
Abstract
The calibration of predictive distributions has been widely studied in deep learning, but the same cannot be said about the more specific epistemic uncertainty as produced by Deep Ensembles, Bayesian Deep Networks, or Evidential Deep Networks. Although measurable, this form of uncertainty is difficult to calibrate on an objective basis as it depends on the prior for which a variety of choices exist. Nevertheless, epistemic uncertainty must in all cases satisfy two formal requirements: firstly, it must decrease when the training dataset gets larger and, secondly, it must increase when the model expressiveness grows. Despite these expectations, our experimental study shows that on several reference datasets and models, measures of epistemic uncertainty violate these requirements, sometimes presenting trends completely opposite to those expected. These paradoxes between expectation and reality raise the question of the true utility of epistemic uncertainty as estimated by these models. A formal argument suggests that this disagreement is due to a poor approximation of the posterior distribution rather than to a flaw in the measure itself. Based on this observation, we propose a regularization function for deep ensembles, called conflictual loss in line with the above requirements. We emphasize its strengths by showing experimentally that it fulfills both requirements of epistemic uncertainty, without sacrificing either the performance nor the calibration of the deep ensembles.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

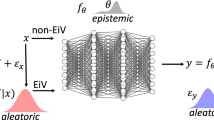

Notes
- 1.
Code available at: https://github.com/fellajimed/Conflictual-Loss.
References
Bengs, V., Hüllermeier, E., Waegeman, W.: Pitfalls of epistemic uncertainty quantification through loss minimisation. In: Oh, A.H., Agarwal, A., Belgrave, D., Cho, K. (eds.) Advances in Neural Information Processing Systems (2022). https://openreview.net/forum?id=epjxT_ARZW5
de Mathelin, A., Deheeger, F., Mougeot, M., Vayatis, N.: Deep anti-regularized ensembles provide reliable out-of-distribution uncertainty quantification, April 2023
de Mathelin, A., Deheeger, F., Mougeot, M., Vayatis, N.: Maximum weight entropy, September 2023
Depeweg, S., Hernandez-Lobato, J.M., Doshi-Velez, F., Udluft, S.: Decomposition of uncertainty in Bayesian deep learning for efficient and risk-sensitive learning. In: Proceedings of the 35th International Conference on Machine Learning, July 2018, pp. 1184–1193. PMLR (2018). ISSN 2640-3498. https://proceedings.mlr.press/v80/depeweg18a.html
Fortuin, V.: Priors in Bayesian deep learning: a review. Int. Stat. Rev. 90(3), 563–591 (2022). https://doi.org/10.1111/insr.12502. https://onlinelibrary.wiley.com/doi/abs/10.1111/insr.12502
Gal, Y., Ghahramani, Z.: Dropout as a Bayesian approximation: representing model uncertainty in deep learning. In: International Conference on Machine Learning, June 2016, pp. 1050–1059 (2016). http://proceedings.mlr.press/v48/gal16.html
Gal, Y., Islam, R., Ghahramani, Z.: Deep Bayesian active learning with image data. In: Proceedings of the 34th International Conference on Machine Learning, July 2017, pp. 1183–1192. PMLR (2017). ISSN 2640-3498. https://proceedings.mlr.press/v70/gal17a.html
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neural networks. In: International Conference on Machine Learning, pp. 1321–1330. PMLR (2017)
Hinton, G.E., Camp, D.: Keeping the neural networks simple by minimizing the description length of the weights. In: Pitt, L. (ed.) Proceedings of the Sixth Annual ACM Conference on Computational Learning Theory, COLT 1993, Santa Cruz, CA, USA, 26–28 July 1993, pp. 5–13. ACM (1993). https://doi.org/10.1145/168304.168306
Huang, Z., Lam, H., Zhang, H.: Efficient uncertainty quantification and reduction for over-parameterized neural networks. In: Thirty-seventh Conference on Neural Information Processing Systems (2023). https://openreview.net/forum?id=6vnwhzRinw
Jeffreys, H.: An invariant form for the prior probability in estimation problems. Proc. R. Soc. Lond. Ser. A Math. Phys. Sci. 186(1007), 453–461 (1946). http://www.jstor.org/stable/97883
Kirsch, A., Mukhoti, J., van Amersfoort, J., Torr, P.H.S., Gal, Y.: On pitfalls in OoD detection: entropy considered harmful. In: Uncertainty & Robustness in Deep Learning Workshop. ICML (2021)
Kuleshov, V., Fenner, N., Ermon, S.: Accurate uncertainties for deep learning using calibrated regression. In: Proceedings of the 35th International Conference on Machine Learning, July 2018, pp. 2796–2804. PMLR (2018). ISSN 2640-3498. https://proceedings.mlr.press/v80/kuleshov18a.html
Lakshminarayanan, B., Pritzel, A., Blundell, C.: Simple and scalable predictive uncertainty estimation using deep ensembles. In: Advances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc. (2017). https://proceedings.neurips.cc/paper/2017/hash/9ef2ed4b7fd2c810847ffa5fa85bce38-Abstract.html
Lee, K., Lee, H., Lee, K., Shin, J.: Training confidence-calibrated classifiers for detecting out-of-distribution samples. In: 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018, Conference Track Proceedings. OpenReview.net (2018). https://openreview.net/forum?id=ryiAv2xAZ
MacKay, D.J.C.: A practical Bayesian framework for backpropagation networks. Neural Comput. 4(3), 448–472 (1992). https://doi.org/10.1162/neco.1992.4.3.448. https://direct.mit.edu/neco/article/4/3/448-472/5654
