
Abstract
We prove that two variants of the Fujisaki-Okamoto transformations are selective opening (SO) secure against chosen-ciphertext attacks in the quantum random oracle model (QROM), assuming that the underlying public-key encryption scheme is one-wayness against chosen-plaintext attacks (OW-CPA). The two variants we consider are  (Hofheinz, Hövelmanns, and Kiltz, TCC 2017) and
(Hofheinz, Hövelmanns, and Kiltz, TCC 2017) and  (Jiang et al., CRYPTO 2018). This is the first correct proof in the QROM.
(Jiang et al., CRYPTO 2018). This is the first correct proof in the QROM.
The previous work of Sato and Shikata (IMACC 2019) showed the SO security of  in the QROM. However, we identify a subtle gap in their work. To close this gap, we propose a new framework that allows us to adaptively reprogram a QRO with respect to multiple queries that are computationally hard to predict. This is a property that can be easily achieved by the classical ROM, but is very hard to achieve in the QROM. Hence, our framework brings the QROM closer to the classical ROM.
in the QROM. However, we identify a subtle gap in their work. To close this gap, we propose a new framework that allows us to adaptively reprogram a QRO with respect to multiple queries that are computationally hard to predict. This is a property that can be easily achieved by the classical ROM, but is very hard to achieve in the QROM. Hence, our framework brings the QROM closer to the classical ROM.
Under our new framework, we construct the first tightly SO secure PKE in the QROM using lossy encryption. Our final application is proving  and
and  are bi-selective opening (Bi-SO) secure in the QROM. This is a stronger SO security notion, where an adversary can additionally corrupt some users’ secret keys.
are bi-selective opening (Bi-SO) secure in the QROM. This is a stronger SO security notion, where an adversary can additionally corrupt some users’ secret keys.
Partially supported by the Research Council of Norway under Project No. 324235.
You have full access to this open access chapter, Download conference paper PDF
Keywords
1 Introduction
Public-key encryption (PKE) schemes are a central topic in cryptography. Their widely accepted security notion is indstinguishability against chosen-ciphertext attacks (\(\text {IND}\hbox {-}\text {CCA}\)), which states that confidentiality holds even if an adversary \(\mathcal {A}\) can adaptively decrypt ciphertexts of its choice, except the challenge ciphertext. This is a security notion in the single-user, single-challenge setting, namely, only one user’s public key and one challenge ciphertext are exposed to an adversary.
Its multi-user, multi-challenge counterpart is an arguably more realistic setting. Selective opening (\(\text {SO}\)) security [3, 6] is a notion in a multi-challenge setting, where an adversary is given multiple challenge ciphertexts under a single public key and aims at learning some information about the encrypted messages. On top of that, the adversary can open a subset of the challenge ciphertexts and reveal the corresponding messages and randomness used to generate those ciphertexts. \(\text {SO}\) security guarantees the confidentiality of the remaining unopened challenge ciphertexts. The recent notion, \(\text {Bi}\hbox {-}\text {SO}\) security [28], can be viewed as a stronger variant of the \(\text {SO}\) security in a multi-user setting, where the adversary is additionally given multiple users’ public keys and it can corrupt some of their secret keys.
The aforementioned opening capability is motivated by the fact that cryptographic information is technically hard and expensive to erase in practice and an adversary may break into an encrypter’s computer and learn the used randomness. In some applications, such as secure multi-party computation, it is even required to reveal the messages and randomness to make a user’s computation publicly verifiable.
Technically speaking, it is challenging to construct a SO secure PKE. At a first glance, one may think that IND-CCA security implies SO security, since each ciphertext is generated using independent randomness. However, this is not true in general. We refer [23] for an overview and useful further reading. We highlight that, from a provable-security point of view, to answer an opening query, a security reduction should be able to ‘explain’ how it generates a challenge ciphertext by returning the randomness, but in many cases the reduction does not even know the randomness itself. Hybrid arguments are one of the examples, namely, the reduction cannot explain a ciphertext where a challenge is embedded. This is also the inherent reason why the recent updated proof of Sato and Shikata [36] is incorrect. In the recent years, a great amount of effort has been put into defining the right notion of SO security [3, 6, 23] and construct efficient SO-secure public-key encryption schemes [11, 17,18,19,20, 28].
 Currently, there are two types of notions have been studied in the literature, the indistinguishability-based (IND-based) ones (weak-IND-SO and full-IND-SO) [3, 6] and the simulation-based (SIM-based) one (SIM-SO) [3]. They are not polynomial-time equivalent to each other. In this paper we only consider the SIM-based one. Informally, SIM-SO security states that for every \(\text {SO}\) adversary its output can be efficiently simulated by a simulator that sees only the opened messages. Unlike its IND-based counterpart, SIM-SO does not require the message distribution chosen by the adversary to be efficiently resamplable, conditioned on the opened messages (cf. [3]). Previous work showed that SIM-SO-CCA and full-IND-SO-CCA notions are the strongest SO security [2, 6, 23]. However, only SIM-SO-CCA has been realized so far [11, 17,18,19,20]. It is similar for \(\text {Bi}\hbox {-}\text {SO}\) security, and only SIM-based notion is considered so far [28]. For simplicity, we will not write ‘SIM’ in the following.
Currently, there are two types of notions have been studied in the literature, the indistinguishability-based (IND-based) ones (weak-IND-SO and full-IND-SO) [3, 6] and the simulation-based (SIM-based) one (SIM-SO) [3]. They are not polynomial-time equivalent to each other. In this paper we only consider the SIM-based one. Informally, SIM-SO security states that for every \(\text {SO}\) adversary its output can be efficiently simulated by a simulator that sees only the opened messages. Unlike its IND-based counterpart, SIM-SO does not require the message distribution chosen by the adversary to be efficiently resamplable, conditioned on the opened messages (cf. [3]). Previous work showed that SIM-SO-CCA and full-IND-SO-CCA notions are the strongest SO security [2, 6, 23]. However, only SIM-SO-CCA has been realized so far [11, 17,18,19,20]. It is similar for \(\text {Bi}\hbox {-}\text {SO}\) security, and only SIM-based notion is considered so far [28]. For simplicity, we will not write ‘SIM’ in the following.
 SO secure PKE schemes are constructed in idealized models [18, 19] and in the standard model [3, 11, 17, 20]. Constructions in idealized models are more efficient and hence more relevant to practice. In particular, this paper considers schemes in the random oracle model (ROM).
SO secure PKE schemes are constructed in idealized models [18, 19] and in the standard model [3, 11, 17, 20]. Constructions in idealized models are more efficient and hence more relevant to practice. In particular, this paper considers schemes in the random oracle model (ROM).
The increasing threat that quantum computers can break most widely deployed public-key cryptosystems has driven research in the direction of building post-quantum secure public-key primitives, including PKE schemes and key encapsulation mechanisms (KEMs). Currently, the National Institute of Standards and Technology (NIST) in the US has come to a conclusion for the post-quantum standards. Kyber [37], NTRU [8], and Saber [9] were three finalists in the last round for the KEM/PKE category. They all use variants of the Fujisaki-Okamoto (FO) transformation [12,13,14, 21]. It is interesting to consider whether these FO transformations are secure in the SO setting.
The FO transformation turns a relatively weak PKE (e.g. a One-Way CPA secure one) into an \(\text {IND}\hbox {-}\text {CCA}\) secure one. Recently, the FO transformation and its variants have been widely analyzed in both the classical ROM and the quantum (accessible) ROM (QROM) [21, 24, 27, 34, 38], but mostly with a focus on establishing \(\text {IND}\hbox {-}\text {CCA}\) security. An exception is the work of Heuer et al. [18] which studied the SO security of the FO transformation in the ROM.
For post-quantum security, proofs in the QROM are more desirable than those in the (classical) ROM, since it models quantum adversaries in a more realistic manner. In this setting, a quantum adversary interacts with a classical network, where “online” primitives (such as encryption) are classical, and computes “offline” primitives (such as hashing) on its own in superposition.
The work of Sato and Shikata [35] proved the SO security of the FO transformation in the QROM. To the best of our knowledge, this is the only work considers SO security in the QROM. However, we identified a subtle gap in their security proofFootnote 1. Even worse, this gap cannot be closed, even if we relax the notion to the weaker, non-adaptive SO security as in [29], where an adversary is not allowed to adaptively open a challenge ciphertext, but commits all its opening indices after seeing the challenge ciphertexts. From a technical point of view, closing the gap in [35] requires new proof techniques in the QROM that allow a security reduction to adaptively reprogram multiple RO-queries in one security game without changing the view of an adversary, where the reprogrammed points are computationally hidden. This is a property not achievable by existing well-known techniques, such as [16, 27, 39, 40]. We provide more discussion about it in Sect. 1.2.
1.1 Our Contributions
We revise the selective opening security in the QROM and prove that two “implicit rejection” variants of the FO transformation (namely,  [24] and
[24] and  [21]) are \(\text {SO}\hbox {-}\text {CCA}\) secure if the underlying PKE is one-way CPA (\(\text {OW}\hbox {-}\text {CPA}\)) secure in the QROM. Here we consider PKE schemes, namely, combining KEM
[21]) are \(\text {SO}\hbox {-}\text {CCA}\) secure if the underlying PKE is one-way CPA (\(\text {OW}\hbox {-}\text {CPA}\)) secure in the QROM. Here we consider PKE schemes, namely, combining KEM  (or
(or  ) with one-time pad and a message authentication code (MAC). The one with
) with one-time pad and a message authentication code (MAC). The one with  is the same scheme considered in [35], but ours is the first correct proof in the QROM. Since the proofs for
is the same scheme considered in [35], but ours is the first correct proof in the QROM. Since the proofs for  and
and  are similar, we leave the one for
are similar, we leave the one for  in our full version [33], and there we only prove the \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) for
in our full version [33], and there we only prove the \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) for  , since it implies \(\text {SO}\hbox {-}\text {CCA}\) security.
, since it implies \(\text {SO}\hbox {-}\text {CCA}\) security.
Our core technical contribution is a computational adaptive reprogramming framework in the QROM that enables a security reduction to adaptively and simultaneously reprogram polynomially many RO-queries which are computationally hidden from a quantum adversary. This is a property that cannot be provided by previous techniques in the QROM, such as the (adaptive) one-way to hiding (O2H) lemma [39, 40], the semi-classical O2H lemma [1], and the measure-rewind-measure O2H lemma [27]. Our framework brings the QROM closer to the classical ROM, and it generalizes and improves the adaptive reprogramming framework by Grilo et al. [16].
 Our second contribution is a tightly \(\text {SO}\hbox {-}\text {CCA}\) secure PKE from lossy encryption [3, 22]. This is the first tight scheme in the QROM. A recent work of Pan, Wagner, and Zeng has constructed the first tightly multi-user (without corruptions), multi-challenge IND-CCA in the QROM [31], but it did not get extended to the (stronger) SO setting. Another related work is also due to Pan and Zeng [32], where a compact and tightly SO-CCA secure PKE is proposed in the classical random oracle model. However, it is unclear if it can be transformed to the QROM. Our result on tight SO security is established in the QROM, and it improves both aforementioned work.
Our second contribution is a tightly \(\text {SO}\hbox {-}\text {CCA}\) secure PKE from lossy encryption [3, 22]. This is the first tight scheme in the QROM. A recent work of Pan, Wagner, and Zeng has constructed the first tightly multi-user (without corruptions), multi-challenge IND-CCA in the QROM [31], but it did not get extended to the (stronger) SO setting. Another related work is also due to Pan and Zeng [32], where a compact and tightly SO-CCA secure PKE is proposed in the classical random oracle model. However, it is unclear if it can be transformed to the QROM. Our result on tight SO security is established in the QROM, and it improves both aforementioned work.
 As another application of our framework, we prove that the aforementioned variants of FO transformation, namely,
As another application of our framework, we prove that the aforementioned variants of FO transformation, namely,  and
and  , are furthermore \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) secure [28] in the QROM, assuming \(\text {OW}\hbox {-}\text {CPA}\) security of the underlying PKE scheme. This notion is stronger than the \(\text {SO}\hbox {-}\text {CCA}\) security, since it additionally allows secret key corruption for the adversaries. The only known \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) secure construction is in the classical ROM. Our work is the first one in the QROM.
, are furthermore \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) secure [28] in the QROM, assuming \(\text {OW}\hbox {-}\text {CPA}\) security of the underlying PKE scheme. This notion is stronger than the \(\text {SO}\hbox {-}\text {CCA}\) security, since it additionally allows secret key corruption for the adversaries. The only known \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) secure construction is in the classical ROM. Our work is the first one in the QROM.
 The NIST finalists Kyber and Saber use tweaked verions of transformation
The NIST finalists Kyber and Saber use tweaked verions of transformation  , and NTRU uses
, and NTRU uses  . Hence, analysis of these FO transformations is more fundamental than directly analyzing these concrete schemes. Although our results strongly indicate that the NIST finalists are \(\text {SO}\hbox {-}\text {CCA}\) secure and \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) in the QROM, we leave the formal proof of it as a future direction, and we are optimistic that our approaches can be extended naturally in achieving it.
. Hence, analysis of these FO transformations is more fundamental than directly analyzing these concrete schemes. Although our results strongly indicate that the NIST finalists are \(\text {SO}\hbox {-}\text {CCA}\) secure and \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) in the QROM, we leave the formal proof of it as a future direction, and we are optimistic that our approaches can be extended naturally in achieving it.
1.2 Technical Details
We provide some details about our technical contribution, computational adaptive reprogramming framework.
 The work of Heuer et al. [18] is the first one proving that practical PKEs via the OAEP and FO transformation are \(\text {SO}\hbox {-}\text {CCA}\) secure in the (classical) ROM. Their work considered the original FO transformation [14]. Motivated by Heuer et al. ’s work, we can show that the combination of
The work of Heuer et al. [18] is the first one proving that practical PKEs via the OAEP and FO transformation are \(\text {SO}\hbox {-}\text {CCA}\) secure in the (classical) ROM. Their work considered the original FO transformation [14]. Motivated by Heuer et al. ’s work, we can show that the combination of  and one-time pad is \(\text {SO}\hbox {-}\text {CPA}\) secure in the classical ROM by adaptively reprogramming the ROs. Here we describe some key idea. Note that our final goal is \(\text {SO}\hbox {-}\text {CCA}\), but for the simplicity of our discussion here, we only consider \(\text {SO}\hbox {-}\text {CPA}\).
and one-time pad is \(\text {SO}\hbox {-}\text {CPA}\) secure in the classical ROM by adaptively reprogramming the ROs. Here we describe some key idea. Note that our final goal is \(\text {SO}\hbox {-}\text {CCA}\), but for the simplicity of our discussion here, we only consider \(\text {SO}\hbox {-}\text {CPA}\).
A ciphertext of message m in the  transformation, (e, d), is defined as follow:
transformation, (e, d), is defined as follow:

