
Abstract
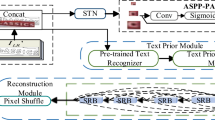
Scene text image super-resolution (STISR) aims to enhance low-resolution text images, boosting downstream text recognition tasks. Recent STISR models leverage text recognizer for prior information, achieving superior performance via a novel strategy. However, we observe abundant erroneous prior information from the low-resolution (LR) text images processed by the text recognizer, which can mislead text reconstruction when fused with image features. Therefore, we propose a novel sequential residual blocks, termed sequence refinement blocks, to refine the merged features of text images and text priors during the reconstruction of LR images. Additionally, regarding the widespread problem of ignoring the contextual semantic information in the shallow features of text images in the STISR, We introduce a multi-scale feature module to supplement the fine-grained and coarse-grained information required in the reconstruction of LR text images, which can well resolve information loss and generate more accurate super-resolution text images. Our proposed method consistently outperforms baselines employing text recognizers ASTER, MORAN, and CRNN by 1–2\(\%\) on TextZoom, and achieves impressive gains of 4–5\(\%\) on the challenging hard subset when leveraging multi-modal recognizers like ABINet and MATRN. The generalization experiments on scene text recognition datasets demonstrate optimal 5–8\(\%\) performance improvements over the baselines.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Bautista, D., Atienza, R.: Scene text recognition with permuted autoregressive sequence models. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) ECCV 2022. LNCS, vol. 13688, pp. 178–196. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19815-1_11
Chen, J., Li, B., Xue, X.: Scene text telescope: text-focused scene image super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12026–12035 (2021)
Chen, J., Yu, H., Ma, J., Li, B., Xue, X.: Text gestalt: stroke-aware scene text image super-resolution. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 285–293 (2022)
Chng, C.K., et al.: ICDAR2019 robust reading challenge on arbitrary-shaped text-rrc-art. In: 2019 International Conference on Document Analysis and Recognition (ICDAR), pp. 1571–1576. IEEE (2019)
Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38(2), 295–307 (2015)
Fang, C., Zhu, Y., Liao, L., Ling, X.: TSRGAN: real-world text image super-resolution based on adversarial learning and triplet attention. Neurocomputing 455, 88–96 (2021)
Fang, S., Xie, H., Wang, Y., Mao, Z., Zhang, Y.: Read like humans: autonomous, bidirectional and iterative language modeling for scene text recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7098–7107 (2021)
Guan, T., Shen, W., Yang, X., Feng, Q., Jiang, Z., Yang, X.: Self-supervised character-to-character distillation for text recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 19473–19484 (2023)
Guo, H., Dai, T., Meng, G., Xia, S.T.: Towards robust scene text image super-resolution via explicit location enhancement. In: Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23, pp. 782–790. International Joint Conferences on Artificial Intelligence Organization (2023). https://doi.org/10.24963/ijcai.2023/87, main Track
He, P., Huang, W., Qiao, Y., Loy, C., Tang, X.: Reading scene text in deep convolutional sequences. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 30 (2016)
Huang, M., et al.: Swintextspotter: scene text spotting via better synergy between text detection and text recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4593–4603 (2022)
Jaderberg, M., Simonyan, K., Vedaldi, A., Zisserman, A.: Reading text in the wild with convolutional neural networks. Int. J. Comput. Vision 116, 1–20 (2016)
Jaderberg, M., Simonyan, K., Zisserman, A., et al.: Spatial transformer networks. In: Advances in Neural Information Processing Systems, vol. 28 (2015)
Karatzas, D., et al.: ICDAR 2015 competition on robust reading. In: 2015 13th International Conference on Document Analysis and Recognition (ICDAR), pp. 1156–1160. IEEE (2015)
Kim, J., Lee, J.K., Lee, K.M.: Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1646–1654 (2016)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Lai, W.S., Huang, J.B., Ahuja, N., Yang, M.H.: Deep Laplacian pyramid networks for fast and accurate super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 624–632 (2017)
Leal-Taixé, L., Roth, S.: Computer Vision–ECCV 2018 Workshops, Part VI, vol. 11134. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-01267-0
Ledig, C., et al.: Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4681–4690 (2017)
Li, J., Wen, Y., He, L.: SCCONV: spatial and channel reconstruction convolution for feature redundancy. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6153–6162 (2023)
Li, M., et al.: TROCR: transformer-based optical character recognition with pre-trained models. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, pp. 13094–13102 (2023)
Lim, B., Son, S., Kim, H., Nah, S., Mu Lee, K.: Enhanced deep residual networks for single image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 136–144 (2017)
Liu, B., et al.: Textdiff: mask-guided residual diffusion models for scene text image super-resolution. arXiv preprint arXiv:2308.06743 (2023)
