53302-0_4
Download citation
DOI: https://doi.org/10.1007/978-3-031-53302-0_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-53301-3
Online ISBN: 978-3-031-53302-0
eBook Packages: Computer ScienceComputer Science (R0)