where \(\textsf{Enc}_0\) is the randomized encryption algorithm of a \(\text {OW}\hbox {-}\text {CPA}\) secure PKE with message space \(\mathcal {M}'\), G(r) is the explicit randomness used in \(\textsf{Enc}_0\), and G, H are two hash functions with suitable domains and ranges. Public and secret keys of  is the same as those of the \(\text {OW}\hbox {-}\text {CPA}\) secure PKE, and the decryption is defined in the straightforward way. We refer Fig. 6 for the full description.
is the same as those of the \(\text {OW}\hbox {-}\text {CPA}\) secure PKE, and the decryption is defined in the straightforward way. We refer Fig. 6 for the full description.
 To show the \(\text {SO}\hbox {-}\text {CPA}\) security, we require “efficient openability” of ciphertexts [3, 11]. This property states that one can generate some ciphertexts and later they can be efficiently opened to arbitrary messages by using some trapdoor (in the standard model) or reprogramming ROs (in the ROM) in a suitable way. In the classical ROM, our ciphertexts (defined by Eq. (1)) have efficient openability. More precisely, a security reduction \(\mathcal {R}\) can choose random \(r^*_i\), \(R^*_i\), and \(d^*_i\) and return the challenge ciphertexts \((\textsf{Enc}_0(\textsf{pk},r^*_i;R^*_i), d^*_i)_{1\le i \le \mu }\) to the \(\text {SO}\hbox {-}\text {CPA}\) adversary \(\mathcal {A}\). For these challenge ciphertexts, the reduction \(\mathcal {R}\) can open a ciphertext \((\textsf{Enc}_0(\textsf{pk},r^*_i;R^*_i), d^*_i)\) to arbitrary message \(m_i\) by reprogramming \(G(r^*_i):=R^*_i\) and \(H(r_i^*,e^*_i):=d^*_i \oplus m_i \). Moreover, \(\mathcal {R}\) will embed the \(\text {OW}\hbox {-}\text {CPA}\) challenge to one of the unopened ciphertexts. Here, \(r^*_i\) are only computationally hidden from the adversary.
To show the \(\text {SO}\hbox {-}\text {CPA}\) security, we require “efficient openability” of ciphertexts [3, 11]. This property states that one can generate some ciphertexts and later they can be efficiently opened to arbitrary messages by using some trapdoor (in the standard model) or reprogramming ROs (in the ROM) in a suitable way. In the classical ROM, our ciphertexts (defined by Eq. (1)) have efficient openability. More precisely, a security reduction \(\mathcal {R}\) can choose random \(r^*_i\), \(R^*_i\), and \(d^*_i\) and return the challenge ciphertexts \((\textsf{Enc}_0(\textsf{pk},r^*_i;R^*_i), d^*_i)_{1\le i \le \mu }\) to the \(\text {SO}\hbox {-}\text {CPA}\) adversary \(\mathcal {A}\). For these challenge ciphertexts, the reduction \(\mathcal {R}\) can open a ciphertext \((\textsf{Enc}_0(\textsf{pk},r^*_i;R^*_i), d^*_i)\) to arbitrary message \(m_i\) by reprogramming \(G(r^*_i):=R^*_i\) and \(H(r_i^*,e^*_i):=d^*_i \oplus m_i \). Moreover, \(\mathcal {R}\) will embed the \(\text {OW}\hbox {-}\text {CPA}\) challenge to one of the unopened ciphertexts. Here, \(r^*_i\) are only computationally hidden from the adversary.
For the \(\text {SO}\hbox {-}\text {CPA}\) security, the aforementioned reprogramming is required to be adaptive, since an adversary can submit an opening query adaptively. Moreover, a \(\text {SO}\hbox {-}\text {CPA}\) adversary can submit multiple opening queries in one security game or hybrid. Therefore, our reprogramming strategy should be able to reprogram multiple RO-queries in one security game. We call this last requirement as multi-point reprogramming. We stress that hybrid arguments are already not useful for \(\text {SO}\) security. This is because a standard hybrid argument will embed a \(\text {OW}\hbox {-}\text {CPA}\) challenge into the \(\text {SO}\hbox {-}\text {CPA}\) ciphertexts one-by-one. After it is embedded to the i-th ciphertext, \(G(r^*_i)\) cannot be reprogrammed to \(R^*_i\), since \(R^*_i\) is unknown to the reduction \(\mathcal {R}\). Thus, the opening query cannot be correctly answered.
 Reprogramming a quantum (accessible) RO is highly non-trivial, since a query in superposition can be viewed as a query that might contain all possible input values at once. To correctly reprogram a value to a particular QRO query, it needs to measure and extract classical preimages of a quantum query, which will cause a change in the adversary’s view. Although many works have been done to provide reprogrammability in the QROM [1, 16, 27, 39, 40], reprogramming in the QROM is still much more challenging than in the ROM.
Reprogramming a quantum (accessible) RO is highly non-trivial, since a query in superposition can be viewed as a query that might contain all possible input values at once. To correctly reprogram a value to a particular QRO query, it needs to measure and extract classical preimages of a quantum query, which will cause a change in the adversary’s view. Although many works have been done to provide reprogrammability in the QROM [1, 16, 27, 39, 40], reprogramming in the QROM is still much more challenging than in the ROM.
For the SO security, the situation is more complicated. Essentially, existing approaches (such as [1, 16, 27, 39, 40]) cannot easily achieve the requirements for SO security in the QROM. We use the semi-classical O2H lemma [1] as an example to elaborate on this. Fix a random set \(S \subseteq \mathcal {X}\). Let \(H,H' : \mathcal {X}\rightarrow \mathcal {Y}\) be two different ROs such that, for all \(x\in \mathcal {X}\setminus S\), \(H(x)=H'(x)\) (denoted by \(H\setminus S = H' \setminus S\)). The semi-classical O2H lemma states that a quantum adversary \(\mathcal {A}\) cannot tell the difference between H and \(H'\) by giving only quantum access to them, unless \(\mathcal {A}\) finds an element from S. Here set S needs to be defined before defining H and \(H'\).
In the work of Sato and Shikata [35], their security proofs viewed S as the set containing all the randomness used in the opened ciphertexts (cf. the step between Game\(_1\) and Game\(_2\) in [35, Section 3.1] and the one between Game\(_5\) and Game\(_6\) in [35, Section 3.2]). Essentially, S is equivalent to the set of opening indices which are adaptively decided by the adversary \(\mathcal {A}\). However, to use the semi-classical O2H lemma, S must be fixed at the beginning of the security game, even before generating the public key. Therefore, this technical gap in their proofs cannot be closed, and it will be the case, even if we consider the weaker, non-adaptive variant of SO security as in [29], namely, an adversary cannot adaptively open challenge ciphertexts, but commits to opening indices after receiving the challenge ciphertexts.
The recent measure-rewind-measure O2H lemma [27] has a similar flavor as the semi-classical O2H lemma, and it does not allow to define S adaptively. The adaptive O2H lemma [39] allow us to reprogram a single query adaptively. However, we require adaptive reprogramming multiple queries for SO security, since if we only reprogram wrt one opening query, an adversary can distinguish the simulation by opening multiple ciphertexts.
 To solve the technical difficulties, we propose the computational adaptive reprogramming framework. It is more general than the algorithmic O2H lemma [39] and the adaptive reprogramming framework [16] in the sense that our framework allows a reduction to reprogram polynomial many RO queries in the QROM. Different to the work of Grilo et al., our reprogrammed points can be only computationally hidden from the adversary.
To solve the technical difficulties, we propose the computational adaptive reprogramming framework. It is more general than the algorithmic O2H lemma [39] and the adaptive reprogramming framework [16] in the sense that our framework allows a reduction to reprogram polynomial many RO queries in the QROM. Different to the work of Grilo et al., our reprogrammed points can be only computationally hidden from the adversary.
In a nutshell, our framework considers two security games, \(\textsc {NonAda}\) and \(\textsc {Ada}\). The RO \(H'\) in \(\textsc {NonAda}\) will never be reprogrammed, but the RO H in \(\textsc {Ada}\) will be adaptively reprogrammed for multiple times according to the adversary’s behavior. We require \(H'\setminus S = H \setminus S\), but S can be modified adaptively by a security reduction. Intuitively, an adversary \(\mathcal {A}\) can distinguish \(\textsc {NonAda}\) and \(\textsc {Ada}\) if it queries \(x \in S\). This event can be detected easily in the classical setting, but is problematic in the quantum setting. Our high-level approach is to bound the probability of this event by randomly measuring \(\mathcal {A}\). Details are given in Sect. 3. We stress that our approach is not a “hybrid argument” extension of the existing techniques. In fact, as pointed out by Bellare, Hofheinz, and Yilek [3], it is unknown if a simple hybrid argument is useful in proving SO security. Very unfortunately, the latest revisionFootnote 2 of [35] is a concrete example for why it does not work. The proof of their Lemma 1 is essentially a hybrid argument. A counterexample is simply: Imagine an adversary that always opens the first ciphertext, then their first hybrid always fails since the OPEN oracle will abort when the adversary opens the first ciphertext, and thus their hybrid argument cannot prove the SO security.
 Recently, Grilo et al. proposed the adaptive reprogramming framework [16] and used it to give a QROM proof for Fiat-Shamir’s signatures. The main difference between our work and Grilo et al. ’s work is that their framework requires the reprogramming points to have high statistical entropy, while our framework requires the reprogramming points are computationally hard to find (which cover the case of statistical entropy). When proving the SO security of the FO transformation, their framework cannot be used since the reprogramming points are computationally hidden by OW-CPA security of some underlying PKEs.
Recently, Grilo et al. proposed the adaptive reprogramming framework [16] and used it to give a QROM proof for Fiat-Shamir’s signatures. The main difference between our work and Grilo et al. ’s work is that their framework requires the reprogramming points to have high statistical entropy, while our framework requires the reprogramming points are computationally hard to find (which cover the case of statistical entropy). When proving the SO security of the FO transformation, their framework cannot be used since the reprogramming points are computationally hidden by OW-CPA security of some underlying PKEs.
We also compare our framework to the measure-and-reprogram framework of Don, Fehr, and Majenz [10] and the lifting theorem in [41] that are used to prove security of the Fiat-Shamir (FS) signature in the QROM. In a nutshell, the difference between our frameworks is similar to that between the security proofs of the FO encryption and FS signature in the classical setting. More precisely, in the proof of FO encryption, we argue that it is infeasible for an adversary to learn the reprogramming points and thus we can reprogram the random oracle without changing the adversary’s view. However, in the proof of FS signature, an adversary can learn the reprogramming points, since they are the hash values of signing messages and some (public) commitments of the \(\varSigma \) protocol. Hence, the measure-and-reprogram framework is conceptually different to us and cannot be used in proving SO or Bi-SO security in the QROM. The lifting theorem (cf. [41, Theorem 4.2]) has a similar flavor as the measure-and-reprogram framework.
 We leave exploring more applications of our computational adaptive reprogramming framework as a future direction, since reprogramming a (quantum) random oracle on multiple computationally hidden points is an interesting technique and we are optimistic that it may yield new applications. Moreover, we are optimistic that our approach can work for the simulatable DEM framework of SO secure PKEs. We leave a formal treatment of it as another future direction.
We leave exploring more applications of our computational adaptive reprogramming framework as a future direction, since reprogramming a (quantum) random oracle on multiple computationally hidden points is an interesting technique and we are optimistic that it may yield new applications. Moreover, we are optimistic that our approach can work for the simulatable DEM framework of SO secure PKEs. We leave a formal treatment of it as another future direction.
2 Preliminaries
Let n be an integer. [n] denotes the set \(\{1,...,n\}\). Let \({\mathcal {X}}\) and \({\mathcal {Y}}\) be two finite sets and \(f: {\mathcal {X}}\rightarrow {\mathcal {Y}}\) be a function. \(f({\mathcal {X}}) := \{f(x) | x \in {\mathcal {X}}\}\).  denotes sampling a uniform element x from \({\mathcal {X}}\) at random. If S is a subset of \({\mathcal {X}}\), then \({\mathcal {X}}\backslash S\) denotes the set \(\{ x \in {\mathcal {X}}| x \notin S \}\). Let \(\mathcal {A}\) be an algorithm. If \(\mathcal {A}\) is probabilistic, then \(y \leftarrow \mathcal {A}(x)\) means that the variable y is assigned to the output of \(\mathcal {A}\) on input x. If \(\mathcal {A}\) is deterministic, then we write \(y := \mathcal {A}(x)\). We write \(\mathcal {A}^{\mathcal {O}}\) to indicate that \(\mathcal {A}\) has classical access to oracle \(\mathcal {O}\). We write \(\textbf{T}(\mathcal {A}_0) \approx \textbf{T}(\mathcal {A}_1)\) if the running times of \(\mathcal {A}_0\) and \(\mathcal {A}_1\) are polynomially close to each other. All (quantum) algorithms are (quantum) probabilistic polynomial time, unless we state it.
denotes sampling a uniform element x from \({\mathcal {X}}\) at random. If S is a subset of \({\mathcal {X}}\), then \({\mathcal {X}}\backslash S\) denotes the set \(\{ x \in {\mathcal {X}}| x \notin S \}\). Let \(\mathcal {A}\) be an algorithm. If \(\mathcal {A}\) is probabilistic, then \(y \leftarrow \mathcal {A}(x)\) means that the variable y is assigned to the output of \(\mathcal {A}\) on input x. If \(\mathcal {A}\) is deterministic, then we write \(y := \mathcal {A}(x)\). We write \(\mathcal {A}^{\mathcal {O}}\) to indicate that \(\mathcal {A}\) has classical access to oracle \(\mathcal {O}\). We write \(\textbf{T}(\mathcal {A}_0) \approx \textbf{T}(\mathcal {A}_1)\) if the running times of \(\mathcal {A}_0\) and \(\mathcal {A}_1\) are polynomially close to each other. All (quantum) algorithms are (quantum) probabilistic polynomial time, unless we state it.
 We use code-based games [4] to define and prove security. We implicitly assume that Boolean flags are initialized to false, numerical types are initialized to 0, sets are initialized to \(\emptyset \), while strings are initialized to the empty string \(\epsilon \). \(\Pr [\textbf{G}^\mathcal {A}\Rightarrow 1]\) denotes the probability that the final output \(\textbf{G}^{\mathcal {A}}\) of game \(\textbf{G}\) running an adversary \(\mathcal {A}\) is 1. Let Ev be an (classical and well-defined) event. We write \(\Pr [\texttt {Ev} : \textsf {G}]\) to denote the probability that Ev occurs during the game \(\textbf{G}\).
We use code-based games [4] to define and prove security. We implicitly assume that Boolean flags are initialized to false, numerical types are initialized to 0, sets are initialized to \(\emptyset \), while strings are initialized to the empty string \(\epsilon \). \(\Pr [\textbf{G}^\mathcal {A}\Rightarrow 1]\) denotes the probability that the final output \(\textbf{G}^{\mathcal {A}}\) of game \(\textbf{G}\) running an adversary \(\mathcal {A}\) is 1. Let Ev be an (classical and well-defined) event. We write \(\Pr [\texttt {Ev} : \textsf {G}]\) to denote the probability that Ev occurs during the game \(\textbf{G}\).
 We use MAC schemes that have one-time strong existential unforgeability under chosen message attack (\(\text {otSUF}\hbox {-}{\text {CMA}}\)) as building block. Let \(\textsf{MAC}: = (\textsf{Tag}, \textsf{Vrfy})\) be an one-time MAC scheme with key space \(\mathcal {K}^\texttt{mac}\). The \(\text {otSUF}\hbox {-}{\text {CMA}}\) security game is given in Fig. 1.
We use MAC schemes that have one-time strong existential unforgeability under chosen message attack (\(\text {otSUF}\hbox {-}{\text {CMA}}\)) as building block. Let \(\textsf{MAC}: = (\textsf{Tag}, \textsf{Vrfy})\) be an one-time MAC scheme with key space \(\mathcal {K}^\texttt{mac}\). The \(\text {otSUF}\hbox {-}{\text {CMA}}\) security game is given in Fig. 1.
Definition 1
(otSUF-CMA). For a forger \(\mathcal {F}\), its advantage against \(\text {otSUF}\hbox {-}{\text {CMA}}\) security of \(\textsf{MAC}\) is defined as
\(\textsf{MAC}\) is \(\text {otSUF}\hbox {-}{\text {CMA}}\) secure if for all \(\mathcal {F}\), \({\textsf{Adv}}^{\textsf{otSUF}\text{- }\textsf{CMA}}_{\textsf{PKE}}(\mathcal {F}) = \textsf{negl}(\lambda )\).
One-time MAC schemes can be constructed by using pair-wise independent hash function family, and they are \(\text {otSUF}\hbox {-}{\text {CMA}}\) secure against unbounded adversaries. Here \(\textsc {Tag}\) cannot be queried with quantum superposition.

