
Abstract
Large language models have been used to translate natural language questions to SQL queries. Without hard constraints on syntax and database schema, they occasionally produce invalid queries that are not executable. These failures limit the usage of these systems in real-life scenarios. We propose a neurosymbolic framework that imposes SQL syntax and schema constraints with unification-based definite clause grammars and thus guarantees the generation of valid queries. Our framework also builds a bi-directional interface to language models to leverage their natural language understanding abilities. The evaluation results on a subset of SQL grammars show that all our output queries are valid. This work is the first step towards extending language models with unification-based grammars. We demonstrate this extension enhances the validity, execution accuracy, and ground truth alignment of the underlying language model by a large margin. Our code is available at https://github.com/ML-KULeuven/deepstochlog-lm.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


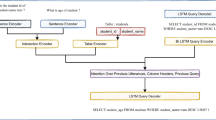
Notes
- 1.
Notice that the Prolog query is the logical goal to be proved, which differs from the SQL query to generate.
References
Achiam, J., et al.: GPT-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
Almazrouei, E., et al.: Falcon-40B: an open large language model with state-of-the-art performance (2023)
Chase, H.: LangChain (2022). https://github.com/langchain-ai/langchain
Choi, D., Shin, M., Kim, E., Shin, D.: RYANSQL: recursively applying sketch-based slot fillings for complex text-to-SQL in cross-domain databases. Comput. Linguist. 47(2), 309–332 (2021)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186 (2019)
Dong, X., et al.: C3: Zero-shot text-to-SQL with ChatGpt. arXiv preprint arXiv:2307.07306 (2023)
Gao, D., et al.: Text-to-SQL empowered by large language models: a benchmark evaluation. arXiv preprint arXiv:2308.15363 (2023)
Guo, J., et al.: towards complex text-to-SQL in cross-domain database with intermediate representation. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4524–4535 (2019)
Kimmig, A., Van den Broeck, G., De Raedt, L.: An algebraic prolog for reasoning about possible worlds. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 25, pp. 209–214 (2011)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Lewis, P., et al.: Retrieval-augmented generation for knowledge-intensive NLP tasks. Adv. Neural. Inf. Process. Syst. 33, 9459–9474 (2020)
Li, H., Zhang, J., Li, C., Chen, H.: ResdSQL: decoupling schema linking and skeleton parsing for text-to-SQL. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, pp. 13067–13075 (2023)
Li, J., et al.: Graphix-t5: mixing pre-trained transformers with graph-aware layers for text-to-SQL parsing. In: Proceedings of the AAAI Conference on Artificial Intelligence, p. 13076–13084 (2023)
Lin, K., Bogin, B., Neumann, M., Berant, J., Gardner, M.: Grammar-based neural text-to-SQL generation. arXiv preprint arXiv:1905.13326 (2019)
Liu, J.: LlamaIndex (2022). https://doi.org/10.5281/zenodo.1234, https://github.com/jerryjliu/llama_index
Pereira, F.C., Warren, D.H.: Definite clause grammars for language analysis-a survey of the formalism and a comparison with augmented transition networks. Artif. Intell. 13(3), 231–278 (1980)
Poesia, G., et al.: Synchromesh: reliable code generation from pre-trained language models. arXiv preprint arXiv:2201.11227 (2022)
Pourreza, M., Rafiei, D.: DIN-SQL: decomposed in-context learning of text-to-SQL with self-correction. In: Advances in Neural Information Processing Systems, vol. 36 (2024)
Raffel, C., et al.: Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 21(140), 1–67 (2020)
Scholak, T., Schucher, N., Bahdanau, D.: Picard: parsing incrementally for constrained auto-regressive decoding from language models. In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 9895–9901 (2021)
Shaw, P., Chang, M.W., Pasupat, P., Toutanova, K.: Compositional generalization and natural language variation: can a semantic parsing approach handle both? In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 922–938 (2021)
Suhr, A., Chang, M.W., Shaw, P., Lee, K.: Exploring unexplored generalization challenges for cross-database semantic parsing. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 8372–8388 (2020)