Liu, Y., et al.: Spts v2: single-point scene text spotting. arXiv preprint arXiv:2301.01635 (2023)
Luo, C., Jin, L., Sun, Z.: Moran: a multi-object rectified attention network for scene text recognition. Pattern Recogn. 90, 109–118 (2019)
Ma, J., Guo, S., Zhang, L.: Text prior guided scene text image super-resolution. IEEE Trans. Image Process. 32, 1341–1353 (2023)
Ma, J., Liang, Z., Zhang, L.: A text attention network for spatial deformation robust scene text image super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5911–5920 (2022)
Mishra, A., Alahari, K., Jawahar, C.: Scene text recognition using higher order language priors. In: BMVC-British Machine Vision Conference. BMVA (2012)
Mou, Y., et al.: PlugNet: degradation aware scene text recognition supervised by a pluggable super-resolution unit. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020, Part XV. LNCS, vol. 12360, pp. 158–174. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58555-6_10
Na, B., Kim, Y., Park, S.: Multi-modal text recognition networks: interactive enhancements between visual and semantic features. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) ECCV 2022. LNCS, vol. 13688, pp. 446–463. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19815-1_26
Nayef, N., et al.: ICDAR2019 robust reading challenge on multi-lingual scene text detection and recognition-RRC-MLT-2019. In: 2019 International Conference on Document Analysis and Recognition (ICDAR), pp. 1582–1587. IEEE (2019)
Phan, T.Q., Shivakumara, P., Tian, S., Tan, C.L.: Recognizing text with perspective distortion in natural scenes. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 569–576 (2013)
Ronen, R., Tsiper, S., Anschel, O., Lavi, I., Markovitz, A., Manmatha, R.: Glass: global to local attention for scene-text spotting. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) ECCV 2022. LNCS, vol. 13688, pp. 249–266. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19815-1_15
Shi, B., Bai, X., Yao, C.: An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 39(11), 2298–2304 (2016)
Shi, B., Yang, M., Wang, X., Lyu, P., Yao, C., Bai, X.: Aster: an attentional scene text recognizer with flexible rectification. IEEE Trans. Pattern Anal. Mach. Intell. 41(9), 2035–2048 (2018)
Shi, B., et al.: ICDAR2017 competition on reading Chinese text in the wild (RCTW-17). In: 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), vol. 1, pp. 1429–1434. IEEE (2017)
Song, S., et al.: Vision-language pre-training for boosting scene text detectors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15681–15691 (2022)
Wang, K., Babenko, B., Belongie, S.: End-to-end scene text recognition. In: 2011 International Conference on Computer Vision, pp. 1457–1464. IEEE (2011)
Wang, K., et al.: Masked text modeling: a self-supervised pre-training method for scene text detection. In: Proceedings of the 31st ACM International Conference on Multimedia, pp. 2006–2015 (2023)
Vedaldi, A., et al.: Scene text image super-resolution in the wild. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12355, pp. 650–666. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58607-2_38
Wang, X., et al.: ESRGAN: enhanced super-resolution generative adversarial networks. In: Leal-Taixé, L., Roth, S. (eds.) ECCV 2018. LNCS, vol. 11133, pp. 63–79. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-11021-5_5
Yu, W., Liu, Y., Hua, W., Jiang, D., Ren, B., Bai, X.: Turning a clip model into a scene text detector. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6978–6988 (2023)
Zhang, Y., Tian, Y., Kong, Y., Zhong, B., Fu, Y.: Residual dense network for image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2472–2481 (2018)
Zhao, C., et al.: Scene text image super-resolution via parallelly contextual attention network. In: Proceedings of the 29th ACM International Conference on Multimedia, pp. 2908–2917 (2021)
Zhao, M., Wang, M., Bai, F., Li, B., Wang, J., Zhou, S.: C3-STISR: scene text image super-resolution with triple clues. In: IJCAI, pp. 1707–1713 (2022)
Zhao, X., Zhang, L., Pang, Y., Lu, H., Zhang, L.: A single stream network for robust and real-time RGB-D salient object detection. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12367, pp. 646–662. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58542-6_39
Zhu, S., Zhao, Z., Fang, P., Xue, H.: Improving scene text image super-resolution via dual prior modulation network. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 3843–3851 (2023)
Acknowledgement
This work was supported by the following projects.
The National Natural Science Foundation of China (No. 62166043, U2003207).
Tianshan Talent Training Project-Xinjiang Science and Technology Innovation Team Program (2023TSYCTD0012).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Yang, W., Luo, Y., Ibrayim, M., Hamdulla, A. (2024). More and Less: Enhancing Abundance and Refining Redundancy for Text-Prior-Guided Scene Text Image Super-Resolution. In: Barney Smith, E.H., Liwicki, M., Peng, L. (eds) Document Analysis and Recognition - ICDAR 2024. ICDAR 2024. Lecture Notes in Computer Science, vol 14808. Springer, Cham. https://doi.org/10.1007/978-3-031-70549-6_8
Download citation
DOI: https://doi.org/10.1007/978-3-031-70549-6_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-70548-9
Online ISBN: 978-3-031-70549-6
eBook Packages: Computer ScienceComputer Science (R0)