Security games one-time MAC schemes
2.1 Public-Key Encryption
A Public Key Encryption (PKE) scheme \(\textsf{PKE}\) consists of three algorithms \(({\textsf{KG}}, \textsf{Enc}, \textsf{Dec})\) and a message space \(\mathcal {M}\) that is assumed to be efficiently recognizable. The three algorithms work as follows:
-
The key generation algorithm \({\textsf{KG}}\), on input the security parameter \(\lambda \), outputs a public and secret key pair \((\textsf{pk},\textsf{sk})\). \(\textsf{pk}\) also defines a finite randomness space \(\mathcal {R}:= \mathcal {R}(\textsf{pk})\) and a ciphertext space \(\mathcal {C}:= \mathcal {C}(\textsf{pk})\). For sake of simplicity, in this paper, we ignore the input \(\lambda \) and simply write the process as \((\textsf{pk},\textsf{sk}) \leftarrow {\textsf{KG}}\).
-
The encryption algorithm \(\textsf{Enc}\), on input \(\textsf{pk}\) and a message \(m\in \mathcal {M}\), outputs a ciphertext \(c \in \mathcal {C}\). We also write \(c := \textsf{Enc}(\textsf{pk},m; r)\) to indicate the randomness \(r \in \mathcal {R}\) explicitly.
-
The (deterministic) decryption algorithm \(\textsf{Dec}\), on input \(\textsf{sk}\) and a ciphertext c, outputs a message \(m' \in \mathcal {M}\) or a rejection symbol \(\bot \notin \mathcal {M}\).
Definition 2
(PKE Correctness). A PKE scheme \(\textsf{PKE}:= ({\textsf{KG}}, \textsf{Enc}, \textsf{Dec})\) with message space \(\mathcal {M}\) is \((1 - \delta )\)-correct if
where the expectation is taken over \((\textsf{pk},\textsf{sk}) \leftarrow {\textsf{KG}}\) and randomness of \(\textsf{Enc}\). \(\textsf{PKE}\) has perfect correctness if \(\delta = 0\).
Definition 3
(Collision Probability of Key Generation). Let
be the collision probability of \({\textsf{KG}}\) of \(\textsf{PKE}\). The maximum is taken over all \(\textsf{pk}_0,\textsf{pk}_1\). In this paper, we assume that for any \(\text {OW}\hbox {-}\text {CPA}\)-secure \(\textsf{PKE}\), \(\eta _{\textsf{PKE}} = \textsf{negl}(\lambda )\)
Let \(\textsf{PKE}:= ({\textsf{KG}}, \textsf{Enc}, \textsf{Dec})\) be a PKE scheme with message space \(\mathcal {M}\) and ciphertext space \(\mathcal {C}\). We focus on two security notions for PKE: onewayness under chosen-plaintext attacks (\(\text {OW}\hbox {-}\text {CPA}\)) and selective-opening security under chosen-ciphertext-attacks (\(\text {SO}\hbox {-}\text {CCA}\)).
Definition 4
(OW-CPA). For an adversary \(\mathcal {A}\), its advantage against \(\textsf{OW}\text{- }\textsf{CPA}\) security of \(\textsf{PKE}\) is defined as

\(\textsf{PKE}\) is \(\textsf{OW}\text{- }\textsf{CPA}\) secure if for all PPT adversaries \(\mathcal {A}\), \({\textsf{Adv}}^{\textsf{OW}\text{- }\textsf{CPA}}_{\textsf{PKE}}(\mathcal {A}) = \textsf{negl}(\lambda )\).
 Selective Opening (SO) security preserves confidentiality even if an adversary opens the randomnesses of some ciphertexts. We use simulation-based approach to define SO security as in [18]. We consider the SO security against Chosen-Plaintext Attacks (\(\text {SO}\hbox {-}\text {CPA}\)) and Chosen-Ciphertext Attacks (\(\text {SO}\hbox {-}\text {CCA}\)), respectively.
Selective Opening (SO) security preserves confidentiality even if an adversary opens the randomnesses of some ciphertexts. We use simulation-based approach to define SO security as in [18]. We consider the SO security against Chosen-Plaintext Attacks (\(\text {SO}\hbox {-}\text {CPA}\)) and Chosen-Ciphertext Attacks (\(\text {SO}\hbox {-}\text {CCA}\)), respectively.
We note that a non-adaptive variant of SO security has been used in [29], where an adversary must declare the opening index set \(I\) after receiving the challenge ciphertexts, while our SO security is adaptive in the sense that \(\textsc {Open}\) can be asked adaptively. Intuitively, our adaptive security is harder to achieve, since an adversary can change its opening queries after seeing the answers of previous ones.

The SO security games for PKE schemes.
Definition 5
(SO security). Let \(\textsf{PKE}\) be a PKE scheme with message space \(\mathcal {M}\) and randomness space \(\mathcal {R}\) and \(\mathcal {A}\) be an adversary against \(\textsf{PKE}\). For security parameter \(\lambda \), \(\mu :=\mu (\lambda )>0\) is a polynomially bounded function. Let \({\textsf{Rel}}\) be a relation. We consider two games defined in Fig. 2, where \(\mathcal {A}\) is run in \(\textsf{REAL}\hbox {-}\textsf{SO} \hbox {-}\textsf{ATK}_\textsf{PKE}\) and a SO simulator \(\mathcal {S}\) in \(\textsf{IDEAL}\hbox {-}\textsf{SO} \hbox {-}\textsf{ATK}_\textsf{PKE}\). \(\mathcal {M}_a\) is a distribution over \(\mathcal {M}\) chosen by \(\mathcal {A}\), and \(\mathcal {A}\) is not allowed to issue \(\textsc {Open}\) queries before it outputs \(\mathcal {M}_a\) and receives challenge ciphertexts \(\textbf{c}\). Messages sampled from \(\mathcal {M}_a\) may be dependent on each other. \(\textsc {Dec}\) is not available in \(\text {SO}\hbox {-}\text {CPA}\) security.
We define the \(\text {SO}\hbox {-}\text {ATK}\) (\(\text {ATK}\) = ‘CPA’ or ‘CCA’) advantage function
\(\textsf{PKE}\) is \(\text {SO}\hbox {-}\text {ATK}\) secure if, for every adversary \(\mathcal {A}\) and every PPT relation \(\textsf{Rel}\), there exists a simulator \(\mathcal {S}\) such that \({{{\textsf{Adv}}}^{{\textsf{SO}\text{- }\textsf{ATK}}}_{\textsf{PKE}}}(\mathcal {A},\mathcal {S},\mu , {\textsf{Rel}}) \le \textsf{negl}(\lambda )\).

The \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {ATK}\) security game for PKE schemes
 In this paper, we also consider a stronger SO security definition: \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {ATK}\) [28]. This security definition considers a multi-user setting and allows the adversary to corrupt some users (namely, obtains their secret keys) adaptively. The \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {ATK}\) definition in [28] is non-adaptive, that is, the SO adversary is required to tell the game simulator which users it wants to corrupted and which challenge ciphertexts it wants to open at once. In this paper, we enhance the security definition to be adaptive. The adversary can adaptively issues \(\textsc {Open}\) queries and \(\textsc {Corrupt}\) queries in any order. The enhanced definition is also simulation-based. If \(\mathcal {A}\) corrupts a user \(j\), then the messages of challenge ciphertexts that encrypted by \(j\) are also revealed (see Items 15 and 16).
In this paper, we also consider a stronger SO security definition: \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {ATK}\) [28]. This security definition considers a multi-user setting and allows the adversary to corrupt some users (namely, obtains their secret keys) adaptively. The \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {ATK}\) definition in [28] is non-adaptive, that is, the SO adversary is required to tell the game simulator which users it wants to corrupted and which challenge ciphertexts it wants to open at once. In this paper, we enhance the security definition to be adaptive. The adversary can adaptively issues \(\textsc {Open}\) queries and \(\textsc {Corrupt}\) queries in any order. The enhanced definition is also simulation-based. If \(\mathcal {A}\) corrupts a user \(j\), then the messages of challenge ciphertexts that encrypted by \(j\) are also revealed (see Items 15 and 16).
Definition 6
(Bi-SO security). Let \(\textsf{PKE}\) be a PKE scheme and \(\mathcal {A}\) be a Bi-SO adversary against \(\textsf{PKE}\). For security parameter \(\lambda \), let \(\mu :=\mu (\lambda )\) and \(p:=p(\lambda )\) that are both polynomially bounded. Let \({\textsf{Rel}}\) be a relation. We consider two games defined in Fig. 3, where \(\mathcal {A}\) is run in \(\textsf{REAL}\hbox {-}\textsf{Bi} \hbox {-}\textsf{SO} \hbox {-}\textsf{ATK}_{\textsf{PKE}}\) and a Bi-SO simulator \(\mathcal {S}\) in \(\textsf{IDEAL}\hbox {-}\textsf{Bi} \hbox {-}\textsf{SO} \hbox {-}\textsf{ATK}_{\textsf{PKE}}\). \(\mathcal {M}_a\) is a distribution over \(\mathcal {M}\) chosen by \(\mathcal {A}\), and \(\mathcal {A}\) is not allowed to issue \(\textsc {Open}\) or \(\textsc {Corrupt}\) queries before it outputs \(\mathcal {M}_a\) and receives challenge ciphertexts \(\textbf{c}\). Messages sampled from \(\mathcal {M}_a\) may be dependent on each other. \(\textsc {Dec}\) is not available in \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CPA}\) security.
We define the \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {ATK}\) (ATK = ‘CPA’ or ‘CCA’) advantage function
\(\textsf{PKE}\) is adaptive \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {ATK}\) secure if, for any adversary \(\mathcal {A}\) and PPT relation \(\textsf{Rel}\), there exists a simulator \(\mathcal {S}\) such that \({{\textsf{Adv}}}^{{\textsf{Bi}\hbox {-}\textsf{SO} \hbox {-}\textsf{ATK}}}_{\textsf{PKE}}(\mathcal {A},\mathcal {S},p, \mu ,\lambda ) = \textsf{negl}(\lambda )\).
 The (Bi-)SO security of PKE schemes containing hash functions can be analyzed in the quantum random oracle model (cf. Sect. 2.2). If we model a hash function H as quantum random oracle, then the adversary \(\mathcal {A}\) has quantum access to H during the SO security games (e.g., Fig. 7).
The (Bi-)SO security of PKE schemes containing hash functions can be analyzed in the quantum random oracle model (cf. Sect. 2.2). If we model a hash function H as quantum random oracle, then the adversary \(\mathcal {A}\) has quantum access to H during the SO security games (e.g., Fig. 7).
2.2 Quantum Computation
We refer to [30] for detailed background about quantum mechanism. Here we only recall some necessary notations and lemmas.
Pure quantum states can be described by qubits. For a \(\lambda \)-bit-string x, \(|x \rangle \in \mathbb {C}^{2^\lambda } \) denotes the (pure) quantum state of x encoded in the standard computational basis. Quantum register is used to store multiple qubits. In this paper, we assume that any polynomially long object x can be encoded as a (unique) bit string, and if we “store” x in a quantum register X, \(|x \rangle \) is the quantum state of this register. A \(\lambda \)-qubits quantum superposition state \(|\phi \rangle \) can be written as \(\sum _{x \in \{0,1\}^\lambda } \alpha _x |x \rangle \) where \(\sum _{x \in \{0,1\}^\lambda } |\alpha _x|^2 = 1\).
By performing measurement on a quantum state, we obtain classical information about the state, and the state collapses after measurement. Let \(|x \rangle \) be an quantum state, \(x' \leftarrow \textsf{Measure}(|x \rangle )\) denote the process that \(|x \rangle \) is measured and the measurement outcome is \(x'\). We assume that all measurement are performed with respect to the standard computational basis.
Let \(\mathcal {O}: {\mathcal {X}}\rightarrow {\mathcal {Y}}\) be an random oracle with sets \({\mathcal {X}},{\mathcal {Y}}\). We implicitly assume that the elements in \({\mathcal {X}}\) and \({\mathcal {Y}}\) are expressed as bit strings. In quantum random oracle model (QROM) [7], the oracle \(\mathcal {O}\) are described as the unitary transformation \(U_{\mathcal {O}}: |x \rangle |y \rangle \rightarrow |x,y \oplus \mathcal {O}(x) \rangle \), and the adversary can query random oracles on quantum states. For an quantum adversary \(\mathcal {A}\), the notation \(\mathcal {A}^{|\mathcal {O} \rangle }\) indicates that \(\mathcal {A}\) has quantum access to the \(U_\mathcal {O}\). Without loss of generality, we directly write \(\mathcal {O}\) to denote the unitary \(U_{\mathcal {O}}\).
In this paper, we say an event is classical if it can be determined by only using classical algorithm (namely, without using any quantum mechanism).
Lemma 1 gives a probabilistic bound for adversary (has a quantum access to oracles) to distinguish \(h(s,\cdot )\) and \(h'\), where s is secret, h and \(h'\) are QRO and have the same image set. When the image is large enough, the adversary cannot distinguish these two oracles.
Lemma 1
(Lemma 2.2 in [34]). Let k be an integer. Let \(h: {\mathcal {X}}' \times \mathcal {X} \rightarrow \mathcal {Y}\) and \(h': \mathcal {X} \rightarrow \mathcal {Y}\) be two independent random oracles. If an unbounded time quantum adversary \(\mathcal {A}\) that queries h at most \(q_h\) times, then we have

