
Abstract
Large-scale datasets have made impressive progress in deep learning. However, storing datasets and training neural network models on large datasets have become increasingly expensive. In this paper, we present an effective dataset compression approach based on the matrix product states (short as MPS) and knowledge distillation. MPS can decompose image samples into a sequential product of tensors to achieve task-agnostic image compression by preserving the low-rank information of the images. Based on this property, we use multiple MPS to represent the image datasets samples. Meanwhile, we also designed a task-related component based on knowledge distillation to enhance the generality of the compressed dataset. Extensive experiments have demonstrated the effectiveness of the proposed approach in image datasets compression, especially obtaining better model performance (2.26\(\%\) on average) than the best baseline method on the same compression ratio.
Z.F. Gao and P. Liu–Authors contributed equally.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

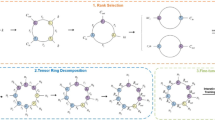

Notes
- 1.
Available at https://www.cs.toronto.edu/~kriz/cifar.html.
- 2.
Available at https://www.worldlink.com.cn/en/osdir/fashion-mnist.html.
References
Agarwal, P.K., Har-Peled, S., Varadarajan, K.R.: Approximating extent measures of points. J. ACM 51(4), 606–635 (2004)
Aljundi, R., Lin, M., Goujaud, B., Bengio, Y.: Gradient based sample selection for online continual learning. In: Hanna, M., et al. (eds.), Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, 8-14 December 2019, Vancouver, BC, Canada, pp. 11816–11825 (2019)
Ba, J., Caruana, R.: Do deep nets really need to be deep? In: Zoubin, G., Max, W., Corinna, C., Neil, D.L., Kilian, Q.W. (eds.), Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, pp. 2654–2662 (2014)
Bengua, J.A., Phien, H.N., Tuan, H.D.: Optimal feature extraction and classification of tensors via matrix product state decomposition. In: 2015 IEEE International Congress on Big Data, pp. 669–672. IEEE (2015)
Bucilua, C., Caruana, R., Niculescu-Mizil, A.: Model compression. In: Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 535–541 (2006)
Castro, F.M., Marín-Jiménez, M.J., Guil, N., Schmid, C., Alahari, K.: End-to-end incremental learning. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11216, pp. 241–257. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01258-8_15
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: Burstein, J., Doran, C., Solorio, T. (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2-7 June 2019, Volume 1 (Long and Short Papers), pp. 4171–4186. Association for Computational Linguistics (2019)
Fannes, M., Nachtergaele, B., Werner, R.F.: Finitely correlated states on quantum spin chains. Commun. Math. Phys. 144(3), 443–490 (1992)
Gao, Z.F., et al.: Compressing deep neural networks by matrix product operators. Phys. Rev. Res. 2, 023300 (2020)
Gao, Z.F., Liu, P., Zhao, W.X., Lu, Z.Y., Wen, J.R.: Parameter-efficient mixture-of-experts architecture for pre-trained language models. In: Proceedings of the 29th International Conference on Computational Linguistics, pp. 3263–3273 (2022)
Gao, Z.F., Sun, X., Gao, L., Li, J., Lu, Z.Y.: Compressing LSTM networks by matrix product operators. arXiv preprintarXiv:2012.11943 (2020)
Gao, Z.F., Zhou, K., Liu, P., Zhao, W.X., Wen, J.R.: Small pre-trained language models can be fine-tuned as large models via over-parameterization. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 3819–3834 (2023)
Har-Peled, S., Mazumdar, S.: On coresets for k-means and k-median clustering. In: Proceedings of the Thirty-Sixth Annual ACM Symposium on Theory of Computing, pp. 291–300 (2004)
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask R-CNN. In: IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017, pp. 2980–2988. IEEE Computer Society (2017)
Henry, E.R., Hofrichter, J.: [8] singular value decomposition: application to analysis of experimental data. Methods Enzymol. 210, 129–192 (1992)
Hinton, G.E., Osindero, S., Teh, Y.W.: A fast learning algorithm for deep belief nets. Neural Comput. 18, 1527–1554 (2006)
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. CoRR, abs/1503.02531 (2015)
Hitchcock, F.L.: The expression of a tensor or a polyadic as a sum of products. J. Math. Phys. 6(1–4), 164–189 (1927)
Kim, T., Oh, J., Kim, N., Cho, S., Yun, S.Y.: Comparing kullback-leibler divergence and mean squared error loss in knowledge distillation. In: Zhou, Z.-H. (ed.), Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event/Montreal, Canada, 19-27 August 2021, pp. 2628–2635. ijcai.org (2021)
Kim, W., Son, B., Kim, I.: Vilt: vision-and-language transformer without convolution or region supervision. In: Meila, M., Zhang, T. (eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18–24 July 2021, Virtual Event, volume 139 of Proceedings of Machine Learning Research, pp. 5583–5594. PMLR (2021)