Malinin, A., Gales, M.: Predictive uncertainty estimation via prior networks. In: Advances in Neural Information Processing Systems, vol. 31. Curran Associates, Inc. (2018). https://proceedings.neurips.cc/paper/2018/hash/3ea2db50e62ceefceaf70a9d9a56a6f4-Abstract.html
Malinin, A., Ragni, A., Knill, K., Gales, M.: Incorporating uncertainty into deep learning for spoken language assessment. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), July 2017, pp. 45–50. Association for Computational Linguistics, Vancouver, Canada (2017), https://doi.org/10.18653/v1/P17-2008. https://aclanthology.org/P17-2008
Meister, C., Salesky, E., Cotterell, R.: Generalized entropy regularization or: there’s nothing special about label smoothing. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, July 2020, pp. 6870–6886. Association for Computational Linguistics (2020). https://doi.org/10.18653/v1/2020.acl-main.615. https://aclanthology.org/2020.acl-main.615
Mucsányi, B., Kirchhof, M., Oh, S.J.: Benchmarking uncertainty disentanglement: specialized uncertainties for specialized tasks (2024)
Neal, R.M.: Bayesian Learning for Neural Networks, Lecture Notes in Statistics, vol. 118. Springer New York, New York, NY (1996). https://doi.org/10.1007/978-1-4612-0745-0. http://link.springer.com/10.1007/978-1-4612-0745-0
Nixon, J., Dusenberry, M.W., Zhang, L., Jerfel, G., Tran, D.: Measuring calibration in deep learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2019 (2019)
Ovadia, Y., et al.: Can you trust your model’s uncertainty? Evaluating predictive uncertainty under dataset shift. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Curran Associates Inc., Red Hook, NY, USA (2019)
Pakdaman Naeini, M., Cooper, G., Hauskrecht, M.: Obtaining well calibrated probabilities using Bayesian binning. Proc. AAAI Conf. Artif. Intell. 29(1) (2015). https://doi.org/10.1609/aaai.v29i1.9602. https://ojs.aaai.org/index.php/AAAI/article/view/9602
Pereyra, G., Tucker, G., Chorowski, J., Kaiser, L., Hinton, G.E.: Regularizing neural networks by penalizing confident output distributions. In: 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017, Workshop Track Proceedings. OpenReview.net (2017). https://openreview.net/forum?id=HyhbYrGYe
Ren, J., et al.: Likelihood ratios for out-of-distribution detection. In: Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R. (eds.) Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, 8–14 December 2019, Vancouver, BC, Canada, pp. 14680–14691 (2019)
Sensoy, M., Kaplan, L.M., Kandemir, M.: Evidential deep learning to quantify classification uncertainty. In: Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R. (eds.) Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, 3–8 December 2018, Montréal, Canada, pp. 3183–3193 (2018). https://proceedings.neurips.cc/paper/2018/hash/a981f2b708044d6fb4a71a1463242520-Abstract.html
Silva, F.L.D., Hernandez-Leal, P., Kartal, B., Taylor, M.E.: Uncertainty-aware action advising for deep reinforcement learning agents. Proc. AAAI Conf. Artif. Intell. 34(04), 5792–5799 (2020). https://doi.org/10.1609/aaai.v34i04.6036. https://ojs.aaai.org/index.php/AAAI/article/view/6036
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2818–2826 (2016)
Tsiligkaridis, T.: Information aware max-norm Dirichlet networks for predictive uncertainty estimation. Neural Netw. 135, 105–114 (2021)
Wimmer, L., Sale, Y., Hofman, P., Bischl, B., Hüllermeier, E.: Quantifying aleatoric and epistemic uncertainty in machine learning: are conditional entropy and mutual information appropriate measures? In: Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, July 2023, pp. 2282–2292. PMLR (2023). ISSN 2640-3498. https://proceedings.mlr.press/v216/wimmer23a.html
Yao, J., Pan, W., Ghosh, S., Doshi-Velez, F.: Quality of uncertainty quantification for bayesian neural network inference, June 2019.https://doi.org/10.48550/arXiv.1906.09686. arXiv arXiv:1906.09686 [cs, stat]
Zadrozny, B., Elkan, C.: Obtaining calibrated probability estimates from decision trees and Naive Bayesian classifiers. In: Proceedings of the Eighteenth International Conference on Machine Learning, ICML 2001, pp. 609-616. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA (2001)
Zadrozny, B., Elkan, C.: Transforming classifier scores into accurate multiclass probability estimates. In: Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD 2002, pp. 694-699. Association for Computing Machinery, New York, NY, USA (2002). https://doi.org/10.1145/775047.775151
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Ethics declarations
Disclosure of Interests
The authors have no competing interests to declare that are relevant to the content of this article.
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Fellaji, M., Pennerath, F., Conan-Guez, B., Couceiro, M. (2024). On the Calibration of Epistemic Uncertainty: Principles, Paradoxes and Conflictual Loss. In: Bifet, A., Davis, J., Krilavičius, T., Kull, M., Ntoutsi, E., Žliobaitė, I. (eds) Machine Learning and Knowledge Discovery in Databases. Research Track. ECML PKDD 2024. Lecture Notes in Computer Science(), vol 14944. Springer, Cham. https://doi.org/10.1007/978-3-031-70359-1_10
Download citation
DOI: https://doi.org/10.1007/978-3-031-70359-1_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-70358-4
Online ISBN: 978-3-031-70359-1
eBook Packages: Computer ScienceComputer Science (R0)