3 Computational Adaptive Reprogramming in the QROM
We propose a computational adaptive reprogramming framework in the QROM. In our full version [33], we review Unruh’s adaptive O2H lemma [39] and discuss why our lemma (namely, Lemma 2) cannot be proved by using hybrid arguments of Unruh’s adaptive O2H lemma.
Let \(\mathcal {A}\) be an adversary that has quantum access to \(\mathcal {H}: {\mathcal {X}}\rightarrow {\mathcal {Y}}\) and takes \(\textsf{in}_0\) as input and terminates by outputting \(\textsf{out}_n\). During its execution, \(\mathcal {A}\) outputs some \(\textsf{out}_i\) and then takes \(\textsf{in}_{i+1}\) as input (\(0 \le i \le n-1\)). We view \(\mathcal {A}\) as a \((n+1)\)-stage adversary, \((\mathcal {A}_0,...,\mathcal {A}_n)\), where \(\mathcal {A}_i\) takes \(\textsf{in}_i\) as input and outputs \(\textsf{out}_{i}\). Here \(\textsf{in}_0, \textsf{out}_{0}, \textsf{in}_1,..., \textsf{in}_n,\) and \(\textsf{out}_n\) can be arbitrary classical information. In this paper, we consider post-quantum setting where adversaries have quantum access to hash functions. The classical information \(\textsf{in}_0, \textsf{out}_{0}, \textsf{in}_1,..., \textsf{in}_n, \textsf{out}_n\) capture the interaction between \(\mathcal {A}\) and the security game simulator, and they will be specified in a concrete use of our framework.
We write \(\mathcal {A}= (\mathcal {A}_0,...,\mathcal {A}_n)\) to divide \(\mathcal {A}\) into \(n+1\) stages for better analysis. By writing \(\textsf{out}_i \leftarrow \mathcal {A}_i(\textsf{in}_i)\) we mean that at stage i \(\mathcal {A}\) receives input \(\textsf{in}_i\) and outputs \(\textsf{out}_i\) at the end of the stage. The index indicates the stage number of \(\mathcal {A}\). So, all \(\mathcal {A}_i\) are the same adversary \(\mathcal {A}\) in different stages, and they share the quantum registers of \(\mathcal {A}\). The same notation (of dividing \(\mathcal {A}\) into different stages) is also used in Unruh’s adaptive O2H lemma [39].
Games \(\textsc {NonAda}\) and \(\textsc {Ada}\) (as in Fig. 4) are used to define our framework. \(\mathcal {A}\) has quantum access to \(\mathcal {H}\) which is either \(\textsf{H}\) or \(\textsf{H}_i\). In \(\textsc {NonAda}\), \(\textsf{H}\) will never get reprogrammed, while in \(\textsc {Ada}\) different stages of \(\mathcal {A}\) will have access to different ROs \(\textsf{H}_i\). That is, \(\mathcal {A}_i\) queries \(\textsf{H}_{i}\), and according to \(\mathcal {A}_i\)’s output \(\textsf{out}_{i}\) \(\textsf{H}_{i}\) will be reprogrammed and become \(\textsf{H}_{i+1}\) (cf. Items 07, 17 and 18). To formalize this, we define three algorithms \(\texttt{INIT}\), \(\textsf{F}_\textbf{s}\), and \(\textsf{Repro}_\textbf{s}\) in Fig. 4 as:
-
\(\texttt{INIT}\) outputs \(({(\textbf{s},\textsf{in}_0)}, \textsf{H}, \textsf{H}_0)\) (cf. Items 01 and 11), where \(\textbf{s}\) is some parameter that used in a security reduction, \(\textsf{in}_0\) is the initial input to \(\mathcal {A}\), and \(\textsf{H}\) and \(\textsf{H}_0\) are two random oracles. Here the tuple \(({(\textbf{s},\textsf{in}_0)}, \textsf{H}, \textsf{H}_0)\) may have an arbitrary joint distribution.
-
\(\textsf{F}_\textbf{s}\) takes \(\textsf{out}_i\) as input and computes \((\textsf{in}_{i+1}, \textsf{in}'_{i+1})\), where \(\textsf{in}_{i+1}\) is the input to \(\mathcal {A}_{i+1}\) and \(\textsf{in}'_{i+1}\) is the information for reprogramming \(\textsf{H}_i\). Here \(\textsf{in}'_{i+1}\) is used to capture the fact that \(\mathcal {H}\) can be reprogrammed according to \(\mathcal {A}_{i}\)’s behavior, and the algorithm \(\textsf{Repro}_\textbf{s}\) (described below) will take it as input. To make our lemma general and useful for a wider class of applications, we only require that \(\textsf{F}_\textbf{s}\) does not have access to random oracles.
-
\(\textsf{Repro}_\textbf{s}\) is defined to reprogram \(\mathcal {H}\) in \(\textsc {Ada}\) (cf. Item 17). \(\textsf{Repro}_{\textbf{s}}\) takes \(\textsf{in}'_{i}\) and \(\textsf{H}_{i-1}\) as input. It returns a random oracle \(\textsf{H}_{i}\) which is from reprogramming \(\textsf{H}_{i-1}\). The concrete reprogramming operation of \(\textsf{Repro}_\textbf{s}\) depends on the concrete use of our framework. Here we only require \(\textsf{Repro}_\textbf{s}\) to be deterministic.

Games \(\textsc {NonAda}\) and \(\textsc {Ada}\) used in Lemma 2. The main difference between two games is highlighted with gray box. In both games, \(\mathcal {A}\) is divided into \(n+1\) stages, namely, \((\mathcal {A}_0,...,\mathcal {A}_n)\). The input and output of \(\mathcal {A}\) in each stage are classical information because we consider post-quantum settings. The list \(\varGamma \) stores \(\mathcal {A}\)’s outputs in each stage. \(\textsf{F}_\textbf{s}\) is a deterministic algorithm that provides inputs for each stage of \(\mathcal {A}\). \(\textsf{Repro}_\textbf{s}\) is a deterministic algorithm that reprograms QROs. For a concise presentation, we assume that \(\mathcal {A}_i\) takes \(\mathcal {A}_{i-1}\)’s final state as its initial state. In our framework, \(\textsf{H}_0\) can be different to \(\textsf{H}\).
Let \(S_i\) be a set such that \(\textsf{H}\setminus S_i = \textsf{H}_i \setminus S_i\) (namely, for all \( x \in {\mathcal {X}}\), if \(x \in S_i\), then \(\textsf{H}(x) \ne \textsf{H}_i(x)\)). \(\mathcal {A}\) can only distinguish \(\textsc {Ada}\) and \(\textsc {NonAda}\), if it queries a \(x \in S_i\) (where \(i \in \{0,...,n\}\)). Since \(\mathcal {A}\)’s QRO queries are superposition states, we need to define extractor \(\mathcal {B}_i\) as in Fig. 5 to bound the difference between \(\textsc {NonAda}\) and \(\textsc {Ada}\). This follows the works in [27, 34, 39]. Lemma 2 formalizes our framework. Its proof is postponed to our full version [33].
Lemma 2
Let \(\mathcal {A}\) be an adversary that can be divided into \((n+1)\) stages as in Fig. 4 and has quantum access to random oracle \(\mathcal {H}\) (\(= \textsf{H}\) in \(\textsc {NonAda}\) or \(\textsf{H}_i\) in \(\textsc {Ada}\)). Let \(\textsf{Ev}\) be a classical event that may be raised by \(\mathcal {A}\) in \(\textsc {NonAda}\) or \(\textsc {Ada}\). Suppose that \(\mathcal {A}\) queries \(\mathcal {H}\) at most \(q_i\) times in its i-th stage and at most \(q:=q_0+\cdots q_n\) times in total during the game. Then for all algorithms \(\texttt{INIT}\), \(\textsf{F}_{\textbf{s}}\), and \(\textsf{Repro}_{\textbf{s}}\) (as described earlier), there exists adversaries \(\mathcal {B}_i\) for \(i \in \{0,...,n\}\) (shown in Fig. 5) such that
where \(S_i\) is a set such that \(\textsf{H}\backslash S_i = \textsf{H}_i \backslash S_i\). Such an \(S_i\) is defined by the operations in \(\textsf{Repro}_\textbf{s}\). \(\Pr \left[ \textsf{Ev}: \textsc {NonAda}^{\mathcal {A}}\right] \) and \(\Pr \left[ \textsf{Ev}: \textsc {Ada}^{\mathcal {A}}\right] \) are the probabilities that \(\mathcal {A}\) triggers \(\textsf{Ev}\) in \(\textsc {NonAda}\) and in \(\textsc {Ada}\), respectively.
 In \(\textsc {Ada}\), reprogramming the RO is captured by algorithm \(\textsf{Repro}_\textbf{s}\). How the reprogramming is done will be specified in a concrete use of Lemma 2. This is to make our framework general. The difference between \(\textsc {NonAda}\) and \(\textsc {Ada}\) is that between \(\textsf{H}\) and \(\textsf{H}_i\) caused by \(\textsf{Repro}_{\textbf{s}}\).
In \(\textsc {Ada}\), reprogramming the RO is captured by algorithm \(\textsf{Repro}_\textbf{s}\). How the reprogramming is done will be specified in a concrete use of Lemma 2. This is to make our framework general. The difference between \(\textsc {NonAda}\) and \(\textsc {Ada}\) is that between \(\textsf{H}\) and \(\textsf{H}_i\) caused by \(\textsf{Repro}_{\textbf{s}}\).