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
Latorre, J.I.: Image compression and entanglement. CoRR, abs/quant-ph/0510031 (2005)
LeCun, Y.: Mnist handwritten digit database, yann lecun, corinna cortes and chris burges. http://yannlecun.com/exdb/mnist
Liu, P., Gao, Z.F., Zhao, W.X., Wen, J.R.: Scaling pre-trained language models to deeper via parameter-efficient architecture. arXiv preprint arXiv:2303.16753 (2023)
Liu, P., Gao, Z.F., Zhao, W.X., Xie, Z.Y., Lu, Z.Y., Wen, J.R.: Enabling lightweight fine-tuning for pre-trained language model compression based on matrix product operators. In: Zong, C., Xia, F., Li, W., Navigli, R. (eds.), Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, 1–6 August 2021, pp. 5388–5398. Association for Computational Linguistics (2021)
Neifeld, M.A., Ashok, A., Baheti, P.K.: Task-specific information for imaging system analysis. J. Opt. Soc. Am. A 24(12), B25–B41 (2007)
Nene, S.A., Nayar, S.K., Murase, H., et al.: Columbia object image library (coil-100) (1996)
Perez-Garcia, D., Verstraete, F., Wolf, M.M., Cirac, J.I.: Matrix product state representations. Quantum Inf. Comput. 7(5–6), 401–430 (2007)
Rebuffi, S.A., Kolesnikov, A., Sperl, G., Lampert, C.H.: ICARL: incremental classifier and representation learning. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017, pp. 5533–5542. IEEE Computer Society (2017)
Romero, A., et al.: Fitnets: hints for thin deep nets. In: Bengio, Y., LeCun, Y. (eds.), 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7-9 May 2015, Conference Track Proceedings (2015)
Russakovsky, O., et al.: ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. (IJCV) 115(3), 211–252 (2015)
Russakovsky, O., et al.: ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 115(3), 211–252 (2015)
SainathTN, M.,, et al.: Deep convolutional neural networks for LVCSR. IEEE Int. Conf. Acoust. Speech and Sig. Process. 8614, 8618 (2013)
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. and Chen, L.C.: Mobilenetv2: inverted residuals and linear bottlenecks. In: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018, pp. 4510–4520. Computer Vision Foundation / IEEE Computer Society (2018)
Sener, O., Savarese, S.: Active learning for convolutional neural networks: a core-set approach. In: 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings, OpenReview.net (2018)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: Bengio, Y., LeCun, Y. (eds.), 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7-9 May 2015, Conference Track Proceedings (2015)
Sun, X., Gao, Z.F., Lu, Z.Y., Li, J., Yan, Y.: Yonghong: a model compression method with matrix product operators for speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 28, 2837–2847 (2020)
Sun, X., Gao, Z.F., Lu, Z.Y., Li, J., Yan, Y.: A model compression method with matrix product operators for speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 28, 2837–2847 (2020)
Toneva, M., Sordoni, A., Combes, R.T.D., Trischler, A., Bengio, Y., Gordon, G.J.: An empirical study of example forgetting during deep neural network learning. In: 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6-9 May 2019. OpenReview.net (2019)
Wang, L., Shi, J., Song, G., Shen, I.: Object detection combining recognition and segmentation. In: Yagi, Y., Kang, S.B., Kweon, I.S., Zha, H. (eds.) ACCV 2007. LNCS, vol. 4843, pp. 189–199. Springer, Heidelberg (2007). https://doi.org/10.1007/978-3-540-76386-4_17
Wang, T., Zhu, J.Y., Torralba, A., Efros, A.A.: Dataset distillation. CoRR, abs/1811.10959 (2018)
Wolf, G.W.: Facility location: concepts, models, algorithms and case studies. series: Contributions to management science. Int. J. Geogr. Inf. Sci. 25(2), 331–333 (2011)
Xie, H.D., et al.: Reorthonormalization of chebyshev matrix product states for dynamical correlation functions. Phys. Rev. B 97(7), 075111 (2018)
Zhao, B., Mopuri, K.R., Bilen, H.: Dataset condensation with gradient matching. In: 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3-7 May 2021. OpenReview.net (2021)
Acknowledgments
This work was partially supported by National Natural Science Foundation of China under Grants No. 62206299 and 62222215, Beijing Outstanding Young Scientist Program under Grant No. BJJWZYJH012019100020098 and CCF-Zhipu AI Large Model Fund.
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Gao, ZF., Liu, P., Zhao, W.X., Xie, ZY., Wen, JR., Lu, ZY. (2024). Compression Image Dataset Based on Multiple Matrix Product States. In: Arai, K. (eds) Advances in Information and Communication. FICC 2024. Lecture Notes in Networks and Systems, vol 920. Springer, Cham. https://doi.org/10.1007/978-3-031-53963-3_43
Download citation
DOI: https://doi.org/10.1007/978-3-031-53963-3_43
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-53962-6
Online ISBN: 978-3-031-53963-3
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)