Taori, R., et al.: Stanford alpaca: an instruction-following llama model (2023). https://github.com/tatsu-lab/stanford_alpaca
Touvron, H., et al.: LLaMA: open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
Wang, B., Shin, R., Liu, X., Polozov, O., Richardson, M.: RAT-SQL: relation-aware schema encoding and linking for text-to-SQL parsers. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 7567–7578 (2020)
Wang, C., et al.: Robust text-to-SQL generation with execution-guided decoding. arXiv preprint arXiv:1807.03100 (2018)
Winters, T., Marra, G., Manhaeve, R., De Raedt, L.: DeepStochLog: neural stochastic logic programming. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 10090–10100 (2022)
Wolf, T., et al.: Transformers: state-of-the-art natural language processing. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 38–45 (2020)
Xu, X., Liu, C., Song, D.: SQLnet: generating structured queries from natural language without reinforcement learning. arXiv preprint arXiv:1711.04436 (2017)
Yin, P., Neubig, G.: A syntactic neural model for general-purpose code generation. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 440–450 (2017)
Yin, P., Neubig, G.: TRANX: a transition-based neural abstract syntax parser for semantic parsing and code generation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (Demo Track) (2018)
Yu, T., Li, Z., Zhang, Z., Zhang, R., Radev, D.: TypeSQL: knowledge-based type-aware neural text-to-sql generation. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) (2018)
Yu, T., et al.: Syntaxsqlnet: Syntax tree networks for complex and cross-domain text-to-sql task. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 1653–1663 (2018)
Yu, T., et al.: Spider: a large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 3911–3921 (2018)
Acknowledgments
This project has received funding from the European Union’s Horizon Europe research and innovation programme under the Marie Skłodowska-Curie grant agreement No 101073307 and the Flemish Government (AI Research Program). Luc De Raedt is also supported by the Wallenberg AI, Autonomous Systems and Software Program (WASP) funded by the Knut and Alice Wallenberg Foundation. We thank Thomas Winters for the helpful discussions. We also thank the anonymous reviewers for their valuable feedback.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendices
A Task 1
1.1 A.1 Logic Program
Task 1 grammar is modeled as follows:

1.2 A.2 Training and Evaluation
We train settings 1 and 2 end-to-end for 7 epochs using the Adam optimizer [10] with a batch size of 8 and a learning rate of \(1e^{-3}\). For evaluation, we employ DeepStochLog inference with the \((\max , \times )\) semiring, i.e. the exact inference. Examples of \(column\_lm\) and \(selection\_lm\) inputs are listed in Table 7. The inputs of \(table\_lm\) have the same format as those of \(column\_lm\).
Pre- and Post-processing. In pre-processing, we tokenize the ground truth SQL queries to sequences with list format. Table and column identifiers in the sequences are replaced by their semantic names [12]. The semantics names provided in Spider [34] are closer to natural expressions, which facilitate the understanding of language models. This replacement is also conducted for the facts in logic programs. After generation, we restore the identifiers in the output sequence to their original names and join the sequence to get the SQL query. This pre- and post-progressing are also performed in task 2 experiments.
B Task 2
1.1 B.1 Logic Program
Task 2 grammar covers two types of queries: 1) single selection and 2) two selections connected by the set operator “EXCEPT". The grammar for single-selection queries covers the “SELECT", “WHERE", “GROUP BY", and “ORDER BY" clauses including “DISTINCT" and aggregation functions in the “SELECT" clause, “HAVING" in the “GROUP BY" clause, and “ASC / DESC" and “LIMIT" in the “ORDER BY" clause. “WHERE" and “HAVING" allow one condition. For type 2), the two selection clauses have the format “SELECT [column] FROM [table]". The columns in the two selection clauses are currently restricted to foreign keys linking the two tables. Task 2 grammar is modeled as follows:

1.2 B.2 Underlying Language Models
We employ 11 fine-tuned T5-small models. All models used in this work are from Huggingface [28].