Algorithm \(\mathcal {B}_i\) (used in Lemma 2) plays Game \(\textsc {Ada}\) (where \(i \in [n]\)). \(\mathcal {B}_i\) proceeds identically with \((\mathcal {A}_1,...,\mathcal {A}_i)\), except that \(\mathcal {B}_i\) measures the \(t^*\)-th QRO query issued by \(\mathcal {A}_i\) and then outputs the measurement outcome.
Concretely, in i-th stage, \(\textsf{Repro}_\textbf{s}\) will define a set \(S_i\) such that \(\textsf{H}\setminus S_i = \textsf{H}_i \setminus S_i\). For any \(k \in \{0,...,n\}\), if \(\mathcal {A}\) queries \(\mathcal {H}\) with an \(x \in \cup _{0\le i \le k} S_k\) before the end of its k-th stage, then \(\mathcal {A}\) can distinguish \(\textsc {NonAda}\) and \(\textsc {Ada}\). To bound this in the quantum setting, our approach is to randomly measure \(\mathcal {A}\)’s queries to \(\mathcal {H}\), which is captured by \(\mathcal {B}_i\) (in Fig. 5). The advantage of \(\mathcal {A}\) distinguishing \(\textsc {NonAda}\) and \(\textsc {Ada}\) is bounded by the probability that \(\mathcal {B}_i\)’s output falls into \(S_i\).
 When defining our framework, we do not make any requirement on the efficiencies of \(\textsf{F}_{\textbf{s}}\) and \(\textsf{Repro}_{\textbf{s}}\). However, when we use this framework to construct (efficient) reduction, \(\textsf{F}_{\textbf{s}}\) and \(\textsf{Repro}_{\textbf{s}}\) are required to be efficient (namely, running in quantum probabilistic polynomial time) and the description of QRO is polynomially bounded [7, 25, 42]. For instance, we can use a 2q-independent hash function [42] and the list of reprogramming points (which are inputs to the hash and polynomial-bounded) to describe this QRO.
When defining our framework, we do not make any requirement on the efficiencies of \(\textsf{F}_{\textbf{s}}\) and \(\textsf{Repro}_{\textbf{s}}\). However, when we use this framework to construct (efficient) reduction, \(\textsf{F}_{\textbf{s}}\) and \(\textsf{Repro}_{\textbf{s}}\) are required to be efficient (namely, running in quantum probabilistic polynomial time) and the description of QRO is polynomially bounded [7, 25, 42]. For instance, we can use a 2q-independent hash function [42] and the list of reprogramming points (which are inputs to the hash and polynomial-bounded) to describe this QRO.
 By specifying \(\textsf{F}_{\textbf{s}}\) and \(\textsf{Repro}_\textbf{s}\), we can describe Grilo et al. ’s framework using our framework (though the bound of our framework is less tight than Grilo et al.’s one). In Grilo et al. ’s framework [16], the i-th output of \(\mathcal {A}\) is a distribution \(\textsf{out}_i := p_i\). \(\textsf{F}_{\textbf{s}}\) can be defined as, on input \(p_i\), it samples a reprogramming point \((x_i,x'_i)\) from \(p_i\) and an independently random \(y_i\) and outputs \((\textsf{in}_{i+1} := (x_i,x'_i), \textsf{in}'_{i+1} := (x_i,x'_i,y_i))\)Footnote 3. \(\textsf{Repro}_\textbf{s}\) can be defined as, on input \(\textsf{in}'_{i+1} := (x_i,x'_i,y_i)\), it reprograms the QRO \(\mathcal {H}:= \mathcal {H}[(x_i, x'_i) \rightarrow y_i]\) and returns the reprogrammed QRO. Their framework implicitly requires that the probability bound for \(\mathcal {A}\) to learn \(x_i,x'_i\) (before seeing them) is information-theoretic. Namely, \(p_i\) should have enough entropy. Some important advantage of our framework, compared with Grilo et al. ’s [16], are as follows:
By specifying \(\textsf{F}_{\textbf{s}}\) and \(\textsf{Repro}_\textbf{s}\), we can describe Grilo et al. ’s framework using our framework (though the bound of our framework is less tight than Grilo et al.’s one). In Grilo et al. ’s framework [16], the i-th output of \(\mathcal {A}\) is a distribution \(\textsf{out}_i := p_i\). \(\textsf{F}_{\textbf{s}}\) can be defined as, on input \(p_i\), it samples a reprogramming point \((x_i,x'_i)\) from \(p_i\) and an independently random \(y_i\) and outputs \((\textsf{in}_{i+1} := (x_i,x'_i), \textsf{in}'_{i+1} := (x_i,x'_i,y_i))\)Footnote 3. \(\textsf{Repro}_\textbf{s}\) can be defined as, on input \(\textsf{in}'_{i+1} := (x_i,x'_i,y_i)\), it reprograms the QRO \(\mathcal {H}:= \mathcal {H}[(x_i, x'_i) \rightarrow y_i]\) and returns the reprogrammed QRO. Their framework implicitly requires that the probability bound for \(\mathcal {A}\) to learn \(x_i,x'_i\) (before seeing them) is information-theoretic. Namely, \(p_i\) should have enough entropy. Some important advantage of our framework, compared with Grilo et al. ’s [16], are as follows:
-
Grilo et al. ’s framework requires the reprogramming points have high entropy and it is hard to find them even for unbounded adversary, while our framework does not have such restrictions. If \(\mathcal {A}\) is a QPPT adversary, our framework provides efficient extractors \(\mathcal {B}_i\)’s to bound the difference of \(\mathcal {A}\) in \(\textsc {NonAda}\) and \(\textsc {Ada}\). In our proofs, we need to instantiate \(\texttt{INIT}, \textsf{F}_{\textbf{s}}\), and \(\textsf{Repro}_{\textbf{s}}\) efficiently. This \(\mathcal {B}_i\) can be used to do a reduction in breaking some computational hard problem, for instance, the OW-CPA security. However, the Grilo et al. framework cannot be used to do any efficient reduction.
-
Our framework allows \(\textsc {NonAda}\) and \(\textsc {Ada}\) to start from different QROs, while the Grilo et al. framework starts from the same QRO. Starting from different QROs allows us to consider more complicated cases of adaptive reprogramming. All security proofs in this paper are examples for this, and for SO and Bi-SO security we require this.
-
Our framework also supports delayed analysis. In some complicated proofs, the difference between non-reprogramming and reprogramming games cannot be immediately bounded, and we may need extra game sequences to postpone such a bound. Our framework supports delayed analysis, since we can use extra game sequences to bound the winning probability of \(\mathcal {B}_i\) (i.e. \(\mathcal {B}_i\) outputs \(x \in S_i\)). In particular, our tightly-secure SO-CCA PKE scheme in Sect. 5 requires delayed analysis.
4 Selective Opening Security of Fujisaki-Okamoto’s PKE in the QROM
We prove the selective-opening (\(\text {SO}\)) security of two Fujisaki-Okamoto(FO)-style PKE schemes in the QROM. As a warm-up, our first scheme is \(\text {SO}\) secure against chosen-plaintext attacks (\(\text {SO}\hbox {-}\text {CPA}\)), and the scheme follows the idea of hybrid encryption. It offers a simple example about how to use our framework. Our second scheme is \(\text {SO}\) secure against chosen-ciphertext attacks (\(\text {SO}\hbox {-}\text {CCA}\)). It is the same scheme as in [35, Section 3.2], but our proof is showing adaptive \(\text {SO}\hbox {-}\text {CCA}\) security, while the original proof in [35] has a subtle gap and the gap still exists even if we consider the non-adaptive security notion (cf. discussion in Introduction).
In both schemes, let \(\textsf{PKE}:= ({\textsf{KG}}_0, \textsf{Enc}_0, \textsf{Dec}_0)\) be a \((1 - \delta )\)-correct PKE scheme with message space \(\mathcal {M}'\), ciphertext space \(\mathcal {C}'\), and randomness space \(\mathcal {R}'\). Let \(G: \mathcal {M}'\rightarrow \mathcal {R}'\) be a hash function.
4.1 Selective Opening Security Against Chosen-Plaintext Attacks
Let \(H: \mathcal {M}'\times \mathcal {C}'\rightarrow \mathcal {M}\) be a hash function. Our first PKE scheme \(\textsf{wPKE}= (\textsf{wKG}, \textsf{wEnc}, \textsf{wDec})\) (where ‘\(\textsf{w}\)’ stands for weak) with message space \(\mathcal {M}\) and is defined as in Fig. 6. Theorem 1 states that \(\textsf{wPKE}\) is adaptive \(\text {SO}\hbox {-}\text {CPA}\) secure when modeling G and H as QROs.

A \(\text {SO}\hbox {-}\text {CPA}\) secure PKE scheme \(\textsf{wPKE}= (\textsf{wKG}, \textsf{wEnc}, \textsf{wDec})\)
Theorem 1
If \(\textsf{PKE}\) is \(\text {OW}\hbox {-}\text {CPA}\) secure, then \(\textsf{wPKE}\) in Fig. 6 is adaptive \(\text {SO}\hbox {-}\text {CPA}\) secure (Definition 5). Concretely, for security parameter \(\lambda \) and \(\mu := \mu (\lambda )\) (polynomially bounded), for any SO-CPA adversary \(\mathcal {A}\) and relation \({\textsf{Rel}}\), there exist a simulator \(\mathcal {S}\) and an adversary \(\mathcal {B}'\) such that \(\textbf{T}(\mathcal {S}) \approx \textbf{T}(\mathcal {A}) \approx \textbf{T}(\mathcal {B}')\) and
where \(\mu \), \(q_G,q_H\), and \(n_{\textsc {O}}\) are the maximum numbers of \(\mathcal {A}\)’s challenge ciphertexts, \(\mathcal {A}\)’s queries to G, H, and \(\textsc {Open}\), respectively. \(q = q_G + q_H\).
Proof
Let \(h:\mathcal {M}'\times \mathcal {C}'\rightarrow \mathcal {M}\) and \(g: \mathcal {M}'\rightarrow \mathcal {R}'\) be two internal quantum-accessible random oracles that are used to respond queries to H and G, respectively. Following the convention in [25, 34], in our proof we simulate H and G using two internal quantum-accessible random oracles \(h:\mathcal {M}'\times \mathcal {C}'\rightarrow \mathcal {M}\) and \(g: \mathcal {M}'\rightarrow \mathcal {R}'\), respectively.

Games \(\textbf{G}_{0}^{}\)-\(\textbf{G}_{3}^{}\) for proving Theorem 1.
Our proof consists a sequence of games defined in Fig. 7. We will use our framework in Sect. 3 to finish the proof. To fit into the syntax of our framework, we combine G and H as one random oracle \(G \times H\) such that \(G\times H(r',r,e) := (G(r'), H(r,e))\). If \(\mathcal {A}\) only queries \(G(r')\), we view it as querying \(G\times H(r',r,e)\) for some dummy (r, e) and ignoring H(r, e) in the response. \(\mathcal {A}\) can query \(G\times H\) at most \(q = q_H + q_G\) times. This was also used in [24]. \(\textbf{G}_{0}^{}\) is equivalent to \(\textsf{REAL}\hbox {-}\textsf{SO} \hbox {-}\textsf{CPA}_{\textsf{wPKE}}\), thus
Game \(\textbf{G}_{1}^{}\): If in the challenge ciphertexts there exist \(K_i\) and \(K_j\) for \(i \ne j\) such that \(K_i = K_j\), then we abort the game. Such \(K_i\) and \(K_j\) collide only if \(r_i\) and \(r_j\) collide or \(H(r_i,e_i)\) and \(H(r_j,e_j)\) collide with different \(r_i\) and \(r_j\). By birthday bounds, and we have
Game \(\textbf{G}_{2}^{}\): \(R_i\) and \(K_i\) in the challenge ciphertexts are chosen randomly, instead of using G and H. If \(\mathcal {A}\) queries \(\textsc {Open}(i)\), then we reprogram G and H such that \(G(r_i) := R_i\) and \(H(r_i,e_i) := K_i\).
In the following, we use Lemma 2 to bound the difference between \(\textbf{G}_1\) and \(\textbf{G}_2\). In \(\textbf{G}_2\), \(\mathcal {A}\)’s \(\textsc {Open}\) queries will make QRO \(G \times H\) reprogrammed, while in \(\textbf{G}_1\), QRO \(G \times H\) does not get reprogrammed. So, we can view \(\textbf{G}_{1}^{}\) and \(\textbf{G}_{2}^{}\) as concrete cases of \(\textsc {NonAda}\) and \(\textsc {Ada}\), respectively. For simplicity, we denote \(\mathcal {A}:= (\mathcal {A}_0, (\mathcal {A}_{1,0},...,\mathcal {A}_{1,n_{\textsc {O}}}))\), where \(\mathcal {A}_0\) is the initial stage of \(\mathcal {A}\) and cannot query \(\textsc {Open}\), and \((\mathcal {A}_{1,0},...,\mathcal {A}_{1,n_{\textsc {O}}})\) is the stage that \(\mathcal {A}\) receives the challenge ciphertexts \(\textbf{c}\) and can query \(\textsc {Open}\). Let \(\mathcal {A}_1 := (\mathcal {A}_{1,0},...,\mathcal {A}_{1,n_{\textsc {O}}})\). \(\mathcal {A}_1\)’s initial state is the final state of \(\mathcal {A}_0\). \(\mathcal {A}_{1,k} \) is defined with respect to \(\textsc {Open}\) queries:
-
Before any \(\textsc {Open}\) query (i.e., at the 0-th stage), \(\mathcal {A}_{1,0}\) takes \(\textsf{in}_0:= \textbf{c}\) as input and outputs the first opening index \(\textsf{out}_0 := (i_1)\).
-
At k-th stage (\(1\le k \le n_{\textsc {O}}-1\)), \(\mathcal {A}_{1,k}\) receives \(\textsf{in}_k= (m_{i_k}, r_{i_k})\) As the result of the \((k-1)\)-th \(\textsc {Open}\) query and finishes the stage by outputting the \((k+1)\)-th opening index \(\textsf{out}_k := (i_{k+1})\)
-
Finally, at the \(n_{\textsc {O}}\) stage, \(\mathcal {A}_{1,n_{\textsc {O}}}\) receives \(\textsf{in}_{n_{\textsc {O}}} = (m_{i_{n_{\textsc {O}}}}, r_{i_{n_{\textsc {O}}}})\) and terminates by outputting \(\textsf{out}_{n_{\textsc {O}}} = out\) (the final output of SO adversary).

