
Abstract
In this paper, we propose a model-agnostic post-hoc explanation procedure devoted to computing feature attribution. The proposed method, termed Sparseness-Optimized Feature Importance (SOFI), entails solving an optimization problem related to the sparseness of feature importance explanations. The intuition behind this property is that the model’s performance is severely affected after marginalizing the most important features while remaining largely unaffected after marginalizing the least important ones. Existing post-hoc feature attribution methods do not optimize this property directly but rather implement proxies to obtain this behavior. Numerical simulations using both structured (tabular) and unstructured (image) classification datasets show the superiority of our proposal compared with state-of-the-art feature attribution explanation methods. The implementation of the method is available on https://github.com/igraugar/sofi.
G. Nápoles—Equal contribution.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
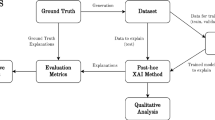


References
Bau, D., Zhou, B., Khosla, A., Oliva, A., Torralba, A.: Network dissection: quantifying interpretability of deep visual representations. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6541–6549 (2017)
Böhle, M., Eitel, F., Weygandt, M., Ritter, K.: Layer-wise relevance propagation for explaining deep neural network decisions in MRI-based Alzheimer’s disease classification. Front. Aging Neurosci. 11, 194 (2019)
Breiman, L.: Random forests. Mach. Learn. 45, 5–32 (2001)
Deb, K., Pratap, A., Agarwal, S., Meyarivan, T.: A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 6(2), 182–197 (2002)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255. IEEE (2009)
Fisher, A., Rudin, C., Dominici, F.: All models are wrong, but many are useful: learning a variable’s importance by studying an entire class of prediction models simultaneously. J. Mach. Learn. Res. 20(177), 1–81 (2019)
Gad, A.F.: PyGAD: an intuitive genetic algorithm Python library. Multimed. Tools Appl. 83, 58029–58042 (2024)
Ghorbani, A., Abid, A., Zou, J.: Interpretation of neural networks is fragile. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 3681–3688 (2019)
Grau, I., Nápoles, G., Bello, M., Salgueiro, Y., Jastrzebska, A.: Forward composition propagation for explainable neural reasoning. IEEE Comput. Intell. Mag. 19(1), 26–35 (2024)
He, J., et al.: PartImageNet: a large, high-quality dataset of parts. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) European Conference on Computer Vision, vol. 13668, pp. 128–145. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-20074-8_8
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Kirillov, A., et al.: Segment anything (2023)
Lundberg, S.M., Lee, S.I.: A unified approach to interpreting model predictions. In: Guyon, I., et al. (eds.) Advances in Neural Information Processing Systems, vol. 30, pp. 4765–4774. Curran Associates, Inc. (2017)
Miller, G.A.: The magical number seven, plus or minus two: some limits on our capacity for processing information. Psychol. Rev. 63(2), 81 (1956)
Molnar, C.: Interpretable Machine Learning, 2 edn. Leanpub (2022)
Montavon, G., Binder, A., Lapuschkin, S., Samek, W., Müller, K.-R.: Layer-wise relevance propagation: an overview. In: Samek, W., Montavon, G., Vedaldi, A., Hansen, L.K., Müller, K.-R. (eds.) Explainable AI: Interpreting, Explaining and Visualizing Deep Learning. LNCS (LNAI), vol. 11700, pp. 193–209. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-28954-6_10
Mu, J., Andreas, J.: Compositional explanations of neurons. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Curran Associates Inc. (2020)
Nauta, M., et al.: From anecdotal evidence to quantitative evaluation methods: a systematic review on evaluating explainable AI. ACM Comput. Surv. 55(13s), 1–42 (2023)
Petsiuk, V., Das, A., Saenko, K.: RISE: randomized input sampling for explanation of black-box models. arXiv preprint arXiv:1806.07421 (2018)
Ribeiro, M.T., Singh, S., Guestrin, C.: “Why should I trust you?” Explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1135–1144 (2016)
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad-CAM: visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 128(2), 336–359 (2019). https://doi.org/10.1007/s11263-019-01228-7
Shrikumar, A., Greenside, P., Shcherbina, A., Kundaje, A.: Not just a black box: learning important features through propagating activation differences. arXiv preprint arXiv:1605.01713 (2016)
Simonyan, K., Vedaldi, A., Zisserman, A.: Deep inside convolutional networks: visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034 (2013)
Slack, D., Hilgard, S., Jia, E., Singh, S., Lakkaraju, H.: Fooling LIME and SHAP: adversarial attacks on post hoc explanation methods. In: Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, pp. 180–186 (2020)
Smilkov, D., Thorat, N., Kim, B., Viégas, F., Wattenberg, M.: SmoothGrad: removing noise by adding noise. arXiv preprint arXiv:1706.03825 (2017)
Sundararajan, M., Taly, A., Yan, Q.: Axiomatic attribution for deep networks. In: International Conference on Machine Learning, pp. 3319–3328. PMLR (2017)
Acknowledgments
This paper is partially supported by the European Union’s HORIZON Research and Innovation Programme under grant agreement No 101120657, project ENFIELD (European Lighthouse to Manifest Trustworthy and Green AI).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Ethics declarations
Disclosure of Interests
All authors declare that they have no conflicts of interest.
Appendix
Appendix

Incremental blurring of segments and the effect on the probability of detecting the correct class gordon setter, for different feature rakings: a) SOFI, b) SHAP, c) Grad-CAM, d) RISE and e) a random baseline. The incremental blurring process is represented vertically from the top to the bottom of the figure.

Incremental blurring of segments and the effect on the probability of detecting the correct class chow, for different feature rakings: a) SOFI, b) SHAP, c) Grad-CAM, d) RISE and e) a random baseline. The incremental blurring process is represented vertically from the top to the bottom of the figure.

Incremental blurring of segments and the effect on the probability of detecting the correct class mink, for different feature rakings: a) SOFI, b) SHAP, c) Grad-CAM, d) RISE and e) a random baseline. The incremental blurring process is represented vertically from the top to the bottom of the figure.
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Grau, I., Nápoles, G. (2024). Sparseness-Optimized Feature Importance. In: Longo, L., Lapuschkin, S., Seifert, C. (eds) Explainable Artificial Intelligence. xAI 2024. Communications in Computer and Information Science, vol 2154. Springer, Cham. https://doi.org/10.1007/978-3-031-63797-1_20
Download citation
DOI: https://doi.org/10.1007/978-3-031-63797-1_20
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-63796-4
Online ISBN: 978-3-031-63797-1
eBook Packages: Computer ScienceComputer Science (R0)