\(table\_lm\) and \(column\_lm\) provide the probability distribution over the given table and column domain respectively. Their output domains vary with the database. The output domain of other language models is fixed. \(except\_lm\), \(where\_lm\), \(groupby\_lm\), \(having\_lm\), \(order\_lm\), \(desc\_lm\), \(limit\_lm\) are used to produce the probability distribution on the existence of the corresponding SQL clause. \(selection\_lm\) provides the probability distribution over 10 possible selection branches. \(operator\_lm\) outputs the probability distribution over possible operators in “WHERE" and “HAVING" conditions. For the queries with two selection clauses connected by “EXCEPT", we call \(table\_lm\) twice to get probability distributions over the possible substitutions for the table in each selection clause. The pair of columns in each selection clause are decided deterministically based on the pair of tables. Our current framework does not predict any value in SQL conditions. We assume the gold values are given. When we predict wrong conditions that cannot be mapped to the gold values, we assign the values to 1.
\(table\_lm\), \(column\_lm\), and \(opertor\_lm\) can be used at different positions. \(table\_lm\) can be called twice for the selection clause before “EXCEPT" and the one after “EXCEPT". \(column\_lm\) is used for the column in the “SELECT", “WHERE", “GROUP BY" and “ORDER BY" clauses. \(operator\_lm\) is used for operators in “WHERE" and “HAVING" conditions. We add states in their inputs to help them distinguish different cases. Examples of \(column\_lm\) inputs are shown in Table 7 to showcase the inputs with states. We also include examples of \(where\_lm\) and \(selection\_lm\) inputs in Table 7. \(except\_lm\), \(where\_lm\), \(groupby\_lm\), \(having\_lm\), \(order\_lm\), \(desc\_lm\), \(limit\_lm\) shares a similar input format as \(where\_lm\).
1.3 B.3 Training and Evaluation
In the text-to-SQL task, the grammar can always be written unambiguously, which leads to only one possible derivation for the ground-truth query Q. With the negative log-likelihood loss function and all positive samples in dataset \(\mathcal {D}\) (target probability \(t_i\)=1.0),
As all the intermediate goals are observable given Q, the learning problem collapses to supervised training.
We fine-tune the T5-small models using the Adam optimizer. Table 6 shows the number of fine-tuning epochs, the batch size, and the learning rate for each model. The hyper-parameters are determined with cross-validation.
In evaluation, we perform the greedy inference to speed up the inference process. Instead of considering the re-normalized distributions obtained from the language models, the greedy inference takes the substitution with the largest probability.
C Baselines
We fine-tune the vanilla T5-small baseline for 10 epochs using the Adam optimizer, a batch size of 32, and a learning rate \(1e^{-3}\). T5-small + CFGs shares the same language models with ours T5-small + DCGs except the \(column\_lm\). Without table unification, the domain of \(column\_lm\) used in T5-small + CFGs covers all the columns in a given database. We fine-tune a T5-small model for \(column\_lm\) in T5-small + CFGs using the Adam optimizer for 13 epochs with a batch size of 32, and a learning rate \(5e^{-4}\). Table 8 shows the example inputs for T5-small and \(column\_lm\) in T5-small + CFGs.
For the state-of-the-art models (DAIL-SQL [7], DIN-SQL [18], Graphix-T5 [13], and C3 [6]), we extract their predictions on the samples in our evaluation set from their official results for the full Spider development set [34].
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Jiao, Y., De Raedt, L., Marra, G. (2024). Valid Text-to-SQL Generation with Unification-Based DeepStochLog. In: Besold, T.R., d’Avila Garcez, A., Jimenez-Ruiz, E., Confalonieri, R., Madhyastha, P., Wagner, B. (eds) Neural-Symbolic Learning and Reasoning. NeSy 2024. Lecture Notes in Computer Science(), vol 14979. Springer, Cham. https://doi.org/10.1007/978-3-031-71167-1_17
Download citation
DOI: https://doi.org/10.1007/978-3-031-71167-1_17
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-71166-4
Online ISBN: 978-3-031-71167-1
eBook Packages: Computer ScienceComputer Science (R0)