Constructions of \(\texttt{INIT}, \textsf{F}_{\textbf{s}}, \) and \(\textsf{Repro}_{\textbf{s}}\) and games \(\textbf{G}'_1\) and \(\textbf{G}'_2\). \(G' := G [r_i\rightarrow R_{i}]\) (similarly, \(H' := H [(r_i,e_i) \rightarrow K_i]\)) means that we set \(G'(r_i):= R_i\) and \(G'(r):=G(r)\) for \(r\ne r_i\). Oracles \(g, g' : \mathcal {M}'\rightarrow \mathcal {R}'\), and \(h, h':\mathcal {M}'\times \mathcal {C}'\rightarrow \mathcal {M}\) are four independent internal quantum-accessible random oracles.
To formally show why \(\textbf{G}_{1}^{}\) and \(\textbf{G}_{2}^{}\) are concrete cases of \(\textsc {NonAda}\) and \(\textsc {Ada}\), respectively, in Fig. 8, we define \(\texttt{INIT}\), \(\textsf{F}_{\textbf{s}}\), \(\textsf{Repro}_{\textbf{s}}\), \(\textbf{G}'_1\) and \(\textbf{G}'_2\). Games \(\textbf{G}'_1\) and \(\textbf{G}'_2\) are only defined to show how our proof follows the syntax of our framework. They have the same forms as \(\textsc {NonAda}\) and \(\textsc {Ada}\).
Now we argue that \(\textbf{G}_{1}^{}\) and \(\textbf{G}_{2}^{}\) are concrete cases of \(\textsc {NonAda}\) and \(\textsc {Ada}\), respectively. Namely, \(\textbf{G}_{1}\) and \(\textbf{G}_{2}\) in Fig. 7 are equivalent to \(\textbf{G}'_{1}\) and \(\textbf{G}'_{2}\) in Fig. 8, respectively. Firstly, algorithm \(\texttt{INIT}\) in Fig. 8 run the codes from Item 01 to Item 12 in Fig. 7. Since in \(\mathcal {A}_0\)’s view, \(\textbf{G}_1\) is the same as \(\textbf{G}_2\) (it does not see any challenge ciphertexts), the distribution of \(\mathcal {M}_a\) and \(\textbf{m}\) in \(\textbf{G}_1\) is the same as the one in \(\textbf{G}_2\), and thus the output of \(\texttt{INIT}\) and the final state of \(\mathcal {A}_0\) in \(\texttt{INIT}\) in \(\textbf{G}'_{1}\) are the same as those in \(\textbf{G}'_2\). Secondly, \(\textsf{F}_\textbf{s}\) simulates the \(\textsc {Open}\) oracle and \(\textsf{Repro}_{\textbf{s}}\) simulates the reprogramming operations on G and H. In \(\textbf{G}'_1\), G and H will not be reprogrammed, but in \(\textbf{G}'_2\), G and H will be reprogrammed, according to \(\mathcal {A}\)’s output. This is the same as in \(\textbf{G}_2\).
Moreover, when running \(\mathcal {A}_{1,k}\), our \(\textsf{Repro}_{\textbf{s}}\) defines a set
where \(I_{k} := \{i_1,...,i_{k}\}\) is the opening index set \(I\) in \(\mathcal {A}_1\)’s k-th stage. Answers of \(G \times H\) on \(S_k\) are only different in \(\textbf{G}_{1}^{}\) (i.e., \(\textsc {NonAda}\)) and \(\textbf{G}_{2}^{}\) (i.e., \(\textsc {Ada}\)). For \(k = 0\), \(S_0\) is defined at line 35 and \(I_0 = \emptyset \).
Now we consider the probability that \({\textsf{Rel}}(\mathcal {M}_a, \textbf{m}, I,out) = 1\). \(I\) and \(out\) are determined by \(\mathcal {A}_1\). \(\mathcal {M}_a\) is output by \(\mathcal {A}_0\), and \(\textbf{m}\) is determined by \(\mathcal {M}_a\). Since in \(\mathcal {A}_0\)’s view, \(\textbf{G}_1\) is the same as \(\textbf{G}_2\) (since it does not see challenge ciphertexts), thus the distribution of \(\mathcal {M}_a\) and \(\textbf{m}\) in \(\textbf{G}_1\) is the same as the one in \(\textbf{G}_2\). Therefore, the probability difference between the classical event that \({\textsf{Rel}}(\mathcal {M}_a, \textbf{m}, I,out) = 1\) in \(\textbf{G}_1\) and the similar event in \(\textbf{G}_2\), is determined by the probability difference between the event that \(\mathcal {A}_1\) outputs a particular \((I,out)\) (i.e., \(\varGamma \) in Fig. 8) in \(\textbf{G}_1\) and the similar event in \(\textbf{G}_2\). Therefore, we have
This bound includes a term \(\frac{2\mu q}{\sqrt{|\mathcal {M}'|}}\), since \(\mathcal {A}_0\) also has quantum access to \(|G \times H \rangle \), and this term is the probability that the first stage (i.e., \(\mathcal {A}_{1,0}\)) of \(\mathcal {A}_{1}\) learns \(r_i\) before seeing challenge ciphertexts. Such probability is only information-theoretic.
We now use Lemma 2 to bound Eq. (4). Since \(\textbf{G}'_{1}\) is a \(\textsc {NonAda}\) game and \(\textbf{G}'_{2}\) is an \(\textsc {Ada}\) game, by Lemma 2, there exist adversaries \(\mathcal {B}_i\) (\(0 \le i \le n_{\textsc {O}}\)), which take \(\textsf{in}_0 = \textbf{c}\) as its input and output \(x \in S_k\) where the set \(S_i\) is defined in (3), such that
Here \(\mathcal {B}_i\) proceeds the same as \((\mathcal {A}_{1,0},...,\mathcal {A}_{1,i})\) except that it randomly measures a QRO query issued by \(\mathcal {A}_{1,i}\). Moreover, since \(\mathcal {A}_{1,0}\)’s initial state is the final state of \(\mathcal {A}_0\), \(\mathcal {B}_i\) starts with state of \(\mathcal {A}_0\) (cf. Item 07).

The constructions of OW-CPA adversaries \(\mathcal {B}'_i\) for \(i \in \{0,...,n_{\textsc {O}}\}\). \(\mathcal {B}'_i\) simulates \(\textbf{G}'_2\) (which is a concrete case of \(\textsc {Ada}\) in Fig. 4) for \(\mathcal {B}_i\) to break \(\textsf{PKE}\). \(\textsf{F}\) and \(\textsf{Repro}\) are defined as in Fig. 8.
Based on \(\mathcal {B}_i\), we construct an adversary \(\mathcal {B}'_i\) (in Fig. 9) to break OW-CPA security of \(\textsf{PKE}\). By the construction of \(\mathcal {B}'_i\), if \(\mathcal {A}_1\) does not open \(t^*\), and r or \(r'\) equals the solution of \(e^*\), then \(\mathcal {B}'_i\) wins. So the winning probability for \(\mathcal {B}'_i\) to break the OW-CPA challenge is:
and thus we have
Let \(\mathcal {B}'\) be the adversary that has highest advantage against \(\textsf{PKE}\) among \(\{\mathcal {B}'_i\}_{i \in \{0,...,n\}}\). Then Eq. (6) can be written as:
By combining Eqs. (4) to (7), we have
Game \(\textbf{G}_{3}^{}\): We change the generation of \(K_i\) and \(d_i\). Now we firstly sample \(d_i\) uniformly at random, and replace all \(K_i\) as \(d_i \oplus m_i\). This change is conceptual since in \(\textbf{G}_{2}^{}\), all \(K_i\) are independently and uniformly random. In \(\textbf{G}_{1}^{}\), we excluded any collision of \(K_i\), so, in \(\textbf{G}_{3}^{}\), it is equivalent to sample \(d_i\) in a collision-free way. Therefore, we have

The simulator \(\mathcal {S}\) of the proof of Theorem 1.
 We construct a SO simulator \(\mathcal {S}\) that is simulating \(\textbf{G}_{3}^{}\) for \(\mathcal {A}\) and interacts with the \({\textsf{IDEAL}\hbox {-}\textsf{SO} \hbox {-}\textsf{CPA}}^{\mathcal {S}}_{\textsf{wPKE}}\) game. The simulation process is shown in Fig. 10. Obviously, \(\mathcal {S}\) can perfectly simulates \(\textbf{G}_{3}^{}\). So, we have
We construct a SO simulator \(\mathcal {S}\) that is simulating \(\textbf{G}_{3}^{}\) for \(\mathcal {A}\) and interacts with the \({\textsf{IDEAL}\hbox {-}\textsf{SO} \hbox {-}\textsf{CPA}}^{\mathcal {S}}_{\textsf{wPKE}}\) game. The simulation process is shown in Fig. 10. Obviously, \(\mathcal {S}\) can perfectly simulates \(\textbf{G}_{3}^{}\). So, we have
In conclusion, for any SO-CPA adversary \(\mathcal {A}\), there exists efficient simulator \(\mathcal {S}\) such that
4.2 Selective Opening Security Against Chosen-Ciphertext Attacks
Let \(\textsf{MAC}= (\textsf{Tag}, \textsf{Vrfy})\) be a MAC scheme with key space \(\mathcal {K}^\texttt{mac}\), and let \(H: \mathcal {R}'\times \mathcal {C}'\rightarrow \mathcal {M}\times \mathcal {K}^\texttt{mac}\) be a hash function, where \(\mathcal {C}\) is the ciphertext space of \(\textsf{PKE}\). The second PKE scheme \(\textsf{sPKE}= (\textsf{sKG}, \textsf{sEnc}, \textsf{sDec})\) (Fig. 11) is a combination of a modular Fujisaki-Okamoto’s transformation  [21, 24], one-time pad, and the one-time MAC scheme \(\textsf{MAC}\). It has similar structure with the scheme in [18, 35].
[21, 24], one-time pad, and the one-time MAC scheme \(\textsf{MAC}\). It has similar structure with the scheme in [18, 35].

A \(\text {SO}\hbox {-}\text {CCA}\) secure PKE scheme \(\textsf{sPKE}= (\textsf{sKG},\textsf{sEnc},\textsf{sDec})\)
This scheme is adaptive \(\text {SO}\hbox {-}\text {CCA}\) secure when modeling G and H as QROs, as stated in Theorem 2. The main difference between the proof of Theorem 2 and the one of Theorem 1 is that the simulator needs to simulate the decryption oracle for the adversary. We use the encrypt-then-hash technique (widely used in CCA proof of PKE [24, 27, 34]) to simulate the decryption oracle without using the secret key and add a MAC verification in the decryption so that the adversary cannot forge valid MAC codes for any unopened cipheretext. We postpone the proof of Theorem 2 to our full version [33].
Theorem 2
If \(\textsf{PKE}\) is \(\text {OW}\hbox {-}\text {CPA}\) secure and \(\delta \)-correct, and \(\textsf{MAC}\) is \(\text {otSUF}\hbox {-}{\text {CMA}}\) secure, then the PKE scheme \(\textsf{sPKE}\) in Fig. 11 is adaptive \(\text {SO}\hbox {-}\text {CCA}\) secure (Definition 5). Concretely, for security parameter \(\lambda \) and integer \(\mu := \mu (\lambda )\) (polynomially bounded) for any \(\text {SO}\hbox {-}\text {CCA}\) adversary \(\mathcal {A}\) and relation \({\textsf{Rel}}\), there exist a simulator \(\mathcal {S}\) and adversaries \(\mathcal {B}'\) and \(\mathcal {F}\) such that \(\textbf{T}(\mathcal {S}) \approx \textbf{T}(\mathcal {A}) \approx \textbf{T}(\mathcal {B}') \approx \textbf{T}(\mathcal {F})\) and
where \(\mu \), \(q_G,q_H,n_{\textsc {O}}\), and \(n_{\textsc {D}}\) are the maximum numbers of \(\mathcal {A}\)’s challenge ciphertexts, \(\mathcal {A}\)’s queries to \(G,H,\textsc {Open}\), and \(\textsc {Dec}\), respectively. \(q = q_G + q_H\).
5 Tight SO-CCA Security from Lossy Encryption
In this section, we show that if the underlying PKE is a lossy encryption [3, 22], then the construction in Fig. 11 is tightly SO-CCA secure. We recall the notion of lossy encryption from [22].
Definition 7
(Lossy Encryption [22]). Let \(\textsf{PKE}_1:= (\textsf{KG}_1, \textsf{Enc}_1, \textsf{Dec}_1)\) be a PKE scheme with message space \(\mathcal {M}'\) and randomness space \(\mathcal {R}'\). \(\textsf{PKE}_1\) is lossy if it has the following properties:
-
\(\textsf{PKE}_1\) is correct according to Definition 2.
-
Key indistinguishability: We say \(\textsf{PKE}_1\) has key indistinguishability if there is an algorithm \(\textsf{LKG}_1\) such that, for any adversary \(\mathcal {B}\), the advantage function
$$ \textsf{Adv}^{\textsf{ind}\hbox {-}\textsf{key}}_{\textsf{PKE}_1}(\mathcal {B}) := | \Pr \left[ \mathcal {B}(\textsf{pk}_1) \Rightarrow 1 \right] - \Pr \left[ \mathcal {B}(\textsf{lpk}_1) \Rightarrow 1 \right] | $$is negligible, where \((\textsf{pk}_1,\textsf{sk}_1) \leftarrow \textsf{KG}_1\) and \((\textsf{lpk}_1,\textsf{lsk}_1) \leftarrow \textsf{LKG}_1\).
-
Lossiness: Let \((\textsf{lpk}_1,\textsf{lsk}_1) \leftarrow \textsf{LKG}_1\) and \(m, m'\) be arbitrary messages in \(\mathcal {M}'\), the statistical distance between \(\textsf{Enc}_1(\textsf{lpk}_1,m)\) and \(\textsf{Enc}_1(\textsf{lpk}_1, m')\) is negligible.
-
Weak Openability: Let \((\textsf{lpk}_1,\textsf{lsk}_1) \leftarrow \textsf{KG}_1\), \(m\) and \(m'\) be arbitrary messages, and \(r\) be arbitrary randomness. For ciphertext \(c := \textsf{Enc}_1(\textsf{lpk}_1, m; r)\), there exists an algorithm \(\textsf{open}_1\) such that \(\textsf{open}_1(\textsf{lsk}_1,\textsf{lpk}_1,c,r,m')\) outputs \(r'\) where \(c = \textsf{Enc}_1(\textsf{lpk}_1, m';r')\) and \(r'\) is distributed uniformly. \(\textsf{open}_1\) can be inefficient.
The lossiness definition can be extended to a multi-challenge version using a hybrid argument. Since it is only a statistical property, the hybrid argument will not affect tightness of the computational advantage.
Definition 8
(Multi-challenge Lossiness). For any arbitrary messages \(m_1, m'_1,...,m_\mu , m'_\mu \in \mathcal {M}'\), the statistical distance between the following distributions D and \(D'\) is at most \({\epsilon }^{\textsf{m}\hbox {-}\textsf{ind}\hbox {-}\textsf{enc}}_{\textsf{PKE}_1}\), where \({\epsilon }^{\textsf{m}\hbox {-}\textsf{ind}\hbox {-}\textsf{enc}}_{\textsf{PKE}_1}\) is negligible:
5.1 Construction
Let \(\textsf{PKE}_1=(\textsf{KG}_1,\textsf{Enc}_1,\textsf{Dec}_1)\) be a lossy encryption with message space \(\mathcal {M}'\), randomness space \(\mathcal {R}'\), ciphertext space \(\mathcal {C}'\), and an opening algorithm \(\textsf{open}_1\). Let \(\textsf{MAC}= (\textsf{Tag}, \textsf{Vrfy})\) be a MAC scheme with key space \(\mathcal {K}^\texttt{mac}\), and \(G: \mathcal {M}'\rightarrow \mathcal {R}', H: \mathcal {M}'\times \mathcal {C}'\rightarrow \mathcal {M}\times \mathcal {K}^\texttt{mac}\) be two hash functions. Our PKE scheme \(\textsf{sPKE}= (\textsf{sKG}, \textsf{sEnc}, \textsf{sDec})\) is defined in Fig. 12, which has the same structure with the scheme in Fig. 11.

