
Abstract
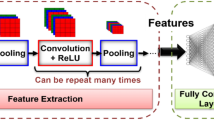
Deep learning Convolutional Neural Network (CNN) is a powerful tool for feature extraction, edge detection and image classification. However, the training system of the networks has become increasingly complex due to the continuous growth in dataset which significantly impacts the computational time and energy consumption. In domain-specific platforms, this system is bounded by another level of limitation which is the hardware resources and the I/O resources. Using Gabor filter as a preprocessing layer can eliminate the redundant features and unnecessary information which results in much fewer memory used and less computation involved. In this paper, we propose a preprocessing layer which consists of Gabor kernel that serves as a weight kernel for CNNs and convolutional kernel that produces the features. We implemented the two kernels using the hardware description language Verilog that targets Xilinx FPGA devices. We designed a novel Gabor kernel based on the reconfigurability of FPGA by utilizing the BlockRAM (BRAMs) to store Gabor parameters, SRAM-based memory to store the input image and Digital Signal Processing (DSPs) for convolutional computation. We evaluated the design on Virtex 5 FPGA device using a 64 × 64 image, and we measured the performance of the Gabor kernel and convolutional kernel individually and found that Gabor kernel spend ~0.1 µs to produce the weight kernel and convolutional unit spends ~0.8 µs to find features.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Chai, J., Zeng, H., Li, A., Ngain, E.W.: Deep learning in computer vision: a critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 6, 100134 (2021)
Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings (2010)
Basalama, S., Sohrabizadeh, A., Wang, J., Guo, L., Cong, J.: FlexCNN: an end-to-end framework for composing CNN accelerators on FPGA. ACM Trans. Reconfigurable Technol. Syst. 16(2), 1–32 (2023)
Kim, H., Choi, K.K.: A reconfigurable CNN-based accelerator design for fast and energy-efficient object detection system on mobile FPGA. IEEE Access 11, 59438–59445 (2023)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Karakchi, R., Robertson, N. (2024). An Approach to Mitigate CNN Complexity on Domain-Specific Architectures. In: Daimi, K., Al Sadoon, A. (eds) Proceedings of the Second International Conference on Advances in Computing Research (ACR’24). ACR 2024. Lecture Notes in Networks and Systems, vol 956. Springer, Cham. https://doi.org/10.1007/978-3-031-56950-0_46
Download citation
DOI: https://doi.org/10.1007/978-3-031-56950-0_46
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-56949-4
Online ISBN: 978-3-031-56950-0
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)