A PKE scheme \(\textsf{sPKE}= (\textsf{sKG},\textsf{sEnc},\textsf{sDec})\) based on lossy encryption \(\textsf{PKE}_1\).
Theorem 3 shows that \(\textsf{sPKE}\) is tightly \(\text {SO}\hbox {-}\text {CCA}\) secure when modeling G and H as QROs. Although there is a loss \(\mu \) to the \(\text {otSUF}\hbox {-}{\text {CMA}}\) security of the underlying MAC, if one can use a perfectly \(\text {otSUF}\hbox {-}{\text {CMA}}\) secure MAC (e.g., the efficient one implicitly in [26]), it will not affect the security loss of \(\textsf{sPKE}\) and thus \(\textsf{sPKE}\) is tight.
Theorem 3
If \(\textsf{PKE}_1\) is a lossy encryption scheme and \((1-\delta )\)-correct, and \(\textsf{MAC}\) is \(\text {otSUF}\hbox {-}{\text {CMA}}\) secure, then the PKE scheme \(\textsf{sPKE}\) in Fig. 12 is adaptive \(\text {SO}\hbox {-}\text {CCA}\) secure (Definition 5). Concretely, for security parameter \(\lambda \) and integer \(\mu := \mu (\lambda )\) (which is polynomially bounded) for any \(\text {SO}\hbox {-}\text {CCA}\) adversary \(\mathcal {A}\) and relation \({\textsf{Rel}}\), there exist a simulator \(\mathcal {S}\) and an adversary \(\mathcal {F}\) with \(\textbf{T}(\mathcal {S}) \approx \textbf{T}(\mathcal {A})\), \(\textbf{T}(\mathcal {F}) \approx \textbf{T}(\mathcal {A})\), and
where \(\mu \), \(q_G,q_H,n_{\textsc {O}}\), and \(n_{\textsc {D}}\) are the maximum numbers of \(\mathcal {A}\)’s challenge ciphertexts, \(\mathcal {A}\)’s queries to \(G,H,\textsc {Open}\), and \(\textsc {Dec}\), respectively. \(q = q_G + q_H\).
For simplicity, here we only sketch the proof idea and the formal proof of Theorem 3 is postponed to our full version [33]. Roughly, we firstly use the encrypt-then-hash technique [24, 27, 34] to change security games so that the simulator can simulate decryption oracle without using secret key. Then, we switch the public key of \(\textsf{PKE}_1\) to the lossy mode. By the key indistinguishability of \(\textsf{PKE}_1\), the adversary cannot detect such modification, and the simulation of decryption oracle still works. However, although the public key is switched to lossy mode, we cannot use the lossiness of \(\textsf{PKE}_1\) directly, since there are several correlations between challenge ciphertexts and the QROs. Therefore, at the end of the proof, we use our adaptive reprogramming framework in Sect. 3 and delayed analysis to derelate QROs and challenge ciphertexts, and argue that the adversary cannot learn any information of unopened challenge ciphertexts.
 The Regev encryption scheme as defined in [15] is essentially a lossy encryption, and we can use it to instantiate our generic construction in Fig. 12. For completeness, we describe the lossy encryption in our full version [33]. Our resulting LWE-based \(\text {SO}\hbox {-}\text {CCA}\) secure PKE is unfortunately only almost tight, since the LWE-based lossy encryption loses a factor depending on the security parameter.
The Regev encryption scheme as defined in [15] is essentially a lossy encryption, and we can use it to instantiate our generic construction in Fig. 12. For completeness, we describe the lossy encryption in our full version [33]. Our resulting LWE-based \(\text {SO}\hbox {-}\text {CCA}\) secure PKE is unfortunately only almost tight, since the LWE-based lossy encryption loses a factor depending on the security parameter.
6 Bi-sO Security in the QROM
In this section, we show that two PKE schemes are Bi-sO-CCA secure in the QROM. The first scheme is based on a modular FO transformation  [21, 24] (Sect. 6.1). The second scheme is based on another modular FO transformation
[21, 24] (Sect. 6.1). The second scheme is based on another modular FO transformation  [21] (Sect. 6.2).
[21] (Sect. 6.2).
6.1 Bi-sO Security of 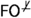
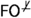
We show that a multi-user version of \(\textsf{sPKE}\) (Fig. 11) is \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\)-secure in the QROM. Using the same building blocks \(\textsf{PKE}= ({\textsf{KG}}_0, \textsf{Enc}_0,\textsf{Dec}_0)\) and \(\textsf{MAC}\) as \(\textsf{sPKE}\), we propose \(\textsf{sPKE}_{\textsf{bi}}\) (in Fig. 13). This scheme can be viewed as a combination of a modular FO transformation  in [21, 24], one-time pad, and the a MAC scheme \(\textsf{MAC}\). Moreover, in \(\textsf{sPKE}_{\textsf{bi}}\), each user includes its public key as an input to the hash functions \(G,H,H'\).
in [21, 24], one-time pad, and the a MAC scheme \(\textsf{MAC}\). Moreover, in \(\textsf{sPKE}_{\textsf{bi}}\), each user includes its public key as an input to the hash functions \(G,H,H'\).
Theorem 4 shows that \(\textsf{sPKE}_{\textsf{bi}}\) is \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) secure when modeling G and H as QROs. The proof of Theorem 4 is more complicated than the proofs of Theorem 2, since we also need to simulate \(\textsc {Corrupt}\) oracle. But the proof idea is similar: we change the games so that the game simulator can use the encrypt-then-hash technique to simulate \(\textsc {Dec}\) (as we did in the proof of Theorem 2). To use our framework, we divide \(\mathcal {A}_1\) with respect to \(\textsc {Corrupt}\) and \(\textsc {Dec}\), since the operations of \(\textsc {Corrupt}\) also reprograms \(G \times H\). The proof of Theorem 4 is postponed to our full version [33].

A \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) secure PKE scheme \(\textsf{sPKE}_{\textsf{bi}}= (\textsf{sKG},\textsf{sEnc},\textsf{sDec})\)
Theorem 4
If \(\textsf{PKE}\) is \(\text {OW}\hbox {-}\text {CPA}\) secure, then the PKE scheme \(\textsf{sPKE}_{\textsf{bi}}\) in Fig. 13 is adaptive \( \text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) secure (Definition 6). Concretely, for any adversary \(\mathcal {A}\) and relation \({\textsf{Rel}}\), there exist a simulator \(\mathcal {S}\) and adversaries \(\mathcal {B}'\) and \(\mathcal {F}\) such that \(\textbf{T}(\mathcal {S}) \approx \textbf{T}(\mathcal {A}) \approx \textbf{T}(\mathcal {B}') \approx \textbf{T}(\mathcal {F})\) and
where \(p,\mu \), \(q_G,q_H, q_{H'},n_{\textsc {O}},n_{\textsc {C}}\), and \(n_{\textsc {D}}\) are the number of user in the games and the maximal numbers of challenge ciphertexts per users, \(\mathcal {A}\)’s queries to \(G,H,H',\textsc {Open}\), \(\textsc {Corrupt}\), and \(\textsc {Dec}\), respectively. \(q = q_G + q_H\).
6.2 Bi-sO Security of 

Let \(\textsf{PKE}= ({\textsf{KG}}_0,\textsf{Enc}_0,\textsf{Dec}_0)\) be a deterministic PKE scheme with public space \(\mathcal{P}\mathcal{K}'\), plaintext space \(\mathcal {M}'\), ciphertext space \(\mathcal {C}'\), and plaintext distribution \(\mathcal {D}_{\mathcal {M}'}\). Lett \(\textsf{MAC}\) be a one-time MAC as in \(\textsf{sPKE}_{\textsf{bi}}\). Let \(H: \mathcal{P}\mathcal{K}'\times \mathcal {M}'\rightarrow \mathcal {M}\times \mathcal {K}^\texttt{mac}\) and \(H': \mathcal{P}\mathcal{K}'\times \mathcal {M}'\times \mathcal {C}'\rightarrow \mathcal {M}\times \mathcal {K}^\texttt{mac}\) be two hash functions. We define \(\textsf{sPKE}^\textsf{m}_{\textsf{bi}}\) as in Fig. 14. \(\textsf{sPKE}^\textsf{m}_{\textsf{bi}}\) can be viewed as a combination of  [21], one-time pad and one-time MAC. Similar to \(\textsf{sPKE}_{\textsf{bi}}\), each user includes its public key into the input of hash functions.
[21], one-time pad and one-time MAC. Similar to \(\textsf{sPKE}_{\textsf{bi}}\), each user includes its public key into the input of hash functions.

A \({\textsf{Bi}\hbox {-}\textsf{SO}\hbox {-}\textsf{CCA}}\) secure PKE scheme \(\textsf{sPKE}^\textsf{m}_{\textsf{bi}}= (\textsf{sKG}^\textsf{m}_{\textsf{bi}},\textsf{sEnc}^\textsf{m}_{\textsf{bi}},\textsf{sDec}^\textsf{m}_{\textsf{bi}})\)
Here we consider a variant of OW-CPA security: \(\mathcal {D}_{\mathcal {M}'}\)-\(\textsf{OW}\text{- }\textsf{CPA}\) security, namely, \(\textsf{OW}\text{- }\textsf{CPA}\) security with challenge messages chosen following \(\mathcal {D}_{\mathcal {M}'}\). For simplicity, the definition of of \(\mathcal {D}_{\mathcal {M}'}\)-\(\textsf{OW}\text{- }\textsf{CPA}\) is given in our full version [33]. Moreover, we require that \(\textsf{PKE}\) is rigid correct [5], namely, for all \((\textsf{pk},\textsf{sk})\) generated from \({\textsf{KG}}_0\), ciphertext e, and plaintext r, \((e = \textsf{Enc}_0(\textsf{pk},r)) \) if and only if \( (\textsf{Dec}_0(\textsf{sk},e) = r)\). Theorem 5 shows that \(\textsf{sPKE}^\textsf{m}_{\textsf{bi}}\) is Bi-sO-CCA secure when modeling G, H, and \(H'\) as QROs. The proof of Theorem 5 is similar to Theorem 4, and is postponed to our full version [33].
Theorem 5
Let \(\textsf{PKE}\) be a deterministic PKE with perfect correctness and rigidity. If \(\textsf{PKE}\) is \(\mathcal {D}_{\mathcal {M}'}\)-\(\text {OW}\hbox {-}\text {CPA}\) secure, then the PKE scheme \(\textsf{sPKE}^\textsf{m}_{\textsf{bi}}\) in Fig. 14 is adaptive \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) secure (Definition 6). Concretely, for any \(\text {Bi}\hbox {-}\text {SO}\hbox {-}\text {CCA}\) adversary \(\mathcal {A}\) and relation \({\textsf{Rel}}\), there exist a simulator \(\mathcal {S}\) and adversaries \(\mathcal {B}^\text {ow}\) and \(\mathcal {F}\) such that \(\textbf{T}(\mathcal {S}) \approx \textbf{T}(\mathcal {A}) \approx \textbf{T}(\mathcal {B}') \approx \textbf{T}(\mathcal {F})\) and
where \(p,\mu \), \(q_H, q_{H'},n_{\textsc {O}},n_{\textsc {C}}\), and \(n_{\textsc {D}}\) are the maximum numbers of user in the games and \(\mathcal {A}\)’s challenge ciphertexts per users, \(\mathcal {A}\)’s queries to \(H,H',\textsc {Open}\), \(\textsc {Corrupt}\), and \(\textsc {Dec}\), respectively. \(\epsilon _{\mathcal {D}_{\mathcal {M}'}}\) is the minimum entropy of \(\mathcal {D}_{\mathcal {M}'}\).
Notes
- 1.
The authors confirmed this to us.
- 2.
- 3.
The randomness for sampling can be included in \(\textbf{s}\), since it is captured by the game simulator.
References
Ambainis, A., Hamburg, M., Unruh, D.: Quantum security proofs using semi-classical oracles. In: Boldyreva, A., Micciancio, D. (eds.) CRYPTO 2019, Part II. LNCS, vol. 11693, pp. 269–295. Springer, Heidelberg (2019). https://doi.org/10.1007/978-3-030-26951-7_10
Bellare, M., Dowsley, R., Waters, B., Yilek, S.: Standard security does not imply security against selective-opening. In: Pointcheval, D., Johansson, T. (eds.) EUROCRYPT 2012. LNCS, vol. 7237, pp. 645–662. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-29011-4_38
Bellare, M., Hofheinz, D., Yilek, S.: Possibility and impossibility results for encryption and commitment secure under selective opening. In: Joux, A. (ed.) EUROCRYPT 2009. LNCS, vol. 5479, pp. 1–35. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-01001-9_1
Bellare, M., Rogaway, P.: The security of triple encryption and a framework for code-based game-playing proofs. In: Vaudenay, S. (ed.) EUROCRYPT 2006. LNCS, vol. 4004, pp. 409–426. Springer, Heidelberg (2006). https://doi.org/10.1007/11761679_25
Bernstein, D.J., Persichetti, E.: Towards KEM unification. Cryptology ePrint Archive, Report 2018/526 (2018). https://ia.cr/2018/526
Böhl, F., Hofheinz, D., Kraschewski, D.: On definitions of selective opening security. In: Fischlin, M., Buchmann, J., Manulis, M. (eds.) PKC 2012. LNCS, vol. 7293, pp. 522–539. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-30057-8_31
Boneh, D., Dagdelen, Ö., Fischlin, M., Lehmann, A., Schaffner, C., Zhandry, M.: Random oracles in a quantum world. In: Lee, D.H., Wang, X. (eds.) ASIACRYPT 2011. LNCS, vol. 7073, pp. 41–69. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-25385-0_3
Chen, C., et al.: NTRU. Technical report, National Institute of Standards and Technology (2020). https://csrc.nist.gov/projects/post-quantum-cryptography/post-quantum-cryptography-standardization/round-3-submissions
D’Anvers, J.P., et al.: SABER. Technical report, National Institute of Standards and Technology (2020). https://csrc.nist.gov/projects/post-quantum-cryptography/post-quantum-cryptography-standardization/round-3-submissions
Don, J., Fehr, S., Majenz, C.: The measure-and-reprogram technique 2.0: multi-round fiat-shamir and more. In: Micciancio, D., Ristenpart, T. (eds.) CRYPTO 2020, Part III. LNCS, vol. 12172, pp. 602–631. Springer, Heidelberg (2020). https://doi.org/10.1007/978-3-030-56877-1_21
Fehr, S., Hofheinz, D., Kiltz, E., Wee, H.: Encryption schemes secure against chosen-ciphertext selective opening attacks. In: Gilbert, H. (ed.) EUROCRYPT 2010. LNCS, vol. 6110, pp. 381–402. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-13190-5_20
Fujisaki, E., Okamoto, T.: How to enhance the security of public-key encryption at minimum cost. In: Imai, H., Zheng, Y. (eds.) PKC 1999. LNCS, vol. 1560, pp. 53–68. Springer, Heidelberg (1999). https://doi.org/10.1007/3-540-49162-7_5
Fujisaki, E., Okamoto, T.: Secure integration of asymmetric and symmetric encryption schemes. In: Wiener, M.J. (ed.) CRYPTO 1999. LNCS, vol. 1666, pp. 537–554. Springer, Heidelberg (Aug (1999). https://doi.org/10.1007/3-540-48405-1_34
Fujisaki, E., Okamoto, T.: Secure integration of asymmetric and symmetric encryption schemes. J. Cryptol. 26(1), 80–101 (2013)
Gentry, C., Peikert, C., Vaikuntanathan, V.: Trapdoors for hard lattices and new cryptographic constructions. In: Ladner, R.E., Dwork, C. (eds.) 40th ACM STOC, pp. 197–206. ACM Press (2008)
Grilo, A.B., Hövelmanns, K., Hülsing, A., Majenz, C.: Tight adaptive reprogramming in the QROM. In: Tibouchi, M., Wang, H. (eds.) ASIACRYPT 2021, Part I. LNCS, vol. 13090, pp. 637–667. Springer, Heidelberg (2021). https://doi.org/10.1007/978-3-030-92062-3_22
Hemenway, B., Libert, B., Ostrovsky, R., Vergnaud, D.: Lossy encryption: constructions from general assumptions and efficient selective opening chosen ciphertext security. In: Lee, D.H., Wang, X. (eds.) ASIACRYPT 2011. LNCS, vol. 7073, pp. 70–88. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-25385-0_4
Heuer, F., Jager, T., Kiltz, E., Schäge, S.: On the selective opening security of practical public-key encryption schemes. In: Katz, J. (ed.) PKC 2015. LNCS, vol. 9020, pp. 27–51. Springer, Heidelberg (2015). https://doi.org/10.1007/978-3-662-46447-2_2
Heuer, F., Poettering, B.: Selective opening security from simulatable data encapsulation. In: Cheon, J.H., Takagi, T. (eds.) ASIACRYPT 2016, Part II. LNCS, vol. 10032, pp. 248–277. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-53890-6_9
Hofheinz, D.: All-but-many lossy trapdoor functions. In: Pointcheval, D., Johansson, T. (eds.) EUROCRYPT 2012. LNCS, vol. 7237, pp. 209–227. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-29011-4_14
Hofheinz, D., Hövelmanns, K., Kiltz, E.: A modular analysis of the Fujisaki-Okamoto transformation. In: Kalai, Y., Reyzin, L. (eds.) TCC 2017, Part I. LNCS, vol. 10677, pp. 341–371. Springer, Heidelberg (2017). https://doi.org/10.1007/978-3-319-70500-2_12
Hofheinz, D., Jager, T., Rupp, A.: Public-key encryption with simulation-based selective-opening security and compact ciphertexts. In: Hirt, M., Smith, A.D. (eds.) TCC 2016-B, Part II. LNCS, vol. 9986, pp. 146–168. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-53644-5_6
Hofheinz, D., Rupp, A.: Standard versus selective opening security: separation and equivalence results. In: Lindell, Y. (ed.) TCC 2014. LNCS, vol. 8349, pp. 591–615. Springer, Heidelberg (2014). https://doi.org/10.1007/978-3-642-54242-8_25
Jiang, H., Zhang, Z., Chen, L., Wang, H., Ma, Z.: IND-CCA-secure key encapsulation mechanism in the quantum random oracle model, revisited. In: Shacham, H., Boldyreva, A. (eds.) CRYPTO 2018, Part III. LNCS, vol. 10993, pp. 96–125. Springer, Heidelberg (2018). https://doi.org/10.1007/978-3-319-96878-0_4
Kiltz, E., Lyubashevsky, V., Schaffner, C.: A concrete treatment of Fiat-Shamir signatures in the quantum random-oracle model. In: Nielsen, J.B., Rijmen, V. (eds.) EUROCRYPT 2018, Part III. LNCS, vol. 10822, pp. 552–586. Springer, Heidelberg (2018). https://doi.org/10.1007/978-3-319-78372-7_18
Kiltz, E., Pan, J., Wee, H.: Structure-preserving signatures from standard assumptions, revisited. In: Gennaro, R., Robshaw, M.J.B. (eds.) CRYPTO 2015, Part II. LNCS, vol. 9216, pp. 275–295. Springer, Heidelberg (2015). https://doi.org/10.1007/978-3-662-48000-7_14
Kuchta, V., Sakzad, A., Stehlé, D., Steinfeld, R., Sun, S.: Measure-rewind-measure: tighter quantum random oracle model proofs for one-way to hiding and CCA security. In: Canteaut, A., Ishai, Y. (eds.) EUROCRYPT 2020, Part III. LNCS, vol. 12107, pp. 703–728. Springer, Heidelberg (2020). https://doi.org/10.1007/978-3-030-45727-3_24
Lai, J., Yang, R., Huang, Z., Weng, J.: Simulation-based bi-selective opening security for public key encryption. In: Tibouchi, M., Wang, H. (eds.) ASIACRYPT 2021, Part II. LNCS, vol. 13091, pp. 456–482. Springer, Heidelberg (2021). https://doi.org/10.1007/978-3-030-92075-3_16
Lyu, L., Liu, S., Han, S., Gu, D.: Tightly SIM-SO-CCA secure public key encryption from standard assumptions. In: Abdalla, M., Dahab, R. (eds.) PKC 2018, Part I. LNCS, vol. 10769, pp. 62–92. Springer, Heidelberg (2018). https://doi.org/10.1007/978-3-319-76578-5_3
Nielsen, M.A., Chuang, I.L.: Quantum Computation and Quantum Information (10th Anniversary edition). Cambridge University Press, Cambridge (2016)
Pan, J., Wagner, B., Zeng, R.: Tighter security for generic authenticated key exchange in the QROM. In: Guo, J., Steinfeld, R. (eds.) ASIACRYPT 2023. LNCS, vol. 14441, pp. 401–433. Springer, Heidelberg (2023). https://eprint.iacr.org/2023/1380
Pan, J., Zeng, R.: Compact and tightly selective-opening secure public-key encryption schemes. In: Agrawal, S., Lin, D. (eds.) ASIACRYPT 2022, Part III. LNCS, vol. 13793, pp. 363–393. Springer, Heidelberg (2022). https://doi.org/10.1007/978-3-031-22969-5_13
Pan, J., Zeng, R.: Selective opening security in the quantum random oracle model, revisited. Cryptology ePrint Archive (2023). https://ia.cr/2023/1682
Saito, T., Xagawa, K., Yamakawa, T.: Tightly-secure key-encapsulation mechanism in the quantum random oracle model. In: Nielsen, J.B., Rijmen, V. (eds.) EUROCRYPT 2018, Part III. LNCS, vol. 10822, pp. 520–551. Springer, Heidelberg (2018). https://doi.org/10.1007/978-3-319-78372-7_17
Sato, S., Shikata, J.: SO-CCA secure PKE in the quantum random oracle model or the quantum ideal cipher model. In: Albrecht, M. (ed.) IMACC 2019. LNCS, vol. 11929, pp. 317–341. Springer, Heidelberg (2019). https://doi.org/10.1007/978-3-030-35199-1_16
Sato, S., Shikata, J.: SO-CCA secure PKE in the quantum random oracle model or the quantum ideal cipher model. Cryptology ePrint Archive, Paper 2022/617 (2022). https://eprint.iacr.org/2022/617. Accessed 21 July 2022
Schwabe, P., et al.: CRYSTALS-KYBER. Technical report, National Institute of Standards and Technology (2020). https://csrc.nist.gov/projects/post-quantum-cryptography/post-quantum-cryptography-standardization/round-3-submissions
Targhi, E.E., Unruh, D.: Post-quantum security of the Fujisaki-Okamoto and OAEP transforms. In: Hirt, M., Smith, A.D. (eds.) TCC 2016-B, Part II. LNCS, vol. 9986, pp. 192–216. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-53644-5_8
Unruh, D.: Quantum position verification in the random oracle model. In: Garay, J.A., Gennaro, R. (eds.) CRYPTO 2014, Part II. LNCS, vol. 8617, pp. 1–18. Springer, Heidelberg (2014). https://doi.org/10.1007/978-3-662-44381-1_1
Unruh, D.: Revocable quantum timed-release encryption. In: Nguyen, P.Q., Oswald, E. (eds.) EUROCRYPT 2014. LNCS, vol. 8441, pp. 129–146. Springer, Heidelberg (2014). https://doi.org/10.1007/978-3-642-55220-5_8
Yamakawa, T., Zhandry, M.: Classical vs quantum random oracles. In: Canteaut, A., Standaert, F.X. (eds.) EUROCRYPT 2021, Part II. LNCS, vol. 12697, pp. 568–597. Springer, Heidelberg (2021). https://doi.org/10.1007/978-3-030-77886-6_20
Zhandry, M.: Secure identity-based encryption in the quantum random oracle model. In: Safavi-Naini, R., Canetti, R. (eds.) CRYPTO 2012. LNCS, vol. 7417, pp. 758–775. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-32009-5_44
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendices
Supporting Material
A Review of Adaptive One-Way-to-Hiding
Let \(\mathcal{H}\mathcal{F}:= \{\{0,1\}^* \rightarrow \{0,1\}^n \}\) be a set containing all functions that have \(\{0,1\}^*\) as domain and \(\{0,1\}^n\) as codomain. Let \(\mathcal {A}= (\mathcal {A}_0, \mathcal {A}_1)\) be an adversary that has quantum access to a QRO \(\mathcal {H}\) and queries it at most \(q_0+q_1\) times. Unruh’s adaptive OW2H lemma [39, Lemma 15] can be described as follows: let

where \(q_0\), \(q_1\) are the numbers of time \(\mathcal {A}_0,\mathcal {A}_1\) queries \(\mathcal {H}\) respectively. C is an algorithm that has quantum access to \(\mathcal {H}\) and on input (j, B, x), runs \(\mathcal {A}^{\mathcal {H}}_1(x,B)\) until its j-th query, measures the QRO query in the computational basis, output the measurement outcome. Then
The bound given in this adaptive OW2H lemma includes two parts: the first part is roughly the search bound of quantum adversaries to find a uniformly random x given \(\mathcal {H}(x||m)\) (i.e., \( q_0 2^{-l/2 + 2}\)), and the second part is the advantage of \(\mathcal {A}_1\) to distinguish two QROs: \(\mathcal {H}_{(x||m)\rightarrow B}\) and \(\mathcal {H}\), where \(\mathcal {H}_{(x||m)\rightarrow B}\) is the same as \(\mathcal {H}\) except that \(\mathcal {H}_{(x||m)\rightarrow B}(x||m) = B\). Note that this advantage is described by the extracting algorithm C.
Unruh’s adaptive OW2H lemma cannot be used to prove the bound of our reprogramming framework Fig. 4 via hybrid arguments. This is because:
-
The initial oracles of \(\textsc {Ada}\) and \(\textsc {NonAda}\) in our framework are not necessarily the same. In this case, our framework considers a stronger QROM adaptive reprogramming setting than the adaptive OW2H (and the adaptive reprogramming framework in [16]).
-
Even if the initial oracles are the same, in our framework, sets \(S_i\) may not independent to each other, and thus each intermediate hybrid games in the hybrid argument may not independent. This makes it hard to modify the adaptive OW2H lemma to fit in our framework and use hybrid argument. More details will be given in our full version [33].
Rights and permissions
Copyright information
© 2024 International Association for Cryptologic Research
About this paper

Cite this paper
Pan, J., Zeng, R. (2024). Selective Opening Security in the Quantum Random Oracle Model, Revisited. In: Tang, Q., Teague, V. (eds) Public-Key Cryptography – PKC 2024. PKC 2024. Lecture Notes in Computer Science, vol 14603. Springer, Cham. https://doi.org/10.1007/978-3-031-57725-3_4
Download citation
DOI: https://doi.org/10.1007/978-3-031-57725-3_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-57724-6
Online ISBN: 978-3-031-57725-3
eBook Packages: Computer ScienceComputer Science